データ保存内容の可視化
[更新:2026年07月30日]
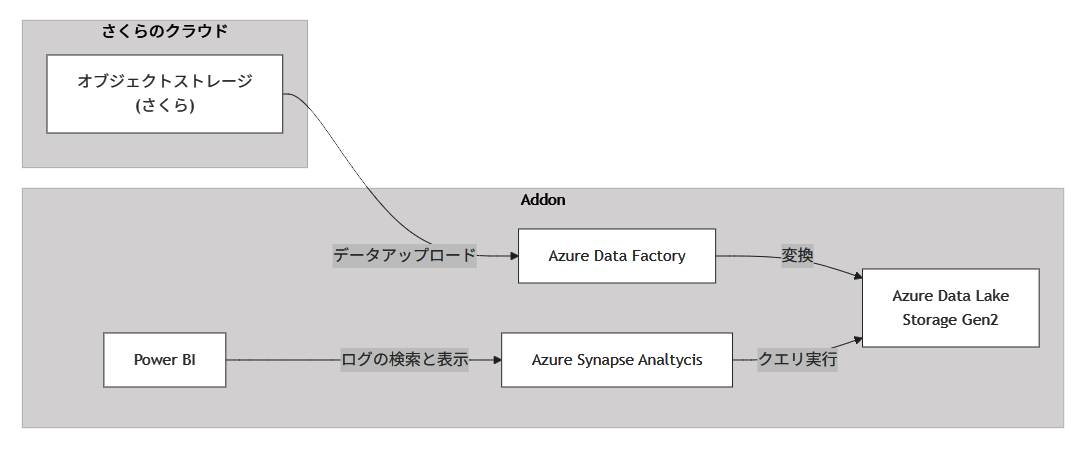
多様なデータを一元管理し、ETLで整形・統合した上でデータレイクに蓄積。専用SQLプールで高速クエリ分析を行い、BIツールで視覚的に可視化します。これにより、リアルタイムでの状況把握とデータに基づく迅速な意思決定が可能となり、業務の効率化と戦略的判断力を強化できます。
各機能のサービス対応
機能 |
対応サービス |
|---|---|
ETL/データ変換 |
Azure Data Factory |
データレイク |
Azure Data Lake Storage Gen2 |
クエリ機能 |
Azure Synapse Analytics(専用SQLプール) |
BI |
Power BI |
システム構成要素
さくらのクラウド
オブジェクトストレージ
Addon
Azure Data Factory
Azure Data Lake Storage Gen2
Azure Synapse Analytics(専用SQLプール)
Power BI
構築手順
さくらのクラウドオブジェクトストレージの事前準備
バケットの作成
さくらのクラウドのコントロールパネルにアクセスし、オブジェクトストレージからバケットを作成する

「usecase-a2-bucket」という新たなバケットを作成する

パーミッションの設定
後ほど Azure Data Factoryでオブジェクトストレージの内容を読み込むためにパーミッションを設定する

パーミッション名は「usecase-a2」を設定する

権限は「usecase-a2-bucket」の読み取りのみに設定する

作成時に表示されるアクセスキーIDとシークレットアクセスキーを記録しておく

またS3エンドポイントを利用するため、「サイト」から、「usecase-a2-bucket」のバケットを作成しているサイトのS3エンドポイントの値を確認しておく

オブジェクトストレージにデータをアップロードする
参考情報:https://manual.sakura.ad.jp/cloud/objectstorage/about.html
オブジェクトストレージにサンプルデータをアップロードします。
オブジェクトストレージの「usecase-a2-bucket」のバケットのメニューで、サンプルデータをアップロードする。

設定はprivateを選択してアップロードする

Addon でのリソース作成
データレイク機能
Addon の 「データレイク機能」API を利用して Azure Data Lake Storage Gen2 を作成する
TOKEN='<サービスプリンシパルのアクセストークン>' #POST curl -v \ --location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/datalake' \ --header 'Content-Type: application/json' \ --header 'Accept: application/json' \ --header "Authorization: Bearer $TOKEN" \ --data '{ "location": "japaneast", "performance": 1, "redundancy": 1 }'
ETL機能
Addon の 「ETL機能」API を利用して Azure Data Factory を作成する
TOKEN='<サービスプリンシパルのアクセストークン>' #POST curl -v \ --location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/etl' \ --header 'Content-Type: application/json' \ --header 'Accept: application/json' \ --header "Authorization: Bearer $TOKEN" \ --data '{ "location": "japaneast" }'
クエリ機能
Addon の 「クエリ機能」API を利用して Azure Synapse Analytics を作成する
TOKEN='<サービスプリンシパルのアクセストークン>' #POST curl -v \ --location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/query' \ --header 'Content-Type: application/json' \ --header 'Accept: application/json' \ --header "Authorization: Bearer $TOKEN" \ --data '{ "location": "japaneast" }'
RBACの設定
ユースケース構成のため、Azure Synapse Analytics、Azure Data Factory、および自身のアカウントに「ストレージBLOB共同作成者」のRBACを付与します。
データレイク機能APIで作成したAzure Data Lake Storage Gen2のアクセス制御を開く

Azure Data FactoryのマネージドIDに対して「ストレージBLOB共同作成者」を付与する

再度データレイク機能APIで作成したAzure Data Lake Storage Gen2のアクセス制御を開く
Azure Synapse AnalyticsのマネージドIDに対して「ストレージBLOB共同作成者」を付与する

再度、データレイク機能APIで作成したAzure Data Lake Storage Gen2のアクセス制御を開く
Azure Data Lake Storage Gen2のコンテナのアクセス認証をMicrosoft Entra ユーザーアカウントに切り替えるため、操作する自身のアカウントに「ストレージBLOB共同作成者」を付与する

Azure Synapse AnalyticsのSQLプールの生成
クエリ実行したデータを格納するためのSQLプールを作成する。
Synapse workspaceのメニューの「SQLプール」から新しいSQLプールを作成する

SQLプールのレベル設定は「DW100c」に設定して作成する

Azure Data Lake Storage Gen2 のコンテナ作成
データレイク機能APIで作成したAzure Data Lake Storage Gen2に対してコンテナを作成します。
コンテナタブから新規にコンテナを作成する(例:testコンテナ)


コンテナの認証方法として、Microsoft Entra ユーザーアカウントを選択する

コンテナ作成後、ディレクトリを追加する

Azure Data Factoryのデータ変換フローの構築
オブジェクトストレージからデータを取得し、Azure Data Lake Storage Gen2にデータを変換して格納するフローを構築します。
Azure Data FactoryのAzure Data Factory Studioにアクセスし、「新規」、「パイプライン」から新しくパイプラインを作成する

パイプラインのメニューでアクティビティ「データフロー」を選択し、下図のように有効化する

データフローの設定を行う。「設定タブ」から「新規」を選択する

新規を選択すると「データフロー」の設定に移動する。「データフロー」設定画面で、「ソースの追加」と表示されている箇所の右側にある矢印をクリックし、「ソースの追加」を選択する

ソースの追加後、「ソースの設定」タブを開き、データセットの設定部分の「新規」を選択する

データセットは「Amazon S3」を選択して、「続行」を選択する

データの種類は「DelimitedText」を選択して、「続行」を選択する

続いて、新規にソースのリンクサービスを作成する。図のように「新規」を選択する

オブジェクトストレージの事前準備で取得したバケットのパーミッションのアクセスキーID、シークレットアクセスキー、S3エンドポイントを入力する

「宛先ファイルパス」を選択し、ファイルパスにオブジェクトストレージのバケット名を入力し、作成を選択する

入力後、ファイルパスにオブジェクトストレージのバケット名とファイル名を入力。下向き矢印を選択して、「指定されたパスから」を選択する

サンプルファイルを選択してOKを選択する

「先頭行をヘッダーとして」からのチェックを外してOKを選択する

データ内のインポートが不要な行をスキップするためのスキップ設定を行う。スキップ行数は「12」に設定する

続いて、シンク(格納先)の設定を行う。+ボタンを選択し、シンクを選択する

「シンク」タブからシンク用のデータセットを新規に作成する

サービスはAzure Data Lake Storage Gen2を選択する

データの種類は「DelimitedText」を選択して、「続行」を選択する

シンクも新しくリンクサービスを作成する

認証はシステム割り当てマネージドIDにし、データレイク機能APIで作成したAzure Data Lake Storage Gen2を選択する

「宛先ファイルパス」を設定してAzure Data Lake Storage Gen2のコンテナ名とディレクトリ名を入力し、「作成」を選択する

ファイルパスの設定で再度コンテナ名とフォルダ名を入力し、「先頭行をヘッダーとして」からチェックを外し「OK」を選択する

全ての設定を終えたら「発行」を選択し、パイプラインの構築内容を保存する

デバッグフローを有効化する。「データフローのデバッグ」のトグルをクリックする

OKを選択する。クラスターの構築には数分を要する

デバッグフローが有効化されたら「デバッグ」を選択する。デバッグが開始される

デバッグ完了後、データレイク機能で作成したAzure Data Lake Storage Gen2のコンテナに移動し、以下のようにデータフローの実行により、ファイルが格納されたことを確認する

Azure Synapse Analyticsを利用したAzure Data Lake Storage Gen2へのクエリ検索
Synaspse Studioを開き、「Develop」からSQLスクリプトを作成する

接続を専用SQLプールに設定し、以下のSQL文を実行して外部データソースを作成する
CREATE EXTERNAL DATA SOURCE dlsusecasea2_datasource WITH ( LOCATION = 'abfss://{コンテナ名}@{Azure Data Lake Storage Gen2のリソース名}.dfs.core.windows.net', TYPE = HADOOP );

外部テーブルと外部フォーマット作成のために以下のSQL文を実行する
CREATE EXTERNAL FILE FORMAT csv_file_format WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', FIRST_ROW = 1 ) ); CREATE EXTERNAL TABLE dbo.sample_csv ( [year] INT, [value] FLOAT ) WITH ( LOCATION = '{ディレクトリ名}/{Azure Data Factoryを利用してAzure Data Lake Gen2 にインポートされたファイル名}', DATA_SOURCE = dlsusecasea2_datasource, FILE_FORMAT = csv_file_format );

クエリ機能を利用する。yearが2000年のものを表示するために以下のSQL文を実行する。また、クエリ実行結果をPowerBIに読み込ませるためにビューとして作成する
CREATE VIEW dbo.filtered_sample_csv AS SELECT * FROM dbo.sample_csv WHERE year BETWEEN 2000 AND 2009;

関連情報(Azure Synapse Analytics): Synapse SQLで外部テーブルを使用する
PowerBIとAzure Synapse Analytics
Power BI Desktop を開き、「他のソースからデータを取得する」を選択する

「Azure」から「Azure Synapse Analytics SQL」を選択する

専用SQLデータベースエンドポイント(Azure Portal上にあるSynapseWorkspaceの概要で確認できる)と専用SQLプールのデータベース名を入力する

Microsoftアカウントでサインインを行う

サインインが完了したら「接続」を選択する

クエリ実行時に作成したViewを選択する

接続が完了すると取り込んだデータが表示される(キャプチャはデータビューの表示)

データビューに対して検索をかける場合は、列の三角のボタンを選択し、フィルターして表示したい列を選択する

絞った列のみビューとして表示されていることを確認できる

関連情報(PowerBI): チュートリアル: Power BI Desktop でサーバレス SQL プールを使用してレポートを作成する