CPU、DISK I/Oに制限がされてしまった¶
確認方法¶
Note
CPU制限時に確認すべきこと¶
ご利用VPSが収容されているホストサーバー上の負荷が上昇し
監視確認時にご利用VPSのCPUリソースの割当量がしきい値を超過していた場合
ホストサーバー上の負荷が上昇し、他収容中のVPSへの影響が出ていると判断された場合
弊社へのパフォーマンスに関する問い合わせから、お客様のご利用VPSが起因となってパフォーマンス劣化が発生していると判断された場合
1. コントロールパネルから、該当VPSのCPU利用率を確認する¶
CPUリソースをどの程度利用しているのか
CPUリソースがいつ頃から大幅に利用され始めたのか
CPUリソースの制限がいつ頃から発生するようになったのか
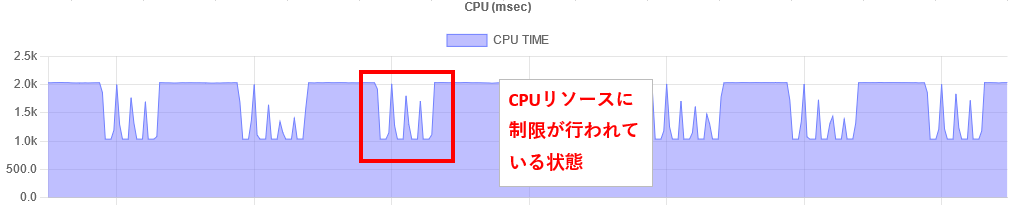
Note
警告
以下に異常とみなされる可能性のあるグラフと、通常利用と判断されるグラフを記載します。
異常なCPUリソースの利用イメージ

正常なCPUリソースの利用イメージ
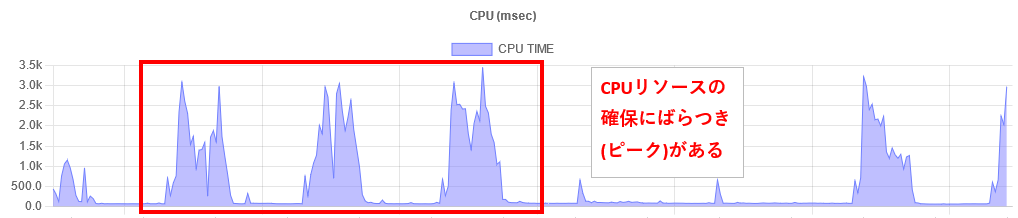
2. 何に起因してCPUリソースが上昇しているか推測する¶
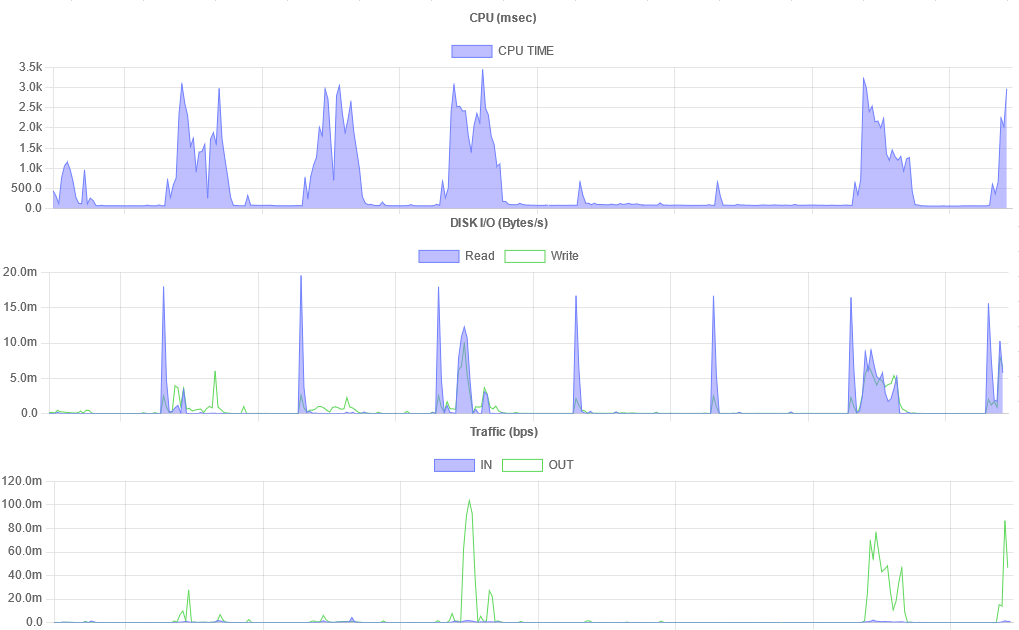
CPUリソースとTraffic(NW)の受信/送信グラフが同時期に上昇していた
・ Webサーバーへのアクセスが急激に上昇した可能性は無いか・ 外部からの攻撃やアクセス試行による可能性は無いか・ プログラムが暴走して外部へアクセスしている可能性は無いか・ 不審なプログラムが設置されている可能性は無いかCPUリソースとDISK IOの読み書きが同時期に上昇していた
・ データベースへのクエリによって、異常な DISK IO 及び CPU利用が発生している可能性は無いか。・ メモリ不足もしくはメモリリーク等によって、頻繁なスワッピングや、ページのスラッシングが発生していないか。・ バックアップ処理が重複していたり、バックアップ対象が再帰的になってしまう等で異常な DISK IO が発生していないか。
負荷を上昇させているプログラムの特定
プログラムが負荷を上昇させている原因の調査/特定
プログラムや設定ファイルの修正
Note
3. CPUリソースに影響するプログラム/動作を調査する¶
3-1. 現在の負荷状況と、対応するプロセスの確認¶
# top -i -c
-i CPUリソースを利用していないプロセスの非表示
-c 実行されているプロセス名/コマンドラインを表示
行
項目
詳細
Top
Load Average
左から 1分/5分/15分の平均負荷を表示
%Cpu(s)
us
ユーザープロセスが利用しているCPUリソースの割合(user)
---
sys
OSシステム領域が利用しているCPUリソースの割合(system)
---
id
待機(アイドル)状態のCPUリソースの割合(idle)
---
wa
CPUがI/O処理の完了待ちをしている時間の割合(wait)
---
st
何かしらの理由により、ホストからCPU時間を即座に割り当てられずに待った時間の割合(steal)
プロセス
PID
プロセスID
---
VIRT
割り当てられた仮想メモリサイズ(KiB)
---
RES
実際に使用されている物理メモリサイズ(KiB)
---
SHR
RESで利用されているメモリ中の共有メモリサイズ(KiB)
---
S
プロセスのステータス(後述)
---
%CPU
プロセスにおけるCPUリソースの利用割合
---
%MEM
プロセスにおけるメモリリソースの利用割合
ステータスコード
詳細
R
実行中もしくは実行可能状態
S
イベント完了待ち(割り込み可能)
D
イベント完了待ち(割り込み不可/ディスクへの書き込み等)
Z
ゾンビプロセス
top行でload averageを確認して負荷の程度を確認する
%Cpu(s)行から、CPUリソースの全体割合がプロセスに割り当てられているのか、システムなのか、他VPSの影響によるものかを参照する
プロセス行から、実際にどんなプロセス/コマンドラインが影響を及ぼしているか確認する(特に%CPUで判断)
3-2. 過去の負荷状況の確認¶
# dnf install sysstat
# sar ← 現在までのCPUリソース情報を10分おきに表示させる。
# sar -u ALL -P ALL 1 ← CPUコア毎に、現在の全てのリソース情報を1秒おきに表示させる。
# sar -f /var/log/sa/sa<指定日> ← 過去日(ファイル名後半の数字が日を表す)の状況を表示する。
# sar -u ALL -P ALL -f /var/log/sa/sa<指定日> ← 過去日のCPUリソースの統計情報を全て表示する。
項目 |
詳細 |
|---|---|
%irq |
CPUがハードウェア割り込みを処理するのに費やした時間の割合 |
%soft |
CPUがソフトウェア割り込みを処理するのに費やした時間の割合 |
3-3. ネットワーク負荷状況の確認¶
# sar -n DEV,EDEV 1 ← 各ネットワークデバイスの通信/エラー状況を1秒毎に表示する。
# sar -n DEV,EDEV -u ALL 1 ← CPUリソースの状況も追加して表示する。
# sar -n DEV -f /var/log/sa/sa<指定日> ← 10分単位での通信状況をログファイルから確認する。
# sar -n EDEV -f /var/log/sa/sa<指定日> ← 10分単位でのエラー状況をログファイルから確認する。
キーワード |
項目 |
詳細 |
|---|---|---|
DEV |
IFACE |
ネットワークのデバイス名 |
--- |
(r|t)xpck/s |
1秒あたりの送受信されたパケットの総数 |
--- |
(r|t)xkB/s |
1秒あたりの送受信された総通信量(キロバイト単位) |
--- |
rxmcst/s |
1秒あたりの受信マルチキャストパケット数 |
EDEV |
(r|t)xerr/s |
1秒あたりの送受信されたエラーパケットの総数 |
--- |
(r|t)xdrop/s |
1秒あたりの送受信されたドロップパケット総数 |
# dnf install iftop
# iftop -nPb -i ens3
-n 名前解決の停止
-P ポートの表示
-b グラフィカルバーの非表示
-i 実行インターフェースの指定
# dnf install lsof
# lsof -i:<対象のポート番号>
3-4. ディスク負荷状況の確認¶
# dnf install sysstat
# iostat -dmxzN 1 ← 1秒毎にデバイスの活動情報を出力する。
-d デバイス状態のレポートのみ行う(デフォルトはCPU状況も含む)
-m 出力される単位をメガバイトへ変換
-x 出力項目の拡張を行う
-z ディスクアクセスが行われているデバイスのみ表示する
-N デバイス番号ではなく、マッピングされた名前を表示する(LVMを利用している場合に有効)
項目 |
詳細 |
|---|---|
Device |
対象のデバイス名(表示項目をiostatの引数で指定することが可能) |
(r|w)/s |
読み込みor書き込みリクエストの回数 |
(r|w)MB/s |
1秒あたりの読み込みor書き込みセクタ数(メガバイト単位、オプションで指定) |
(r|w)_await |
読み込みor書き込み要求が処理されるまでの平均時間 |
(r|w)areq-sz |
読み込みor書き込み要求の平均サイズ (キロバイト単位) |
%util |
デバイスに発行された経過時間の割合 (デバイス利用率) |
# sar -d -j PATH -f /var/log/sa/sa<指定日>
# dnf install iotop
# iotop -Po
-P PID(プロセスID)の表示
-o 現時点でデバイスへのIOアクセスを行っているプロセスのみを表示
4. プログラムの修正を行う¶
グラフからCPUリソースの利用はいつからいつまで行われているのかの把握
CPUリソースは、ネットワークやディスクIOの影響によって発生したのかをグラフから予想すること
CPUリソース利用率の高いプロセスの確認方法
高CPUリソース利用がネットワークに起因する場合の、詳細特定方法
高CPUリソース利用がディスクIOに起因する場合の、詳細特定方法
Note
IOPS制限時に確認すべきこと¶
ご利用VPSが収容されているホストサーバー上の負荷が上昇し
監視確認時にご利用VPSのIOPSリソースの割当量がしきい値を超過していた場合
ホストサーバー上の負荷が上昇し、他収容中のVPSへの影響が出ていると判断された場合
弊社へのパフォーマンスに関する問い合わせから、お客様のご利用VPSが起因となってパフォーマンス劣化が発生していると判断された場合
5. コントロールパネルから、該当VPSのディスク利用率を確認する¶
DISK IOリソースをどの程度利用しているのか
DISK IOリソースがいつ頃から大幅に利用され始めたのか
DISK IOリソースの制限がいつ頃から発生するようになったのか

Note
6. IOPS制限とは具体的に何を制限しているのか¶
端末Aで実行
# dd if=/dev/zero of=/var/tmp/test oflag=direct count=20971520
※/var/tmp/testに 512byte x 20971520 = 10GBのファイルを作成します。(ddコマンドのbs値を設定しない場合、デフォルトの512byteとなります)
# dd if=/dev/zero ibs=64 of=/var/tmp/test oflag=direct count=671088640
※/var/tmp/testに 64byte x 671088640 = 10GBのファイルを作成します。(非常に遅いので、途中でCtrl+Cを入力してください)
端末Bで実行
# iostat -dmxzN 1