データ変換パイプラインの構築
[更新:2026年07月30日]

大容量のデータを柔軟に蓄積できるオブジェクトストレージに集約し、ETLで抽出・加工・整形することで、分析や活用に適した高品質データへと統合します。これにより、手作業の削減と処理の再現性を確保しつつ、迅速で信頼性の高いデータ供給が可能となり、業務全体の効率化とデータ活用の高度化を実現できます。
各機能のサービス対応
機能 |
対応サービス |
|---|---|
データレイク |
Azure Data Lake Storage Gen2 |
ETL/データ変換 |
Azure Data Factory |
システム構成要素
さくらのクラウド
オブジェクトストレージ
Addon
Azure Data Lake Storage Gen2
Azure Data Factory
構築手順
さくらのクラウドオブジェクトストレージでの事前準備
バケットの作成
さくらのクラウドのコントロールパネルにアクセスし、オブジェクトストレージからバケットを作成する。
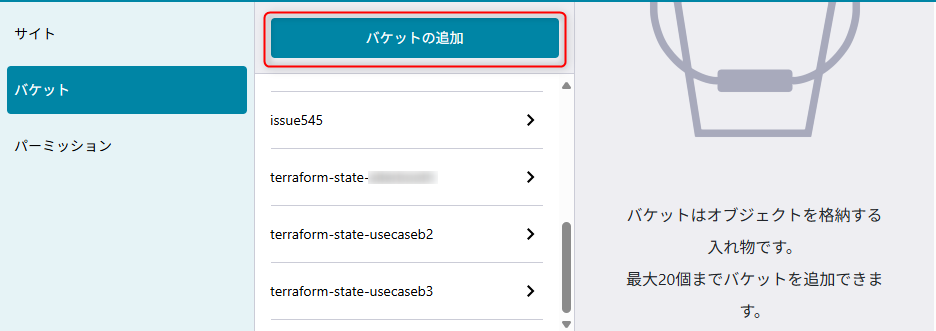
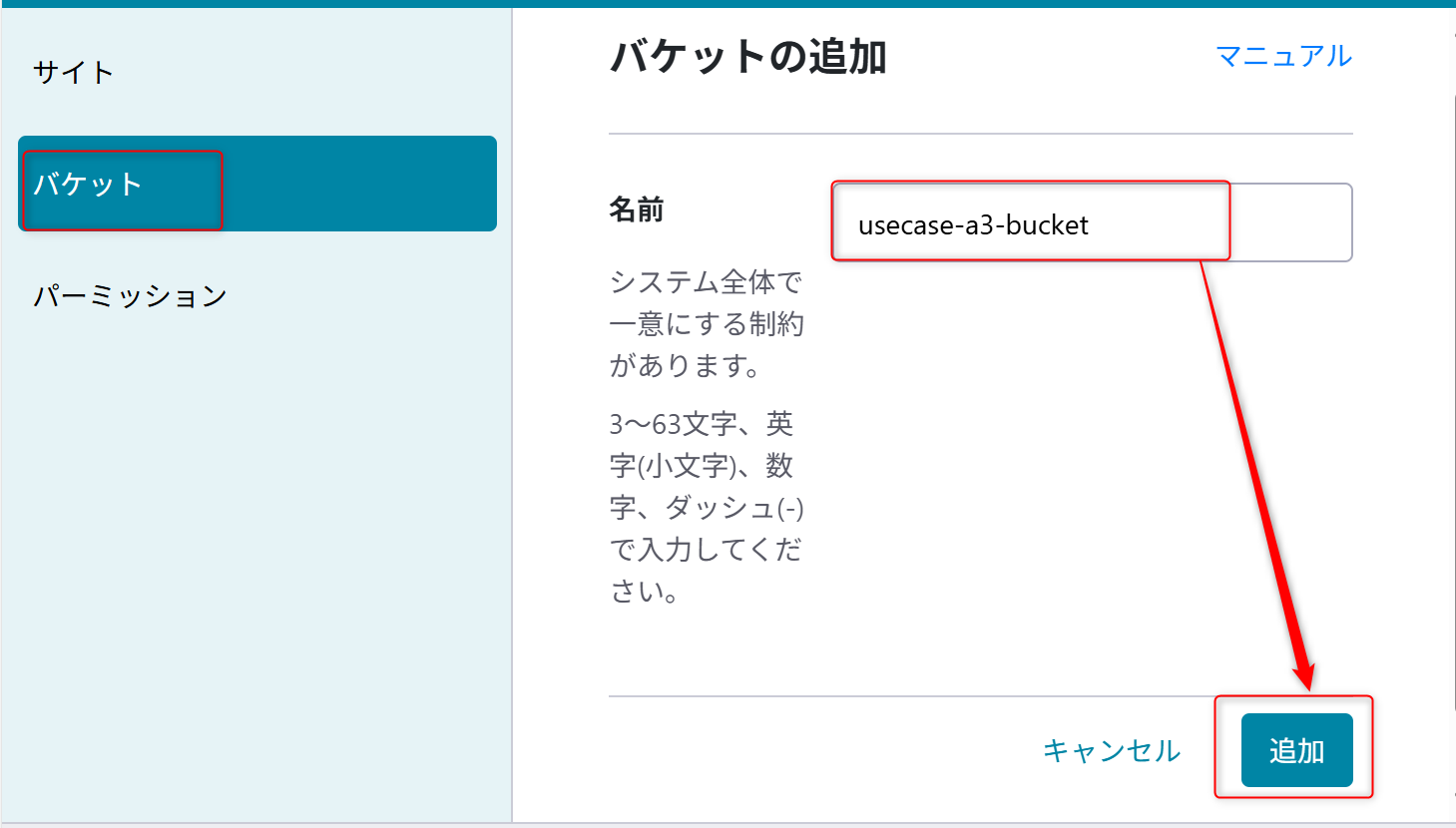
「usecase-a3-bucket」という新たなバケットを作成する
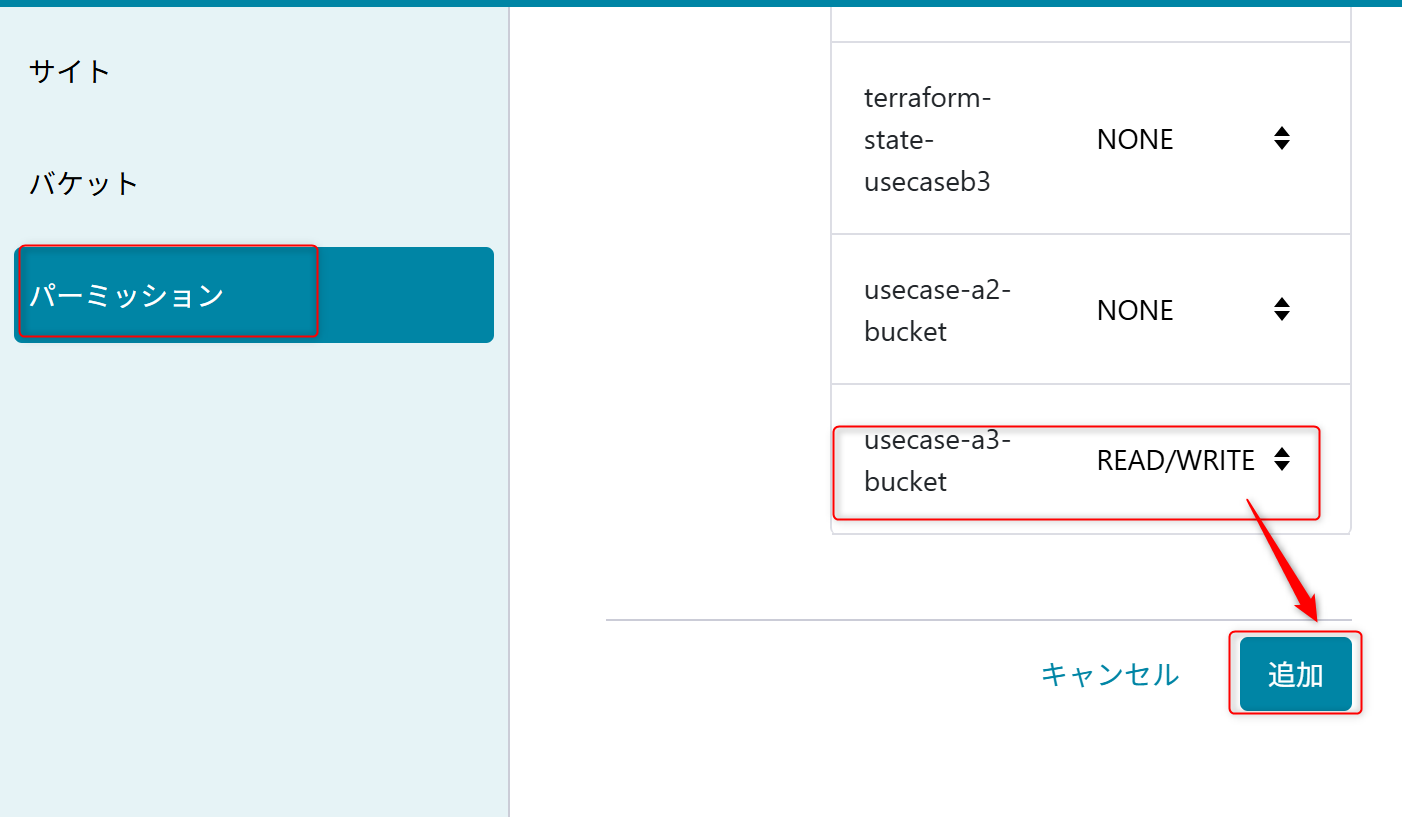
パーミッションの設定
後ほど Azure Data Factoryでオブジェクトストレージの内容を読み込むためにパーミッションを設定する。
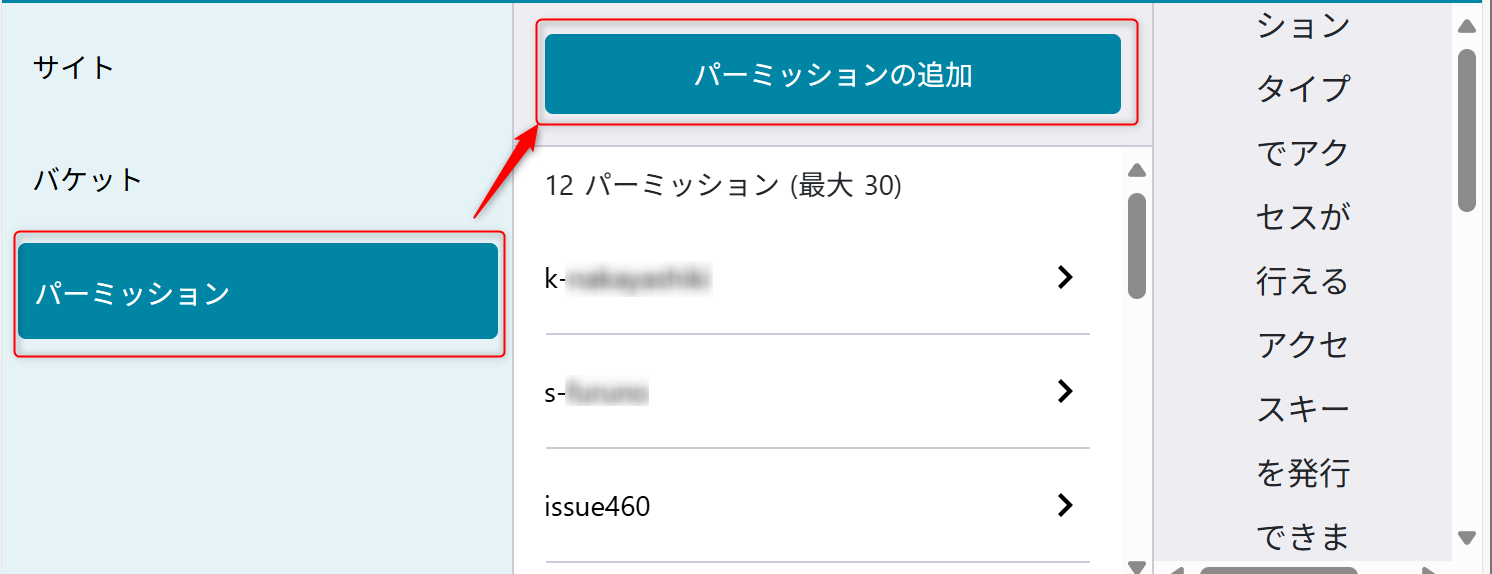
パーミッション名は「usecase-a3」を設定する。
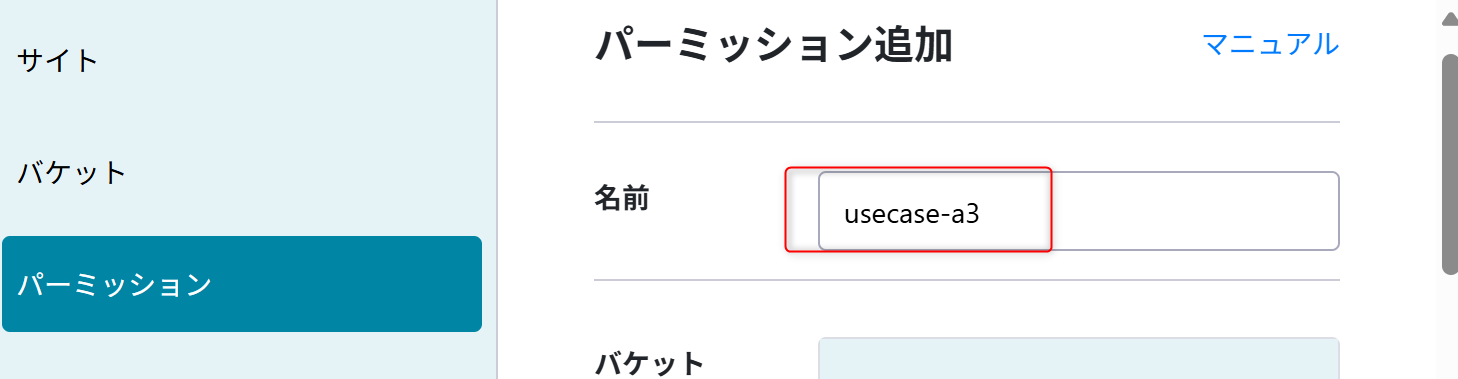
権限は「usecase-a3-bucket」の「READ/WRITE」を設定する。
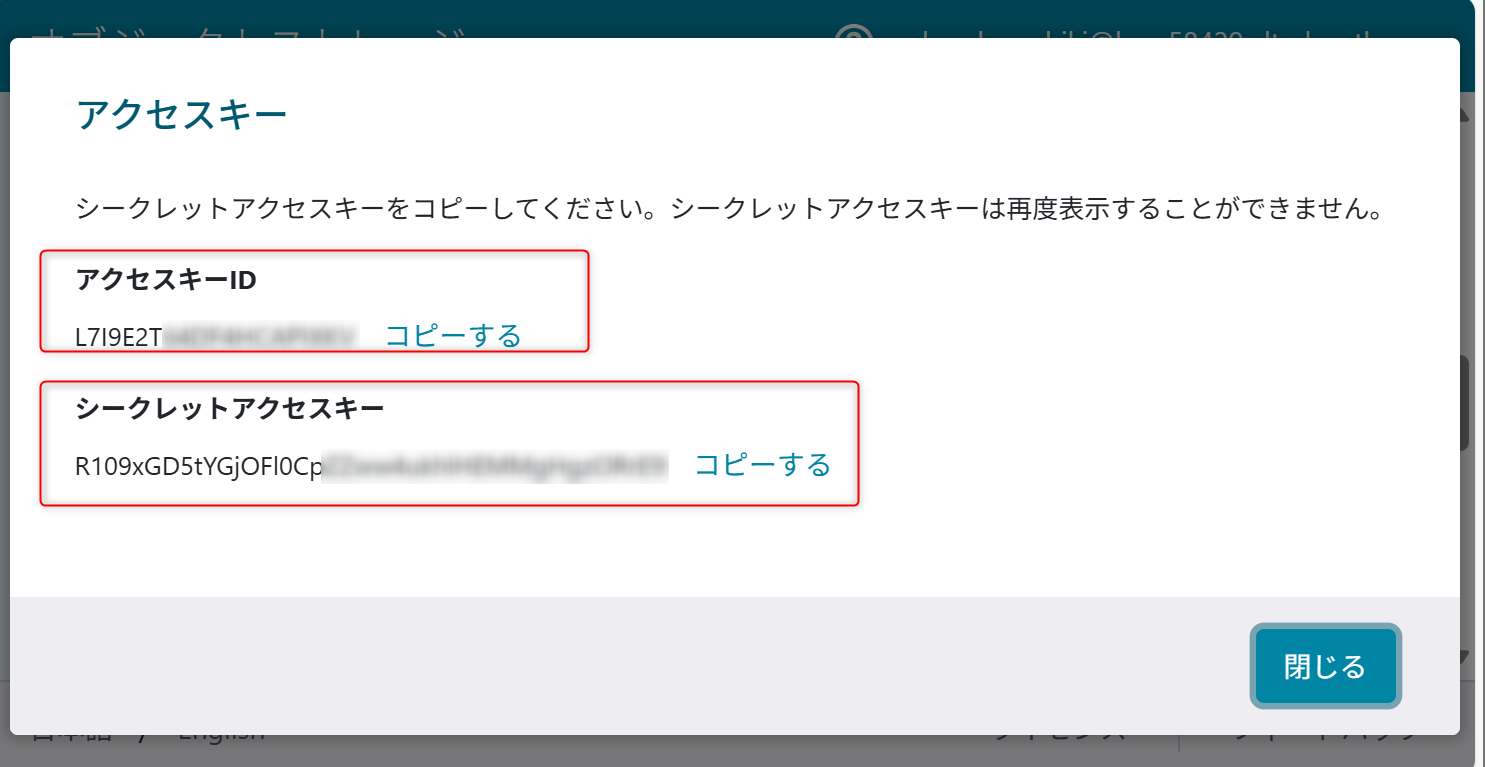
作成時に表示されるアクセスキーIDとシークレットアクセスキーを記録しておく
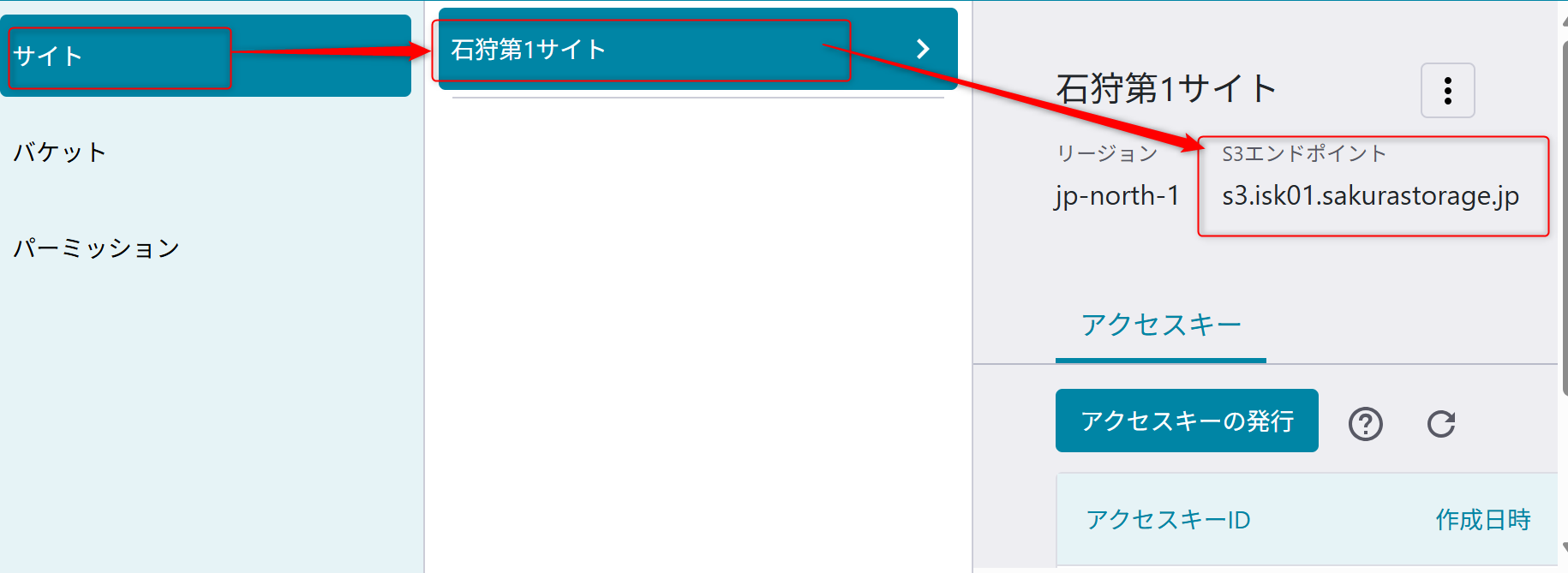
またS3エンドポイントを利用するため、「サイト」から、「usecase-a3-bucket」のバケットを作成しているサイトのS3エンドポイントの値を確認しておく。
オブジェクトストレージにデータをアップロード
参考情報:オブジェクトストレージ サービス基本情報
オブジェクトストレージにサンプルデータをアップロードします。
以下のサンプルデータをオブジェクトストレージの「usecase-a3-bucket」のバケットのメニューからアップロードする。
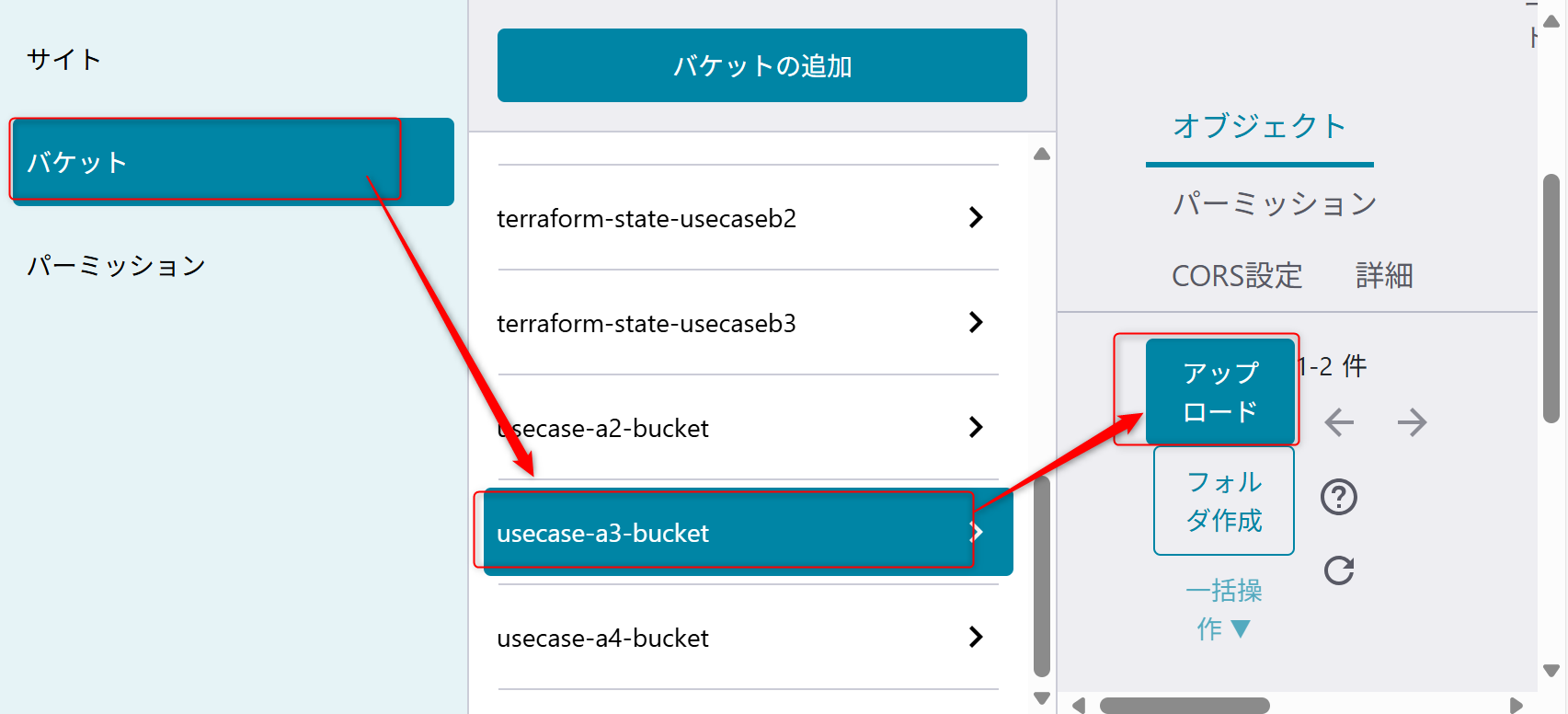
設定はprivateを選択してアップロードする。

Addon でのリソース作成
データレイク機能
Addon の 「データレイク機能」API を利用して Azure Data Lake Storage Gen2を作成します。
TOKEN='<サービスプリンシパルのアクセストークン>'
#POST
curl -v \
--location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/datalake' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $TOKEN" \
--data '{
"location": "japaneast",
"performance": 1,
"redundancy": 1
}'
ETL機能
Addon の 「ETL機能」API を利用して Azure Data Factory を作成します。
TOKEN='<サービスプリンシパルのアクセストークン>'
#POST
curl -v \
--location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/etl' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $TOKEN" \
--data '{
"location": "japaneast"
}'
RBACの設定
RBACの設定には、Azure Portalを操作するユーザーに対してユーザアクセス管理者ロールの付与が必要になります。
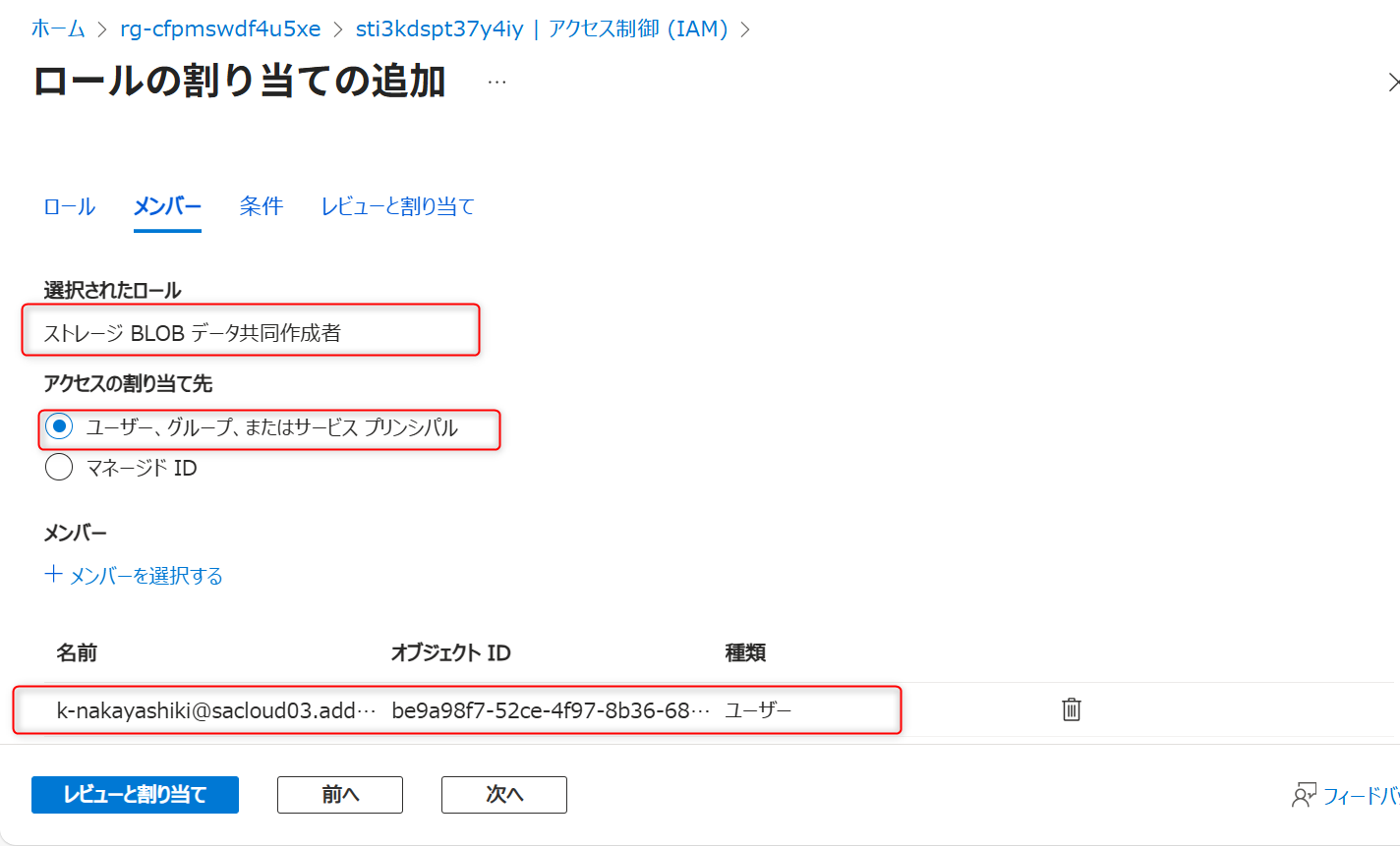
Azure Data Lake Storage Gen2 (データレイク用)のアクセス制御を開き、Azure Data FactoryのマネージドIDに対して「ストレージBLOBデータ共同作成者」を付与する。
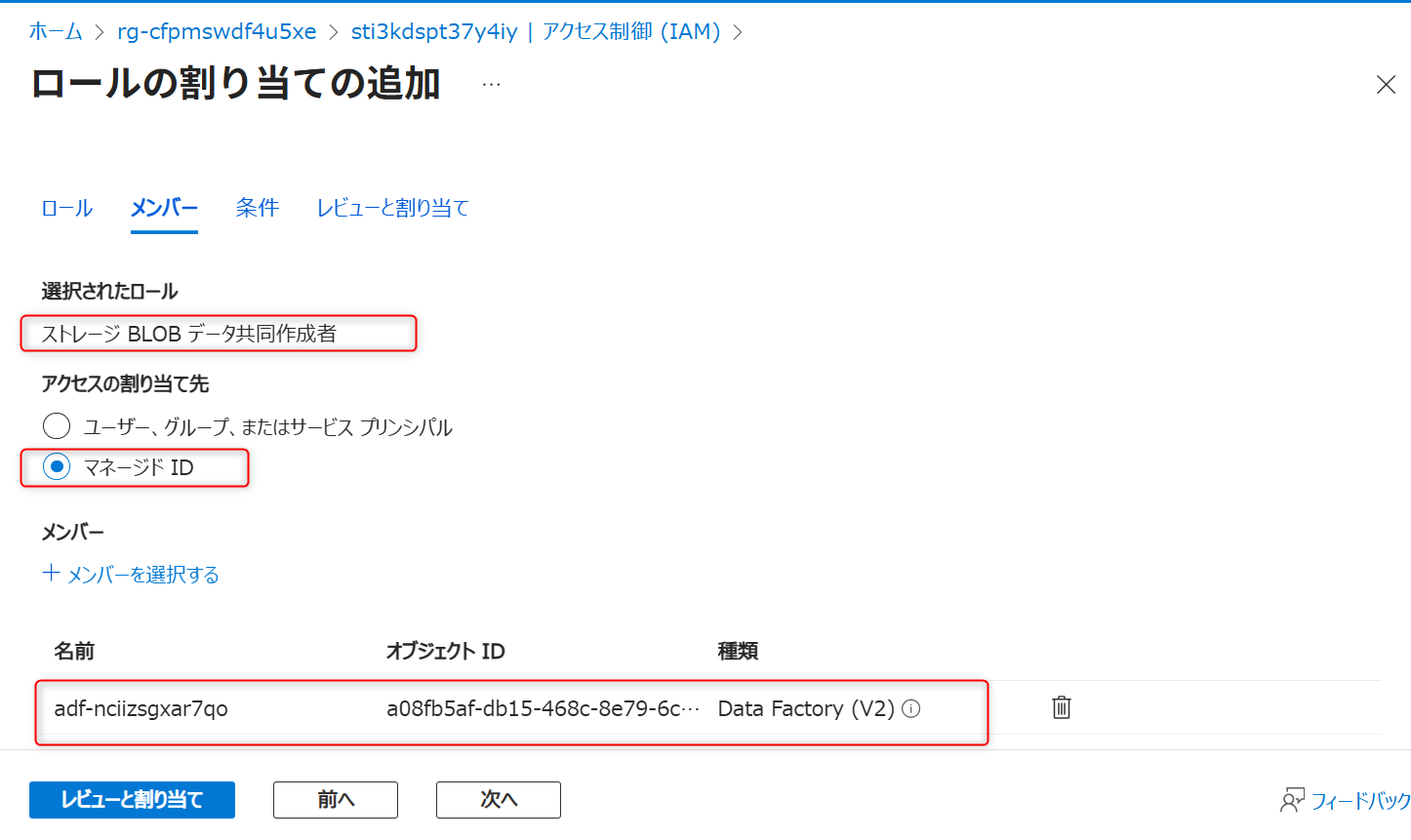
Azure Data Lake Storage Gen2 (データレイク用)のアクセス制御を開き、自身のアカウントに対して「ストレージBLOBデータ共同作成者」を付与する。
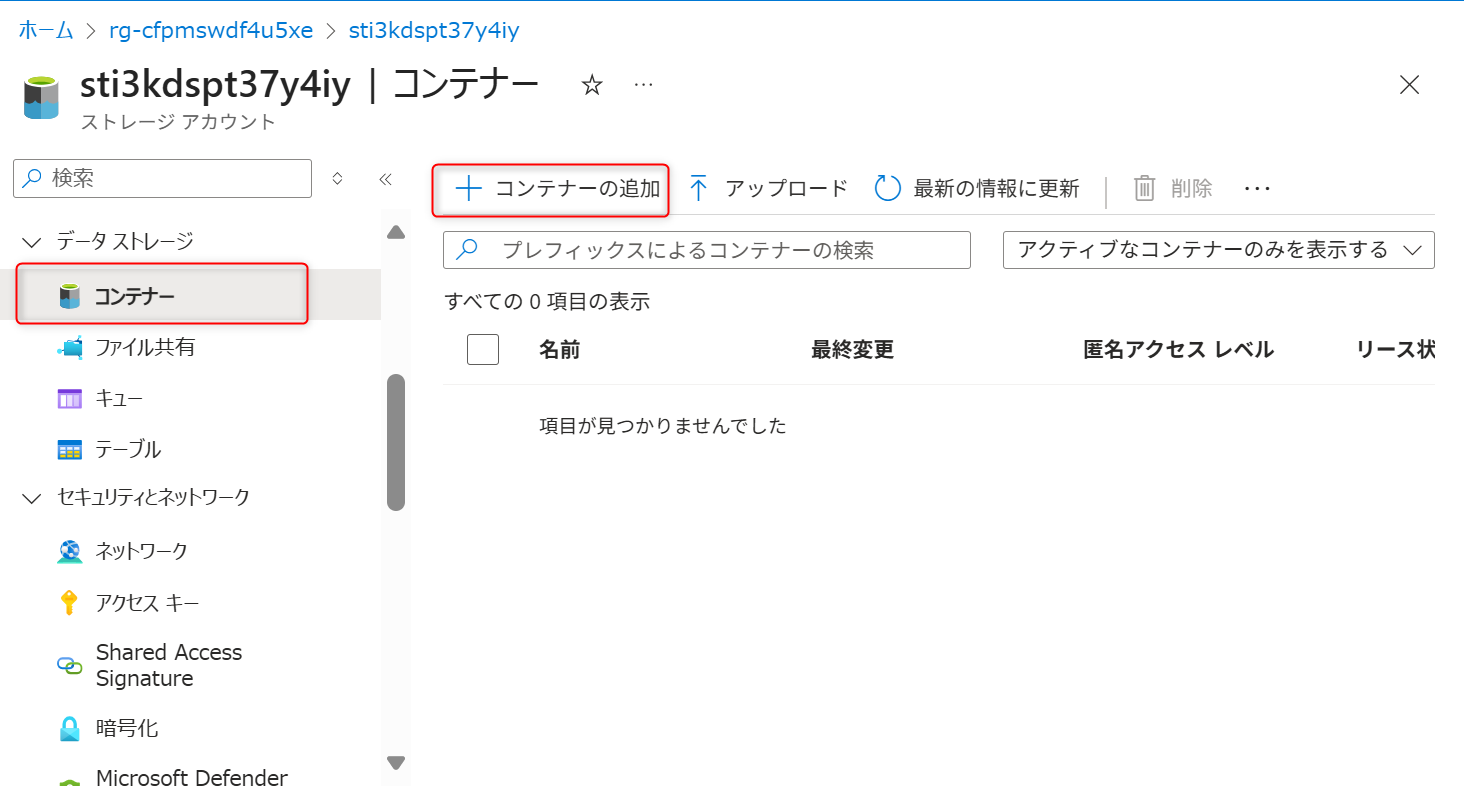
データレイクのコンテナー作成
データレイク用で利用するAzure Data Lake Storage Gen2に対してコンテナーを作成する。コンテナータブから新規にコンテナーを作成する(本手順では「test」のコンテナーを作成している)。
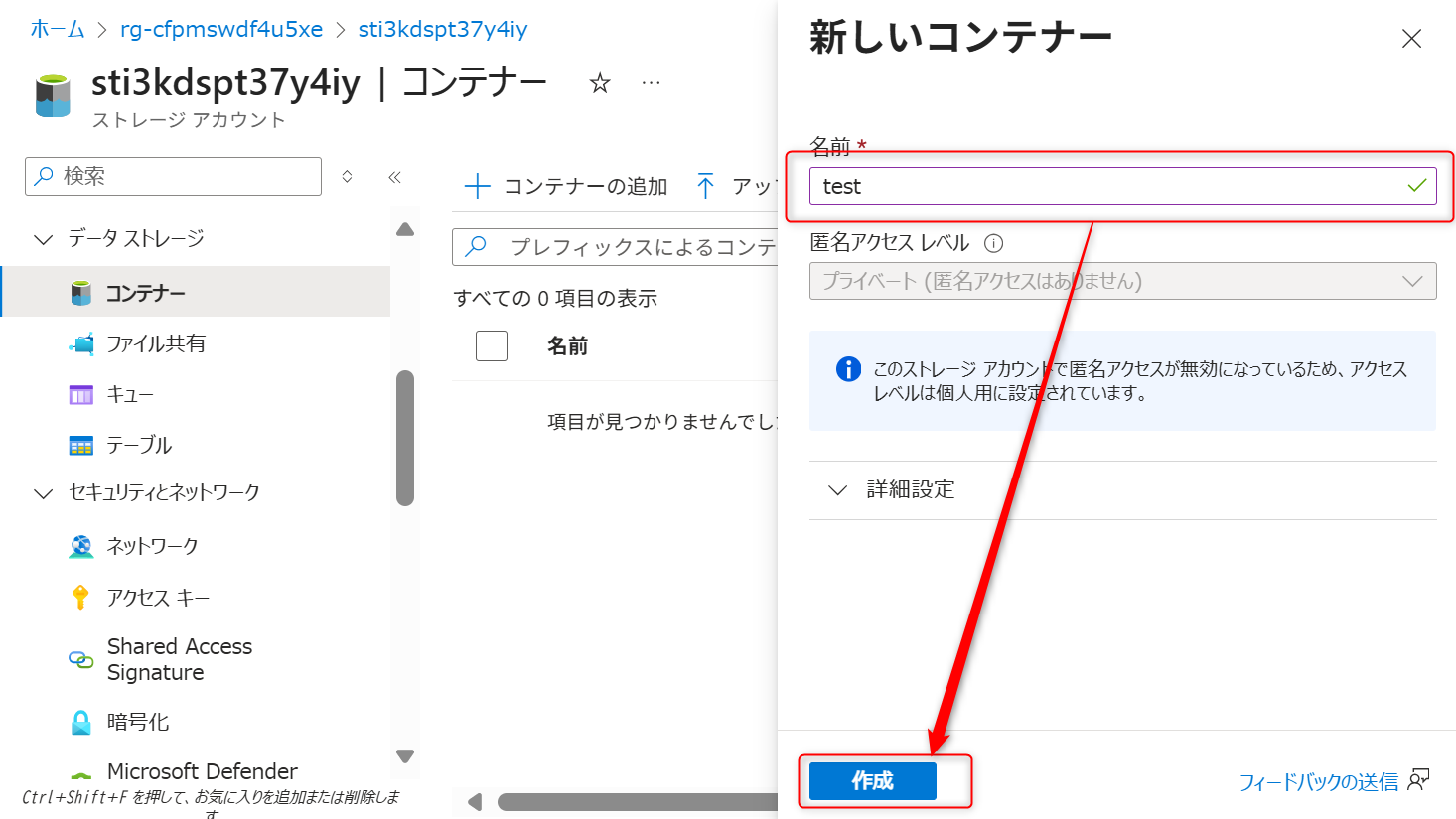
コンテナーの認証方法は、Microsoft Entraユーザーアカウントに設定する。

コンテナー作成後、ディレクトリを追加する。

Azure Data Factoryのデータの変換・格納のパイプライン構築
オブジェクトストレージからAzure Data Lake Storage Gen2へ
オブジェクトストレージからデータを取得し、Azure Data Lake Storage Gen2にデータを変換して格納するフローを構築します。
Azure Data Factory Studio にアクセスし、「新規」、「パイプライン」から新しくパイプラインを作成する。
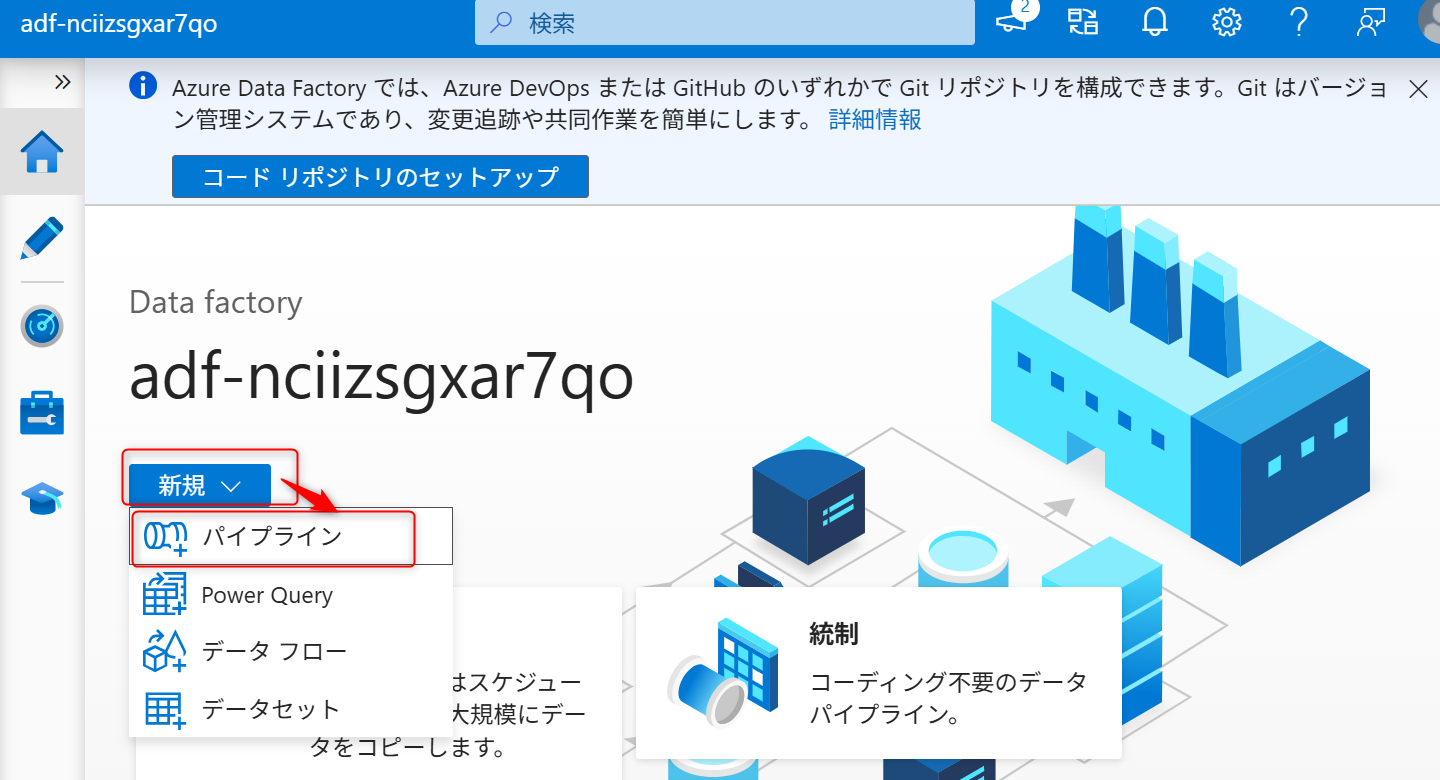
パイプラインのメニューでアクティビティ「データフロー」を選択し、画面の指示に従いドラッグする。
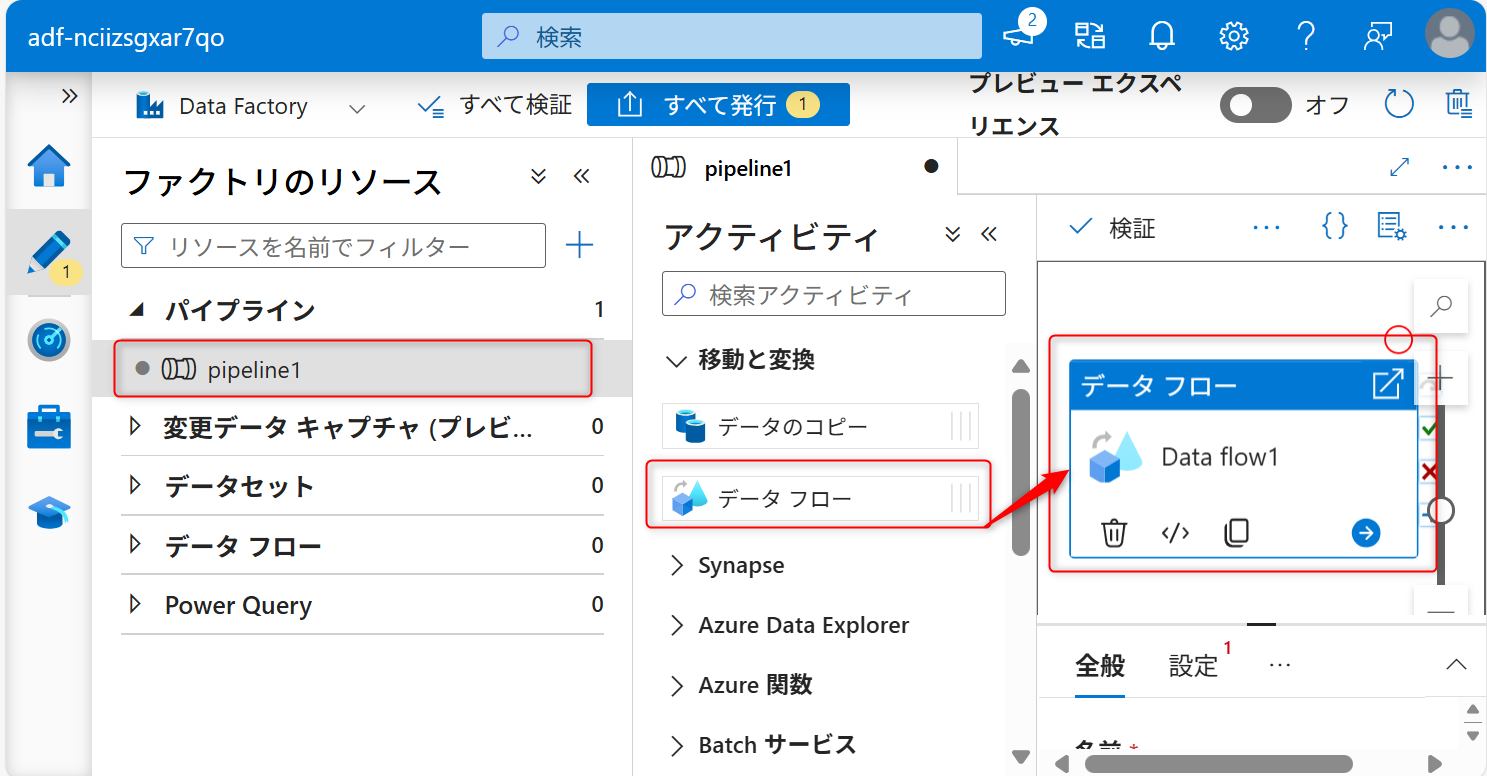
データの取得元のオブジェクトストレージの設定を行う。「設定タブ」から「新規」を選択する。

新規を選択すると「データフロー」の設定に移動する。ソースの追加と記載されてある部分の右側に表示されている矢印アイコンをクリックし、「ソースの追加」を選択する。
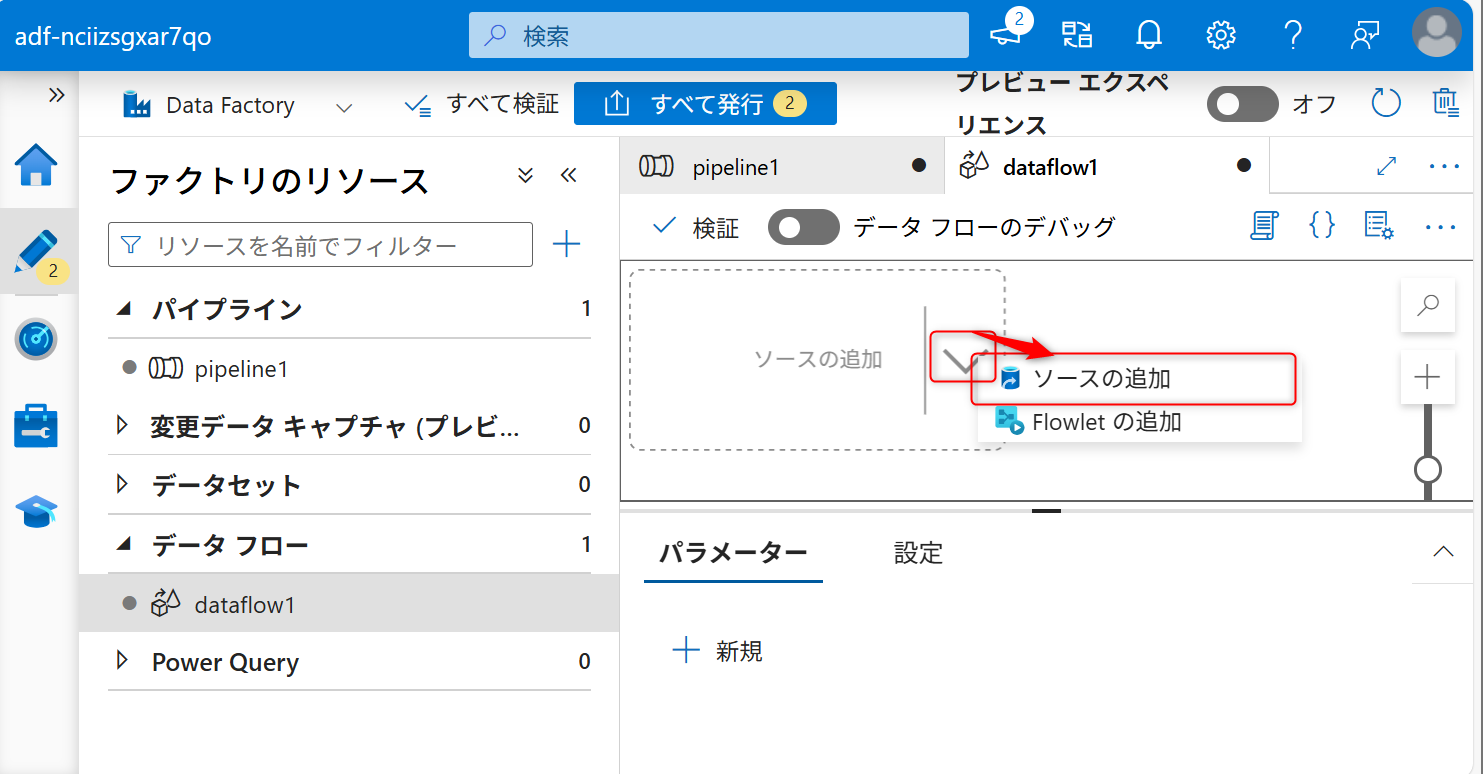
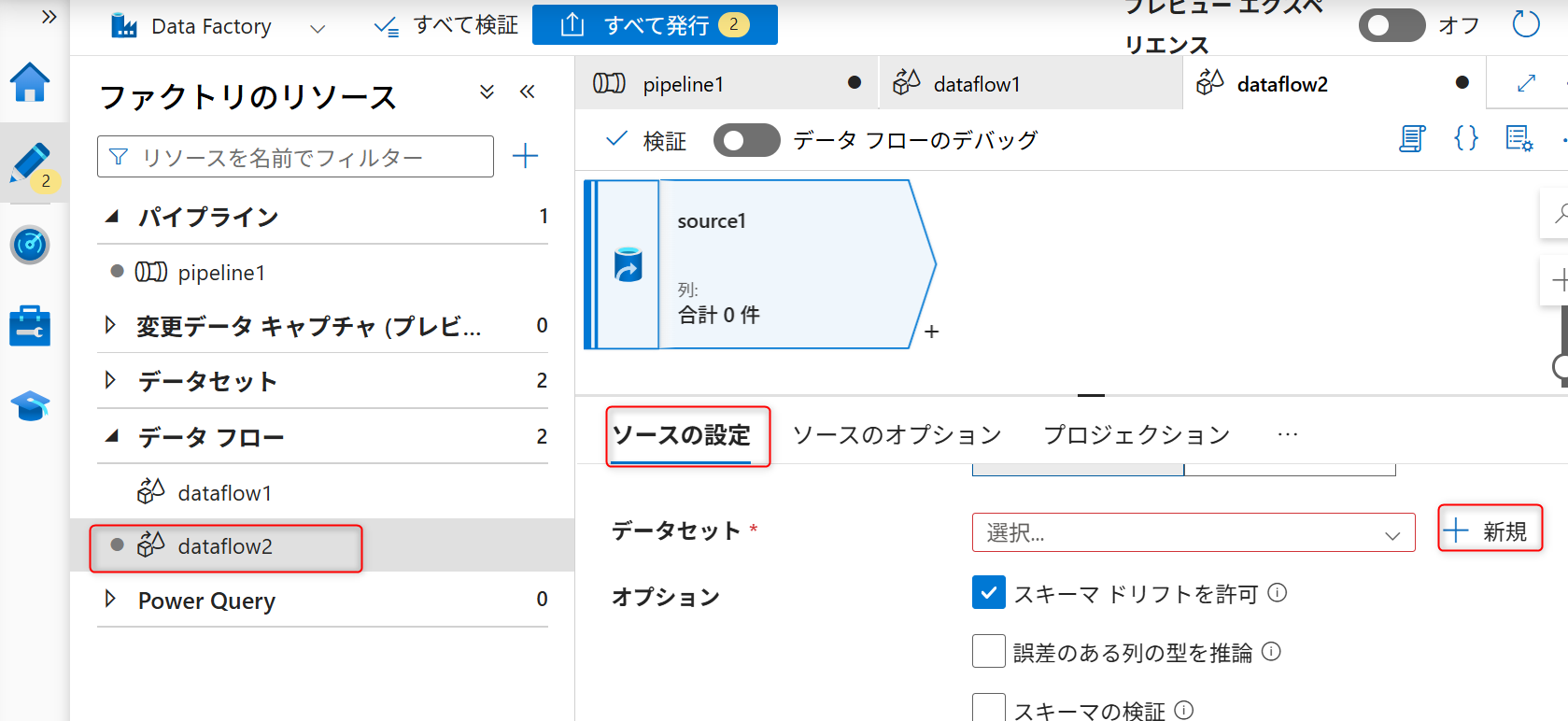
ソースの追加後、「ソースの設定」タブを開き、データセットの設定部分の「新規」を選択する。

データセットは「Amazon S3」を選択して、「続行」を選択する。
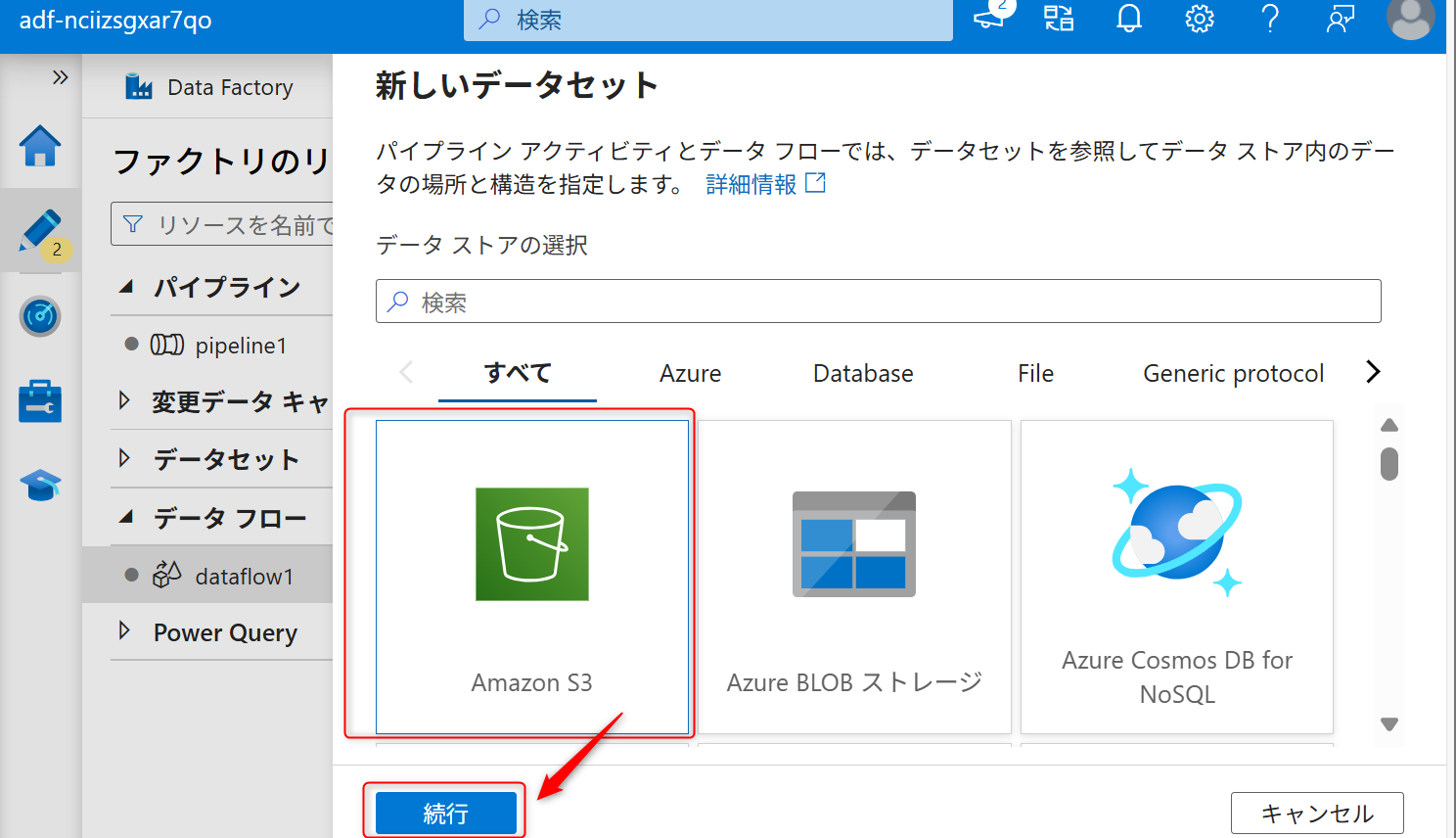
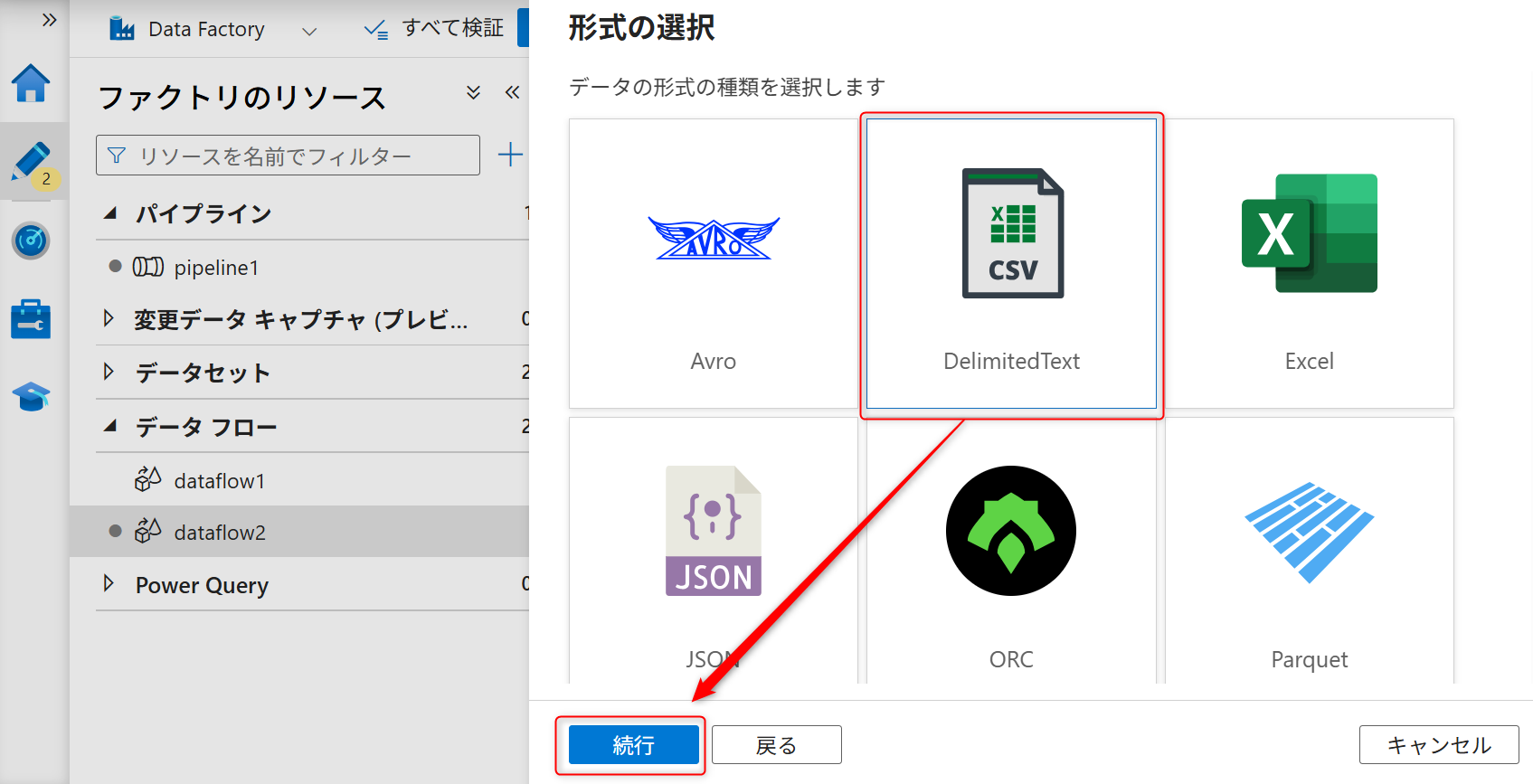
データの種類は「DelimitedText」を選択して、「続行」を選択する。
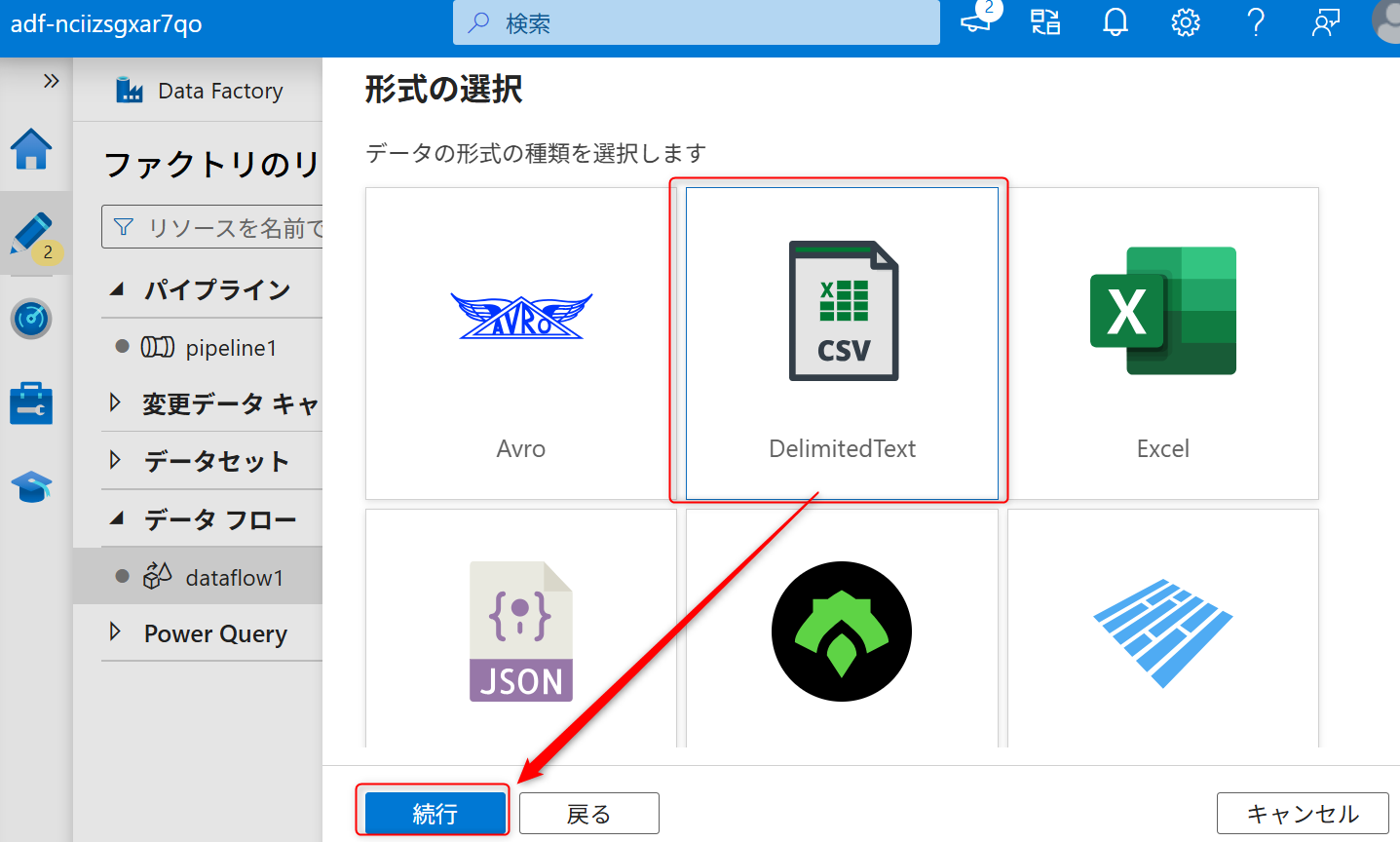
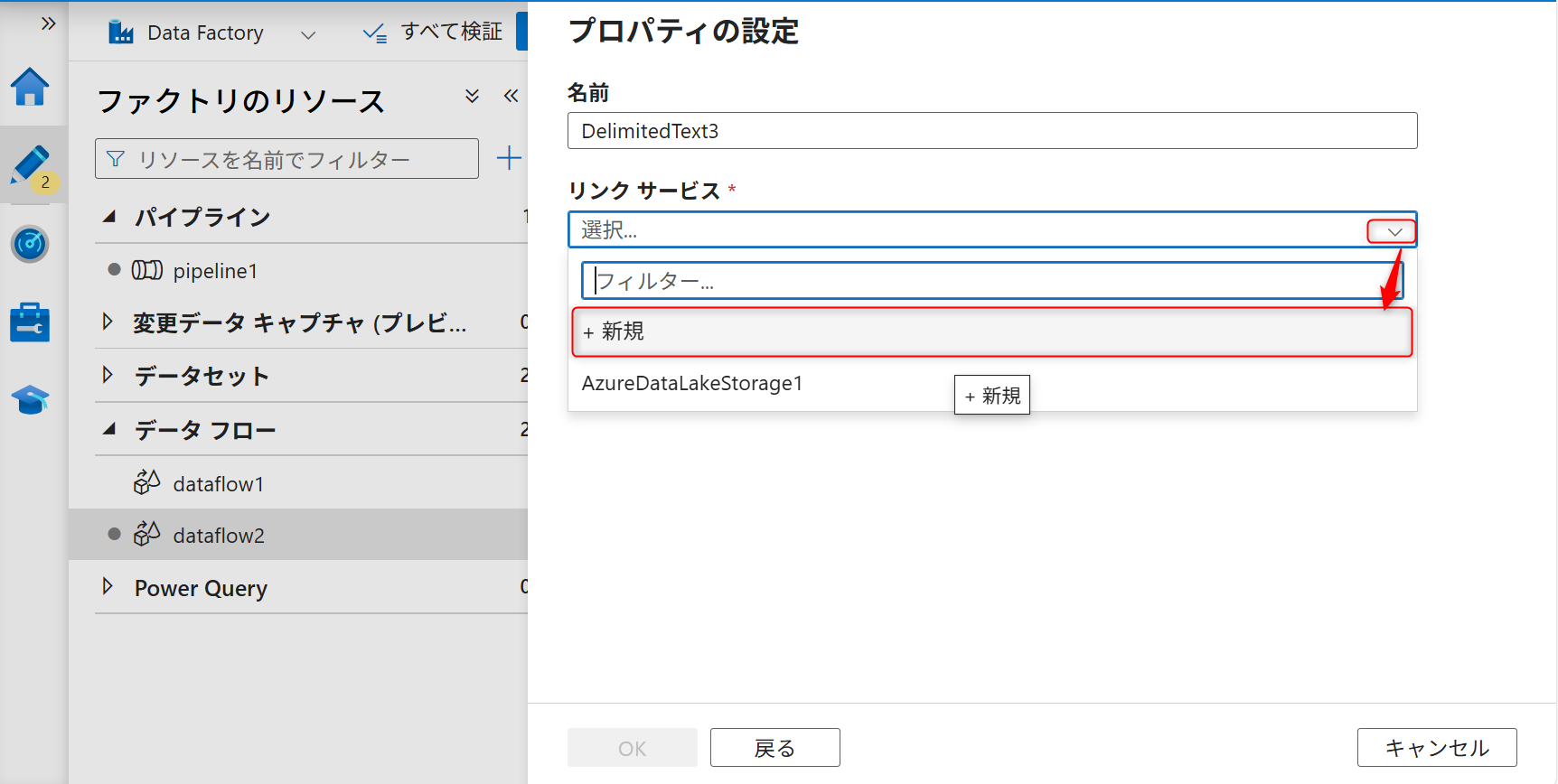
続いて、新規にソースのリンクサービスを作成する。キャプチャのように「新規」を選択する。
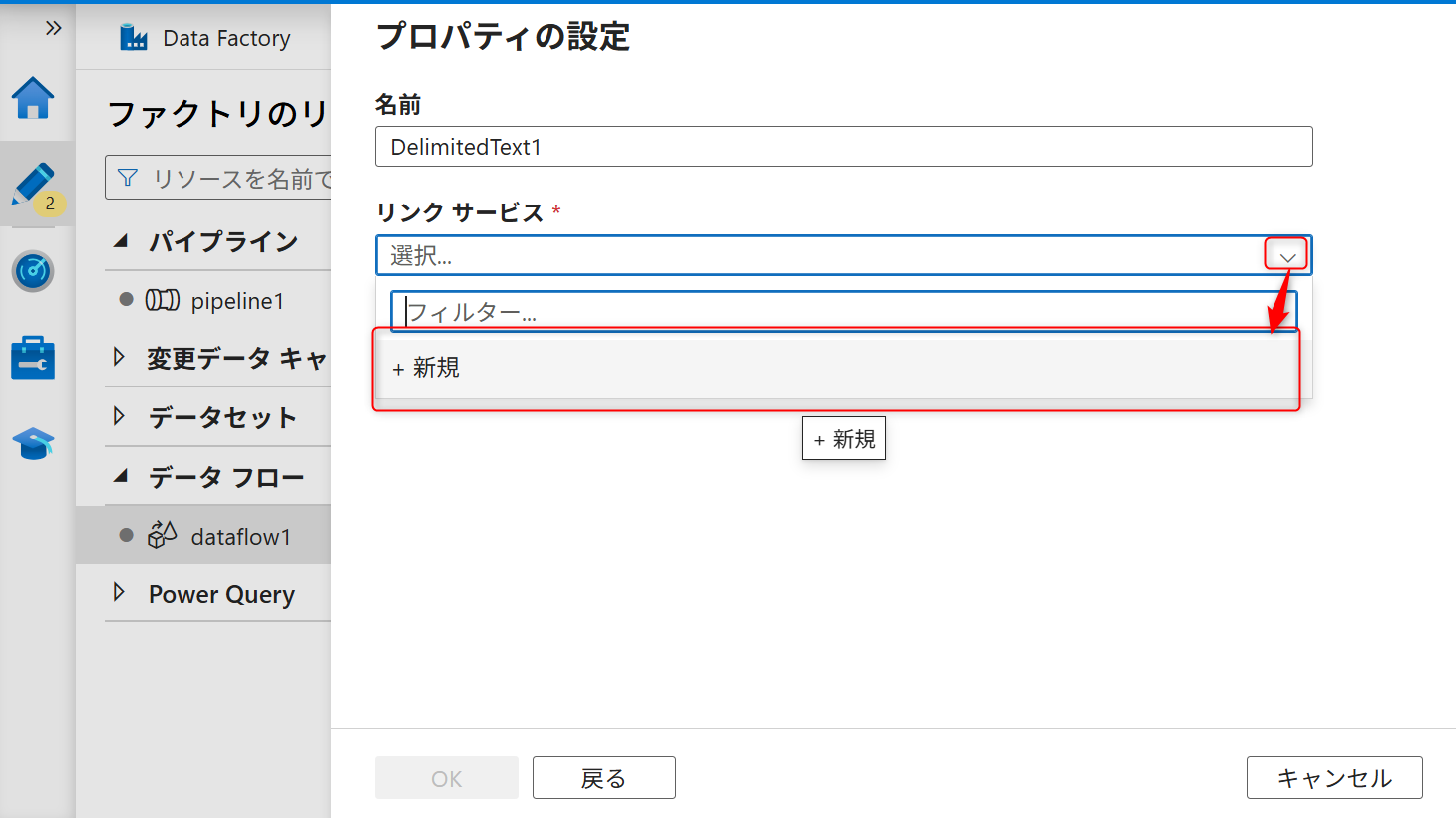
認証方法として「アクセスキー」を選択する。
オブジェクトストレージでの事前準備で確認したバケットのパーミッションのアクセスキーID、シークレットアクセスキー、S3エンドポイントを入力する。
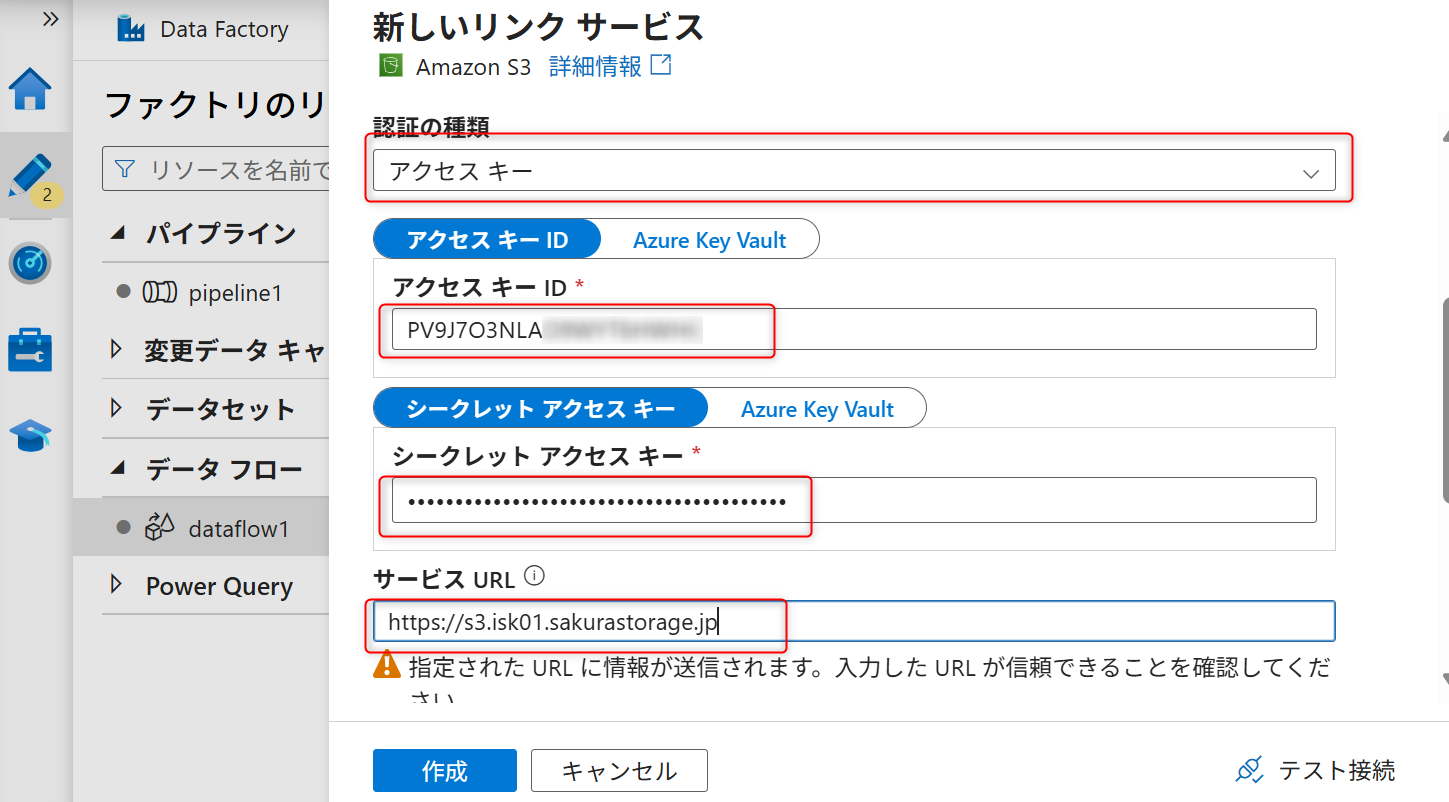
ファイルパスにバケット名を入力する。
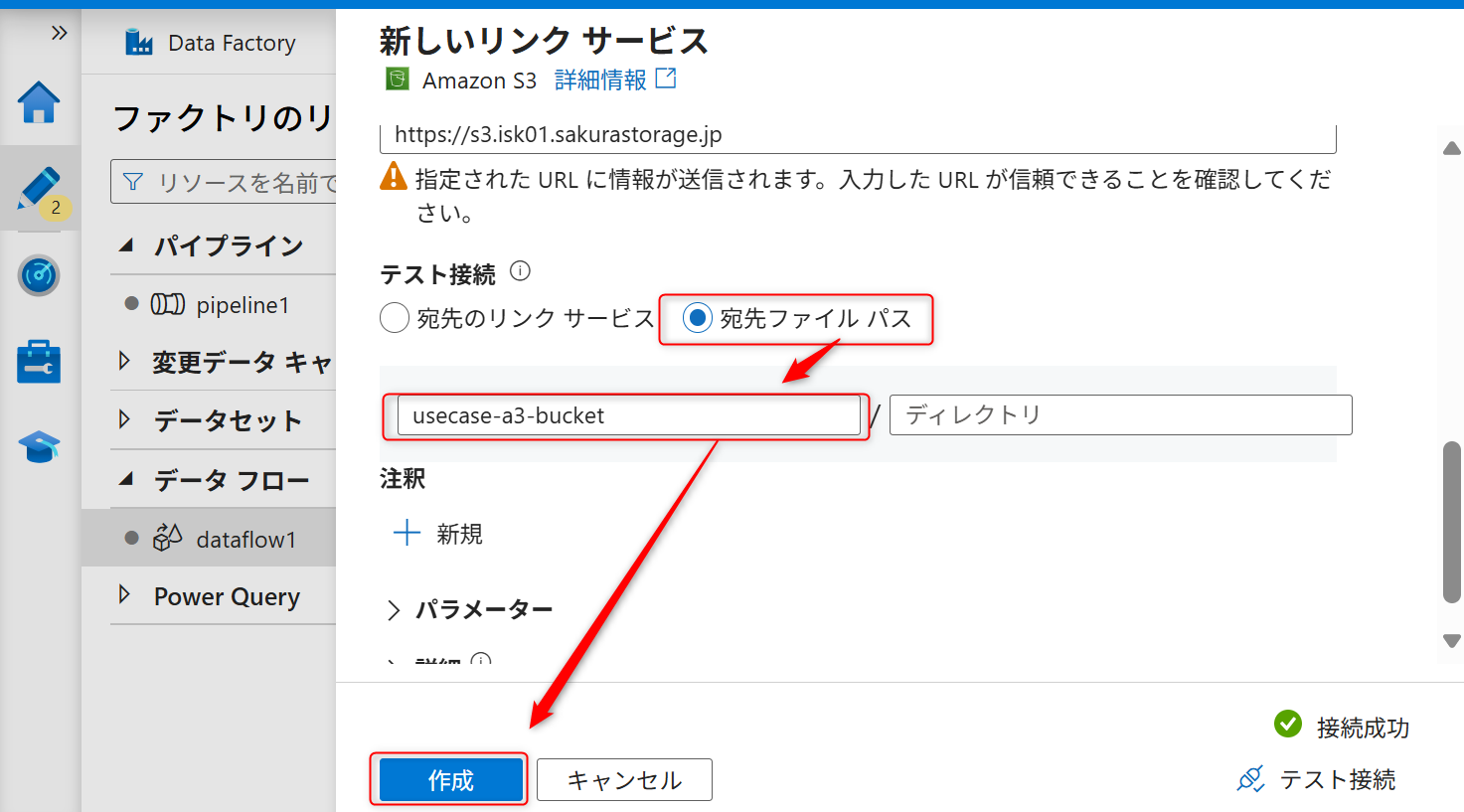
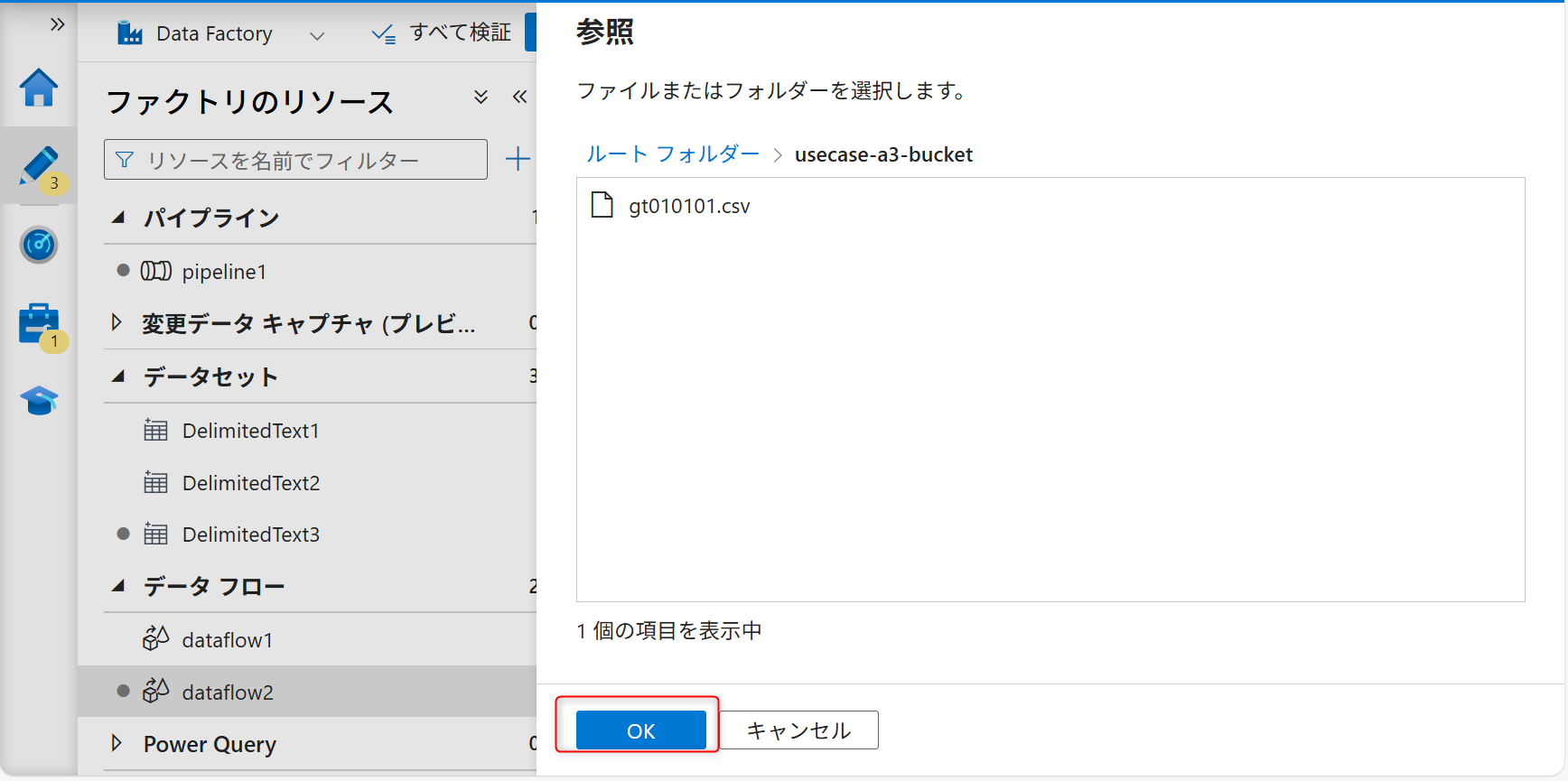
入力後、ファイルパスにオブジェクトストレージのバケット名とファイル名を入力し、ソースの追加ボタン(右側の矢印アイコン)をクリックし、「指定されたパスから」を選択する。
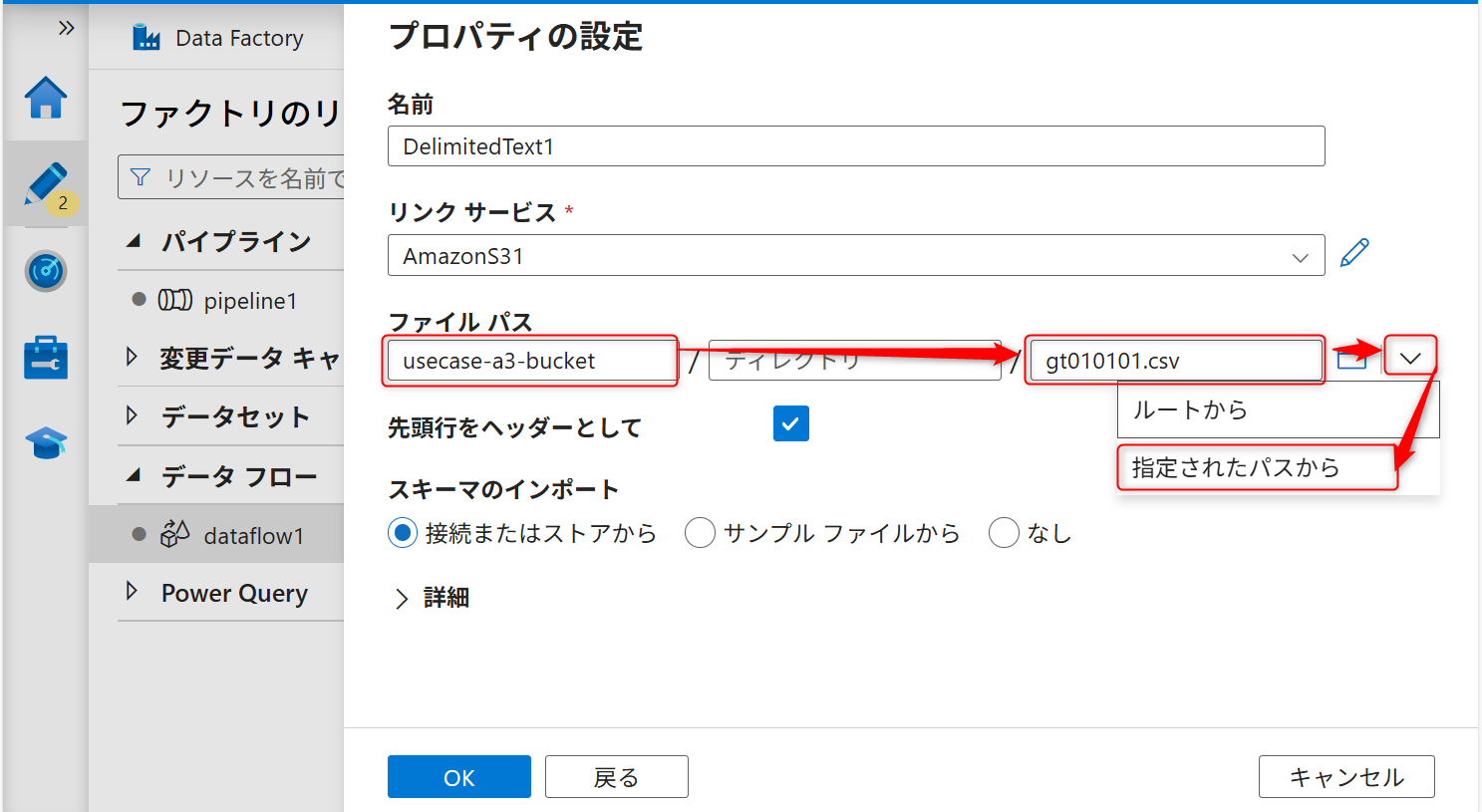
サンプルファイルを選択してOKボタンをクリックする。
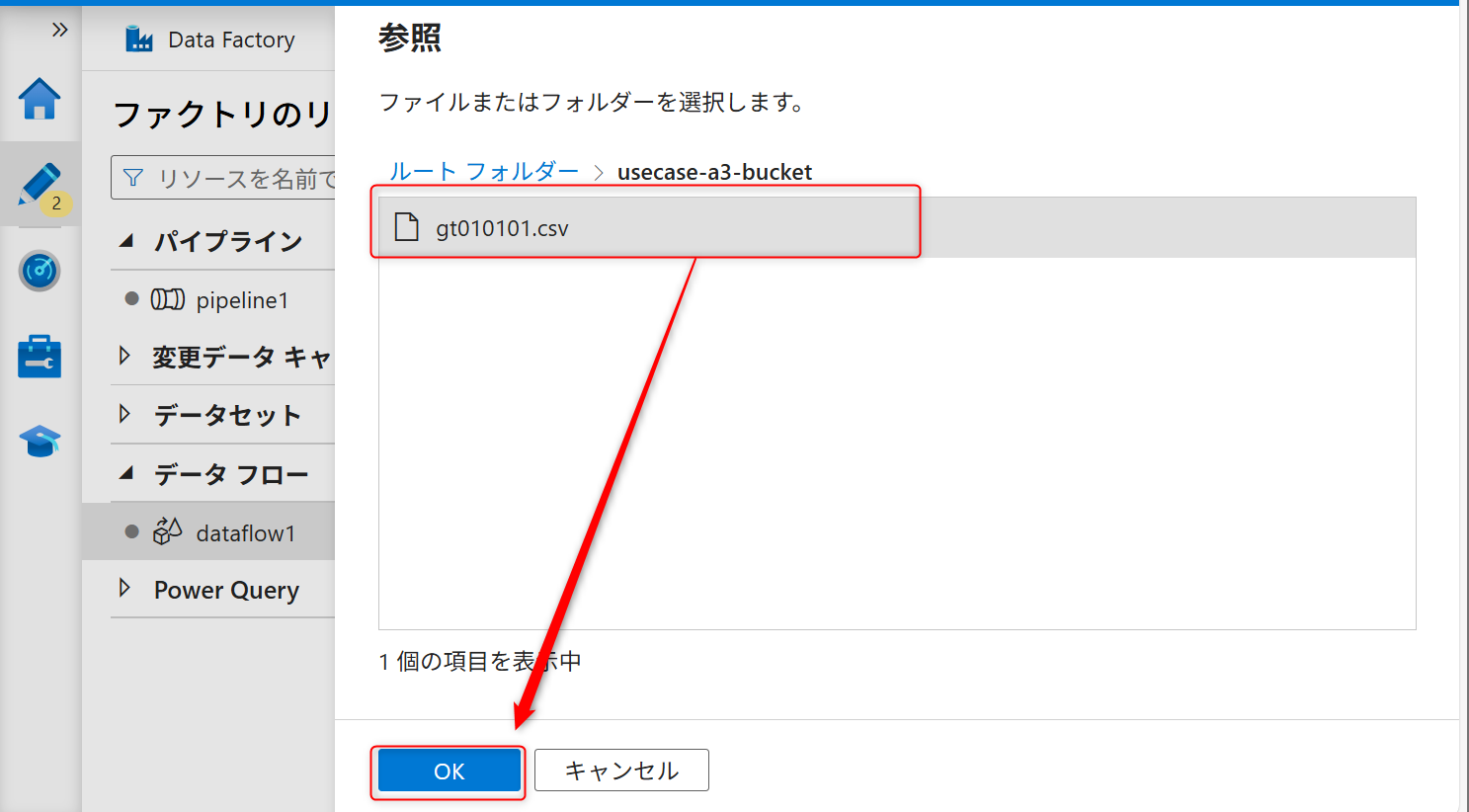
「先頭行をヘッダーとして」からのチェックを外してOKボタンをクリックする。
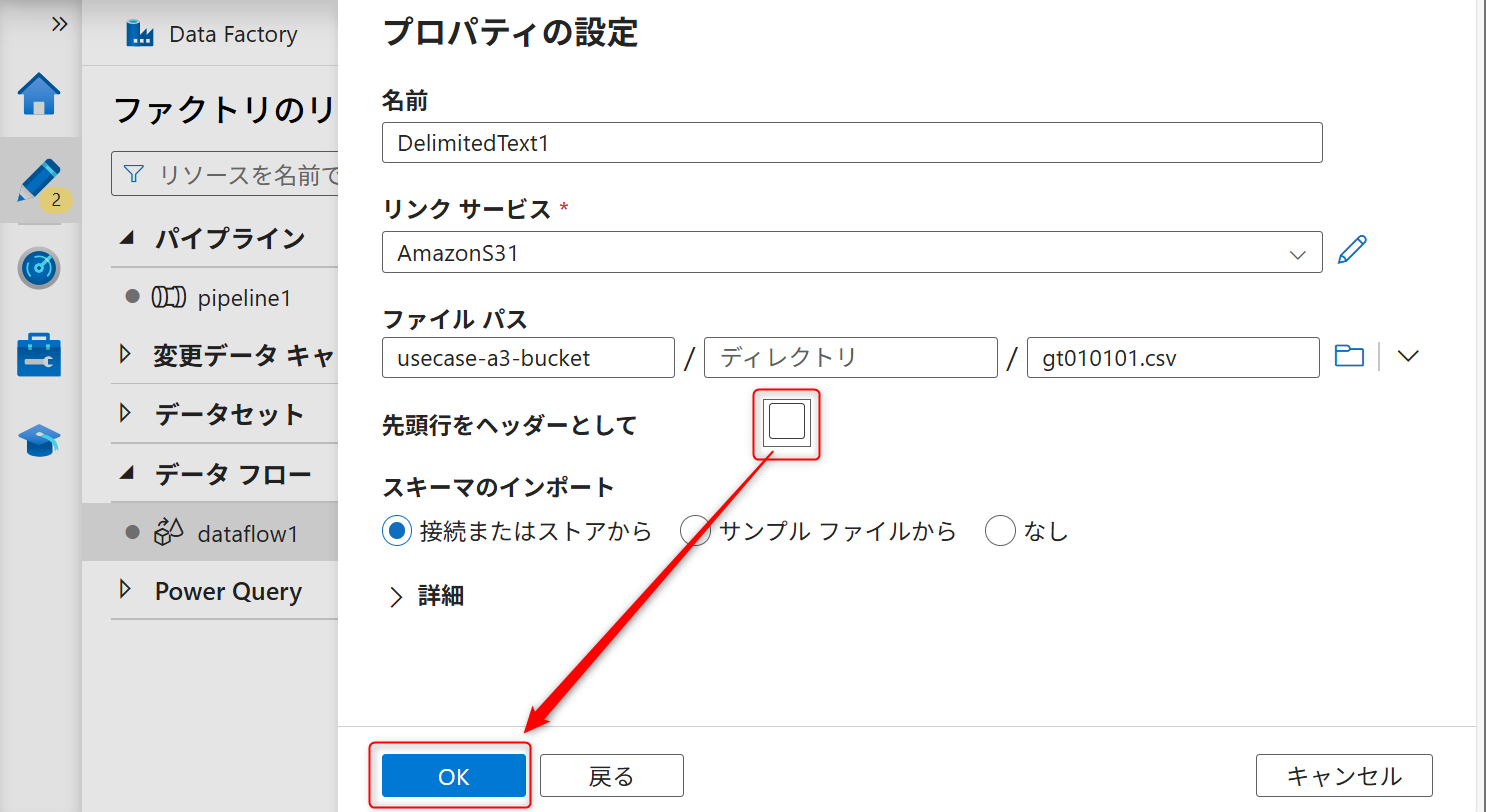
データ内のインポートが不要な行をスキップするためのスキップ設定を行う。スキップ行数は「12」に設定する。
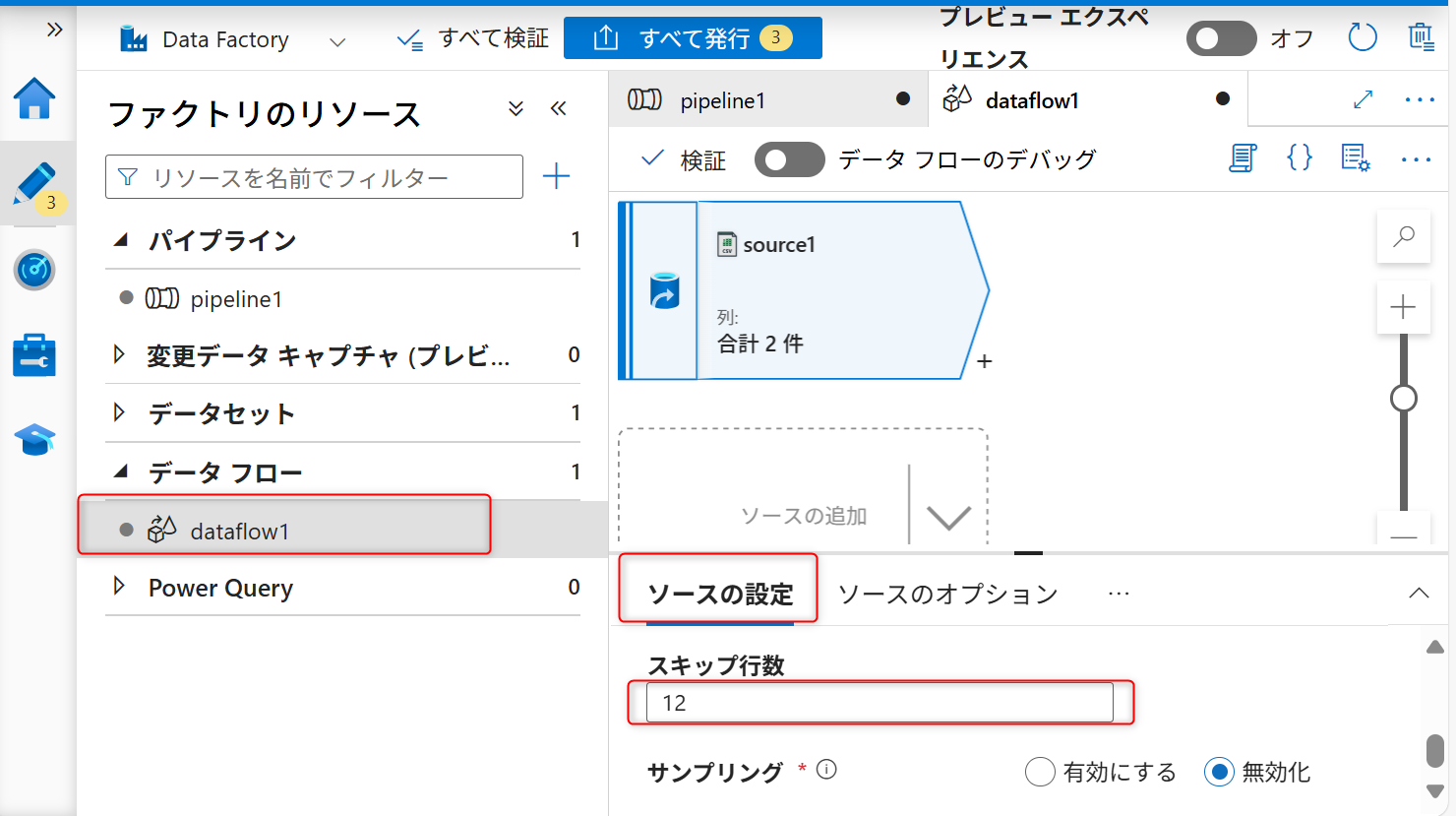
続いて、シンク(格納先)の設定を行う。+ボタンをクリックし、シンクを選択する。
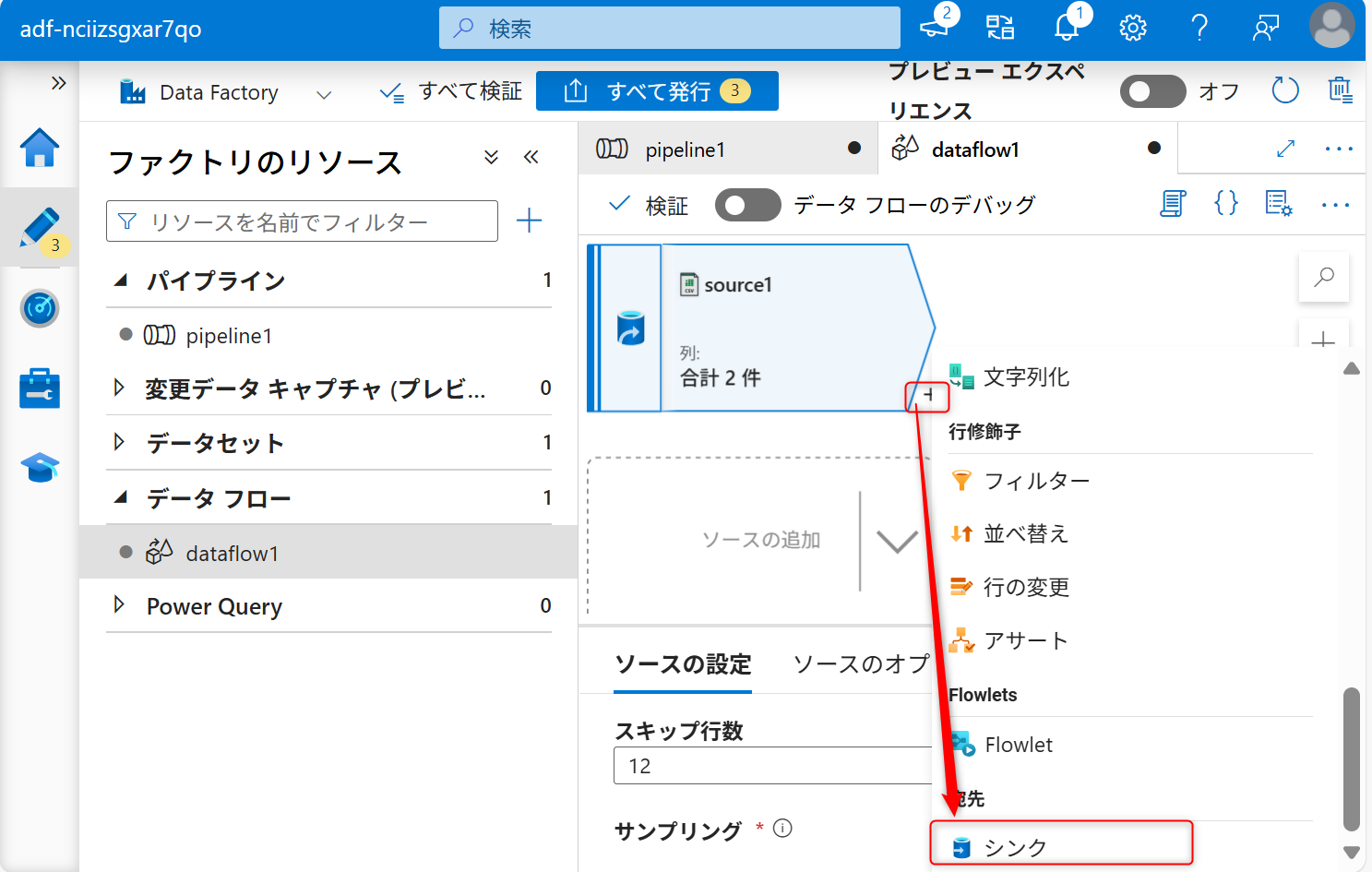
「シンク」タブからシンク用のデータセットを新規に作成する。
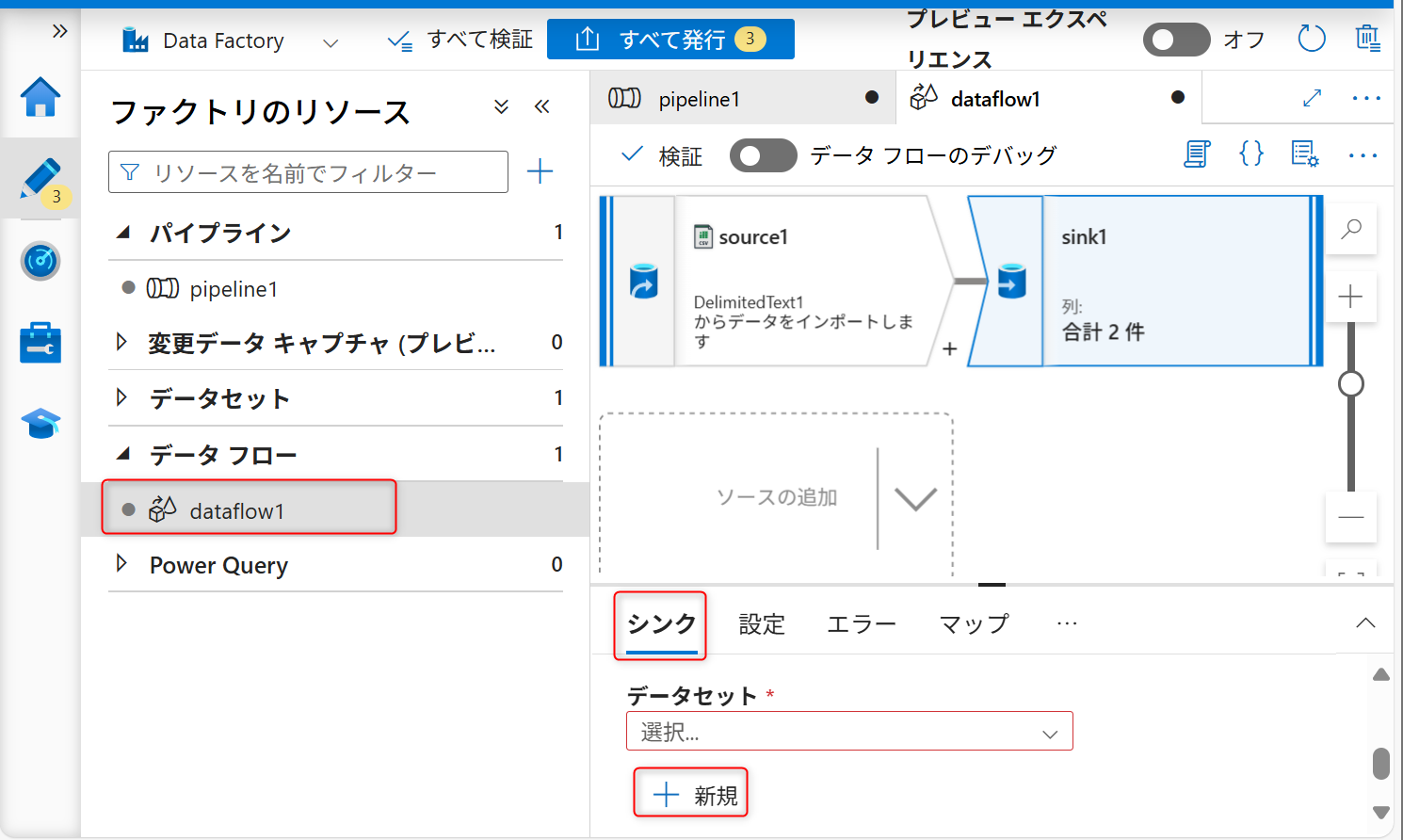
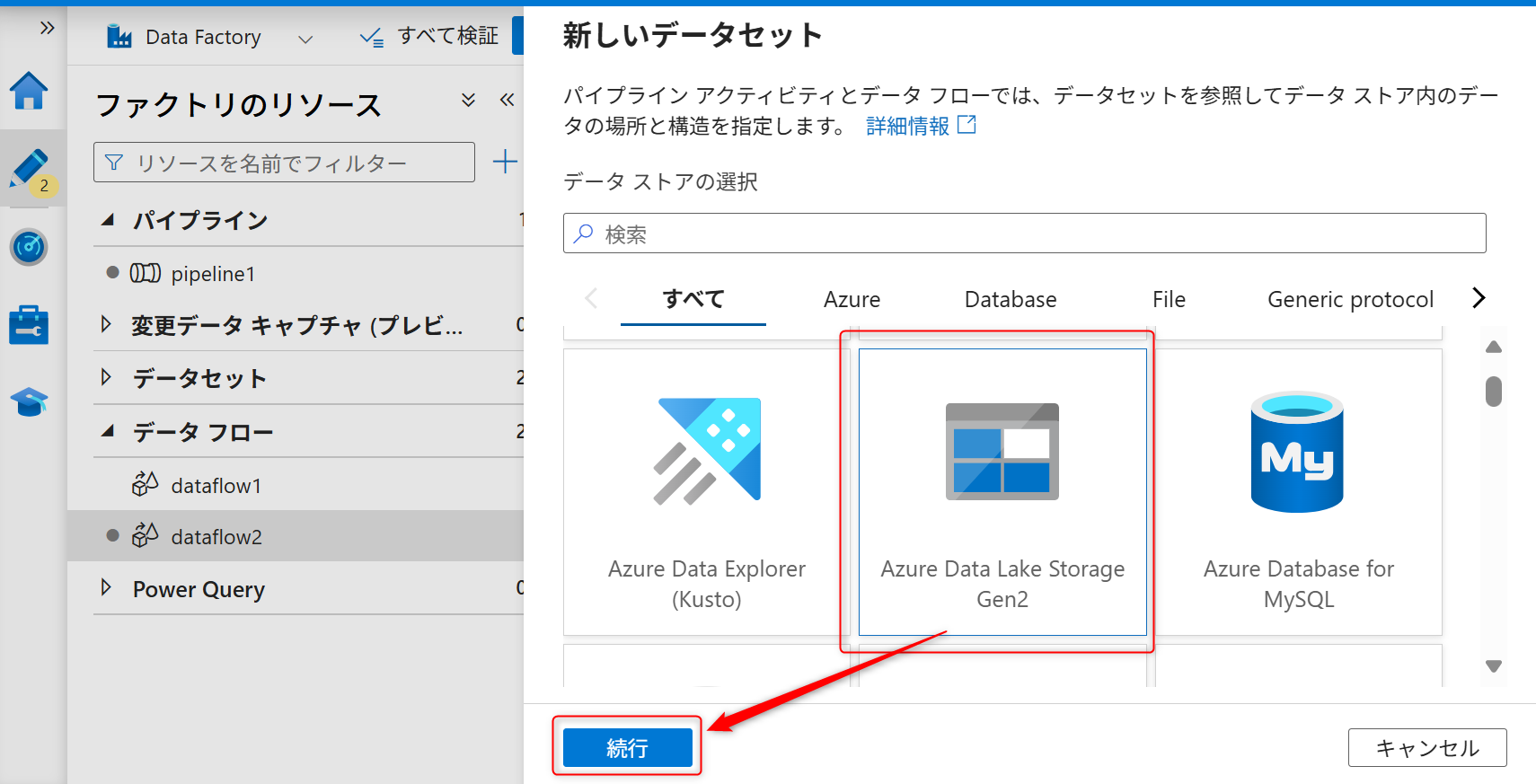
サービスはAzure Data Lake Storage Gen2を選択する。
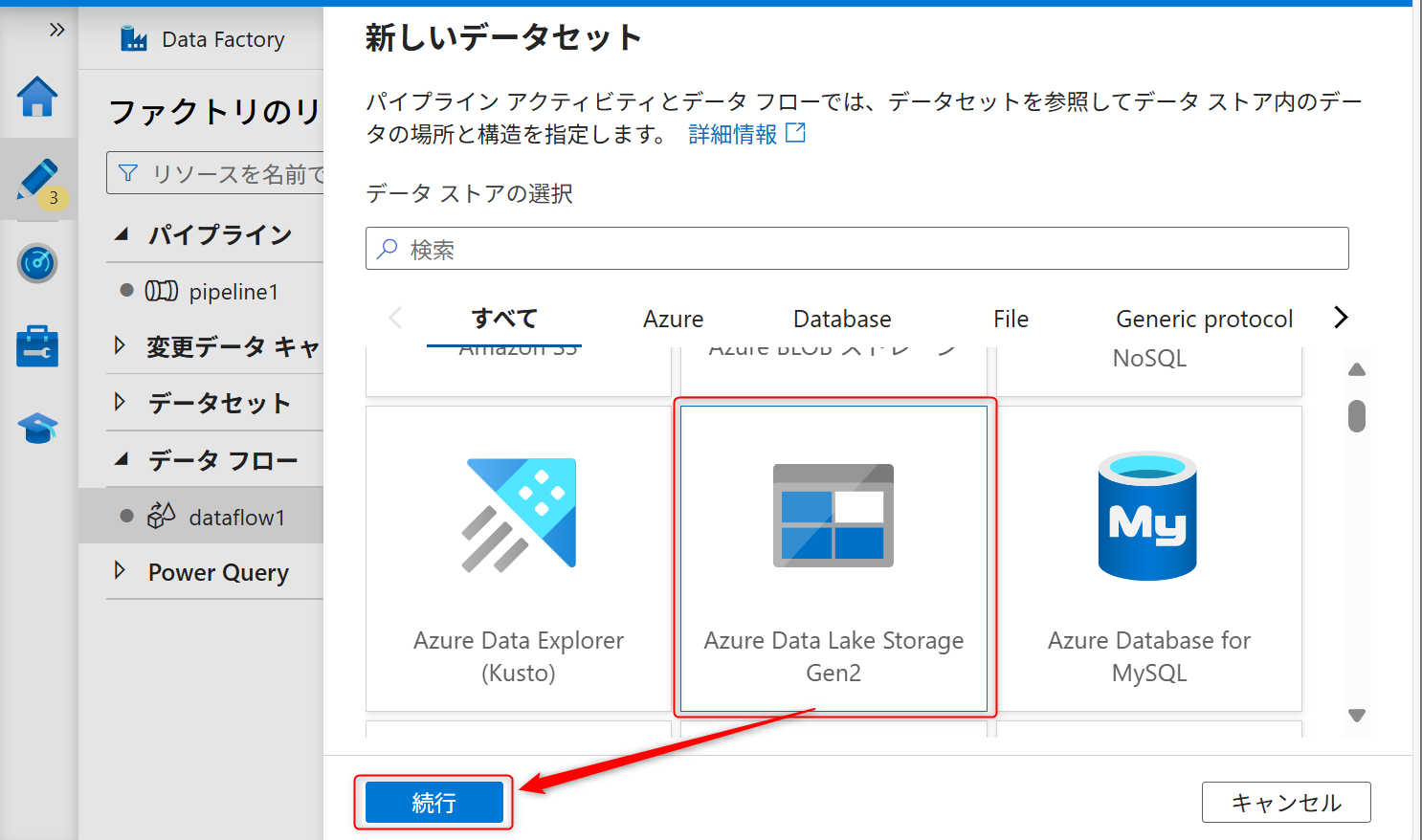
データの種類は「DelimitedText」を選択して、「続行」を選択する。
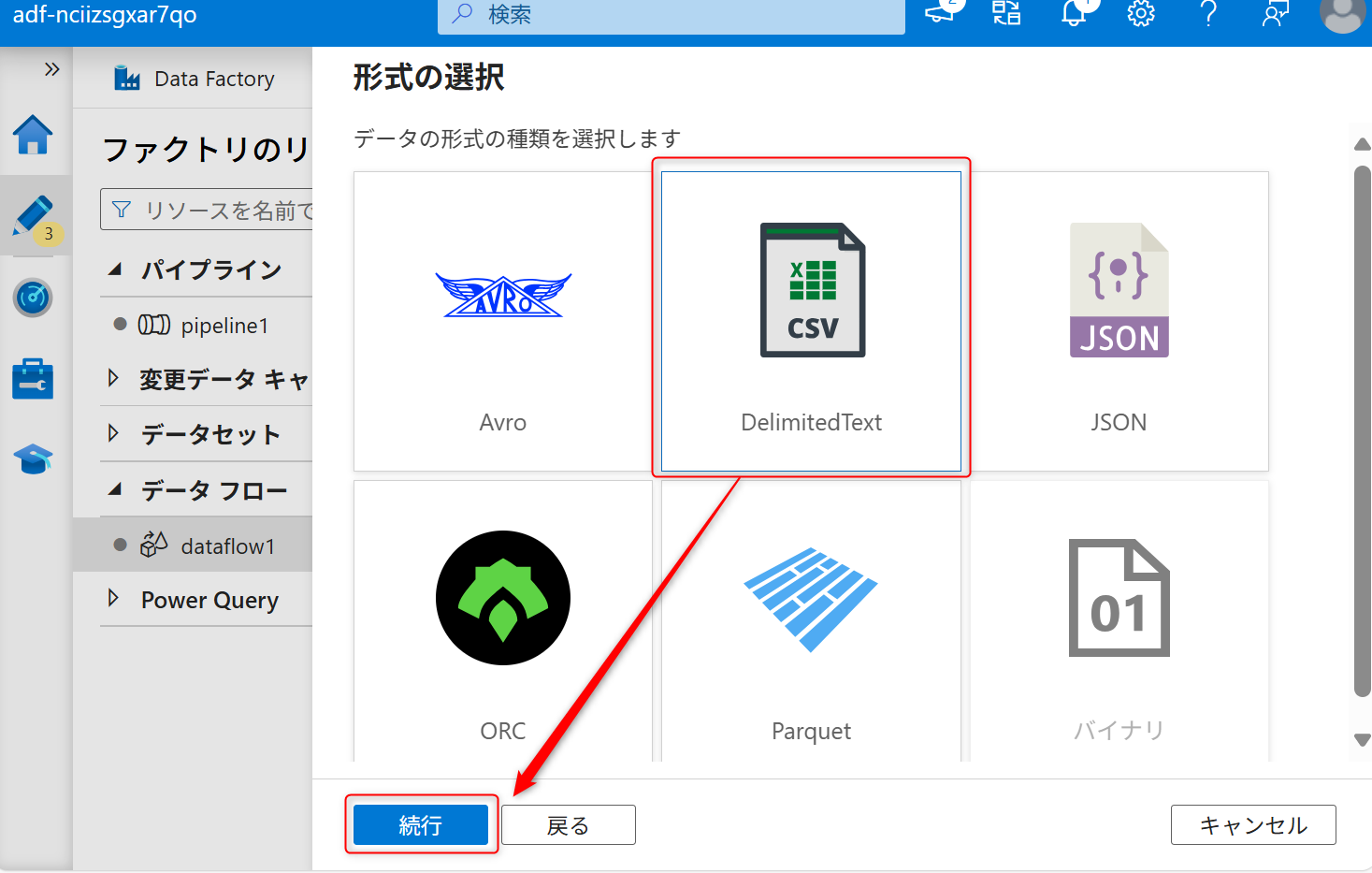
シンクも新しくリンクサービスを作成する。
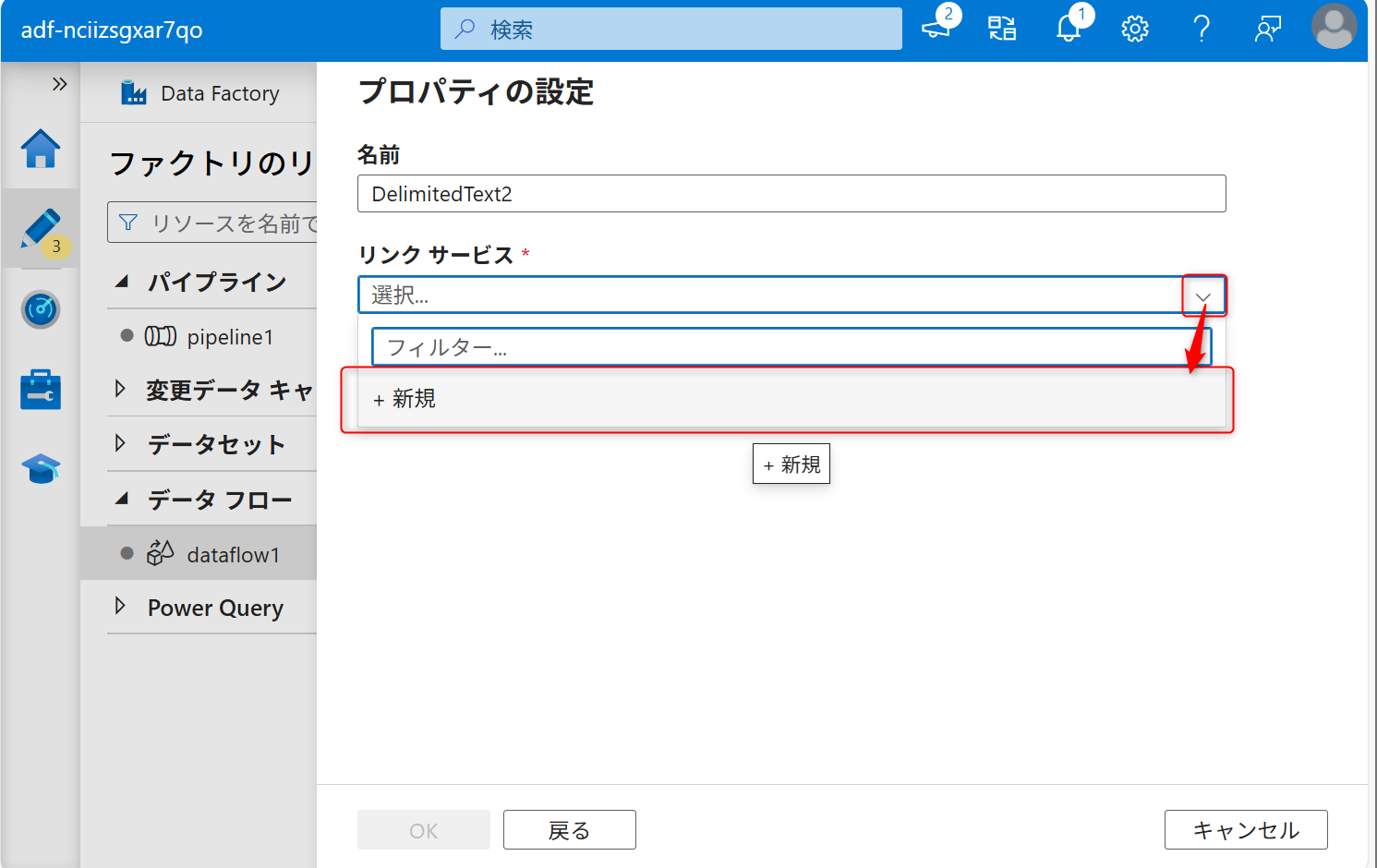
認証はシステム割り当てマネージドIDにし、データレイク機能として作成したAzure Data Lake Storage Gen2を選択する。その後、「作成」を選択する。
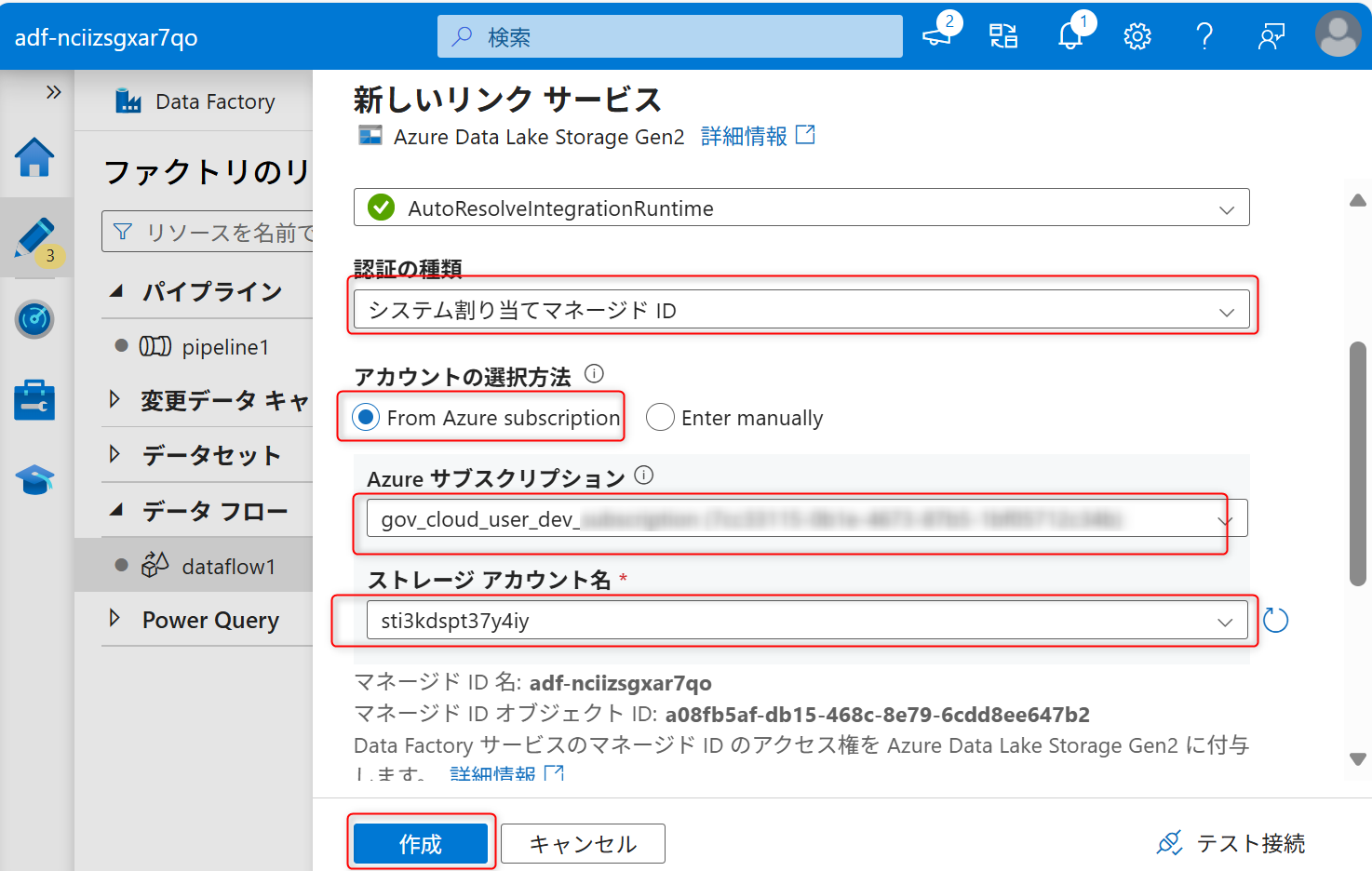
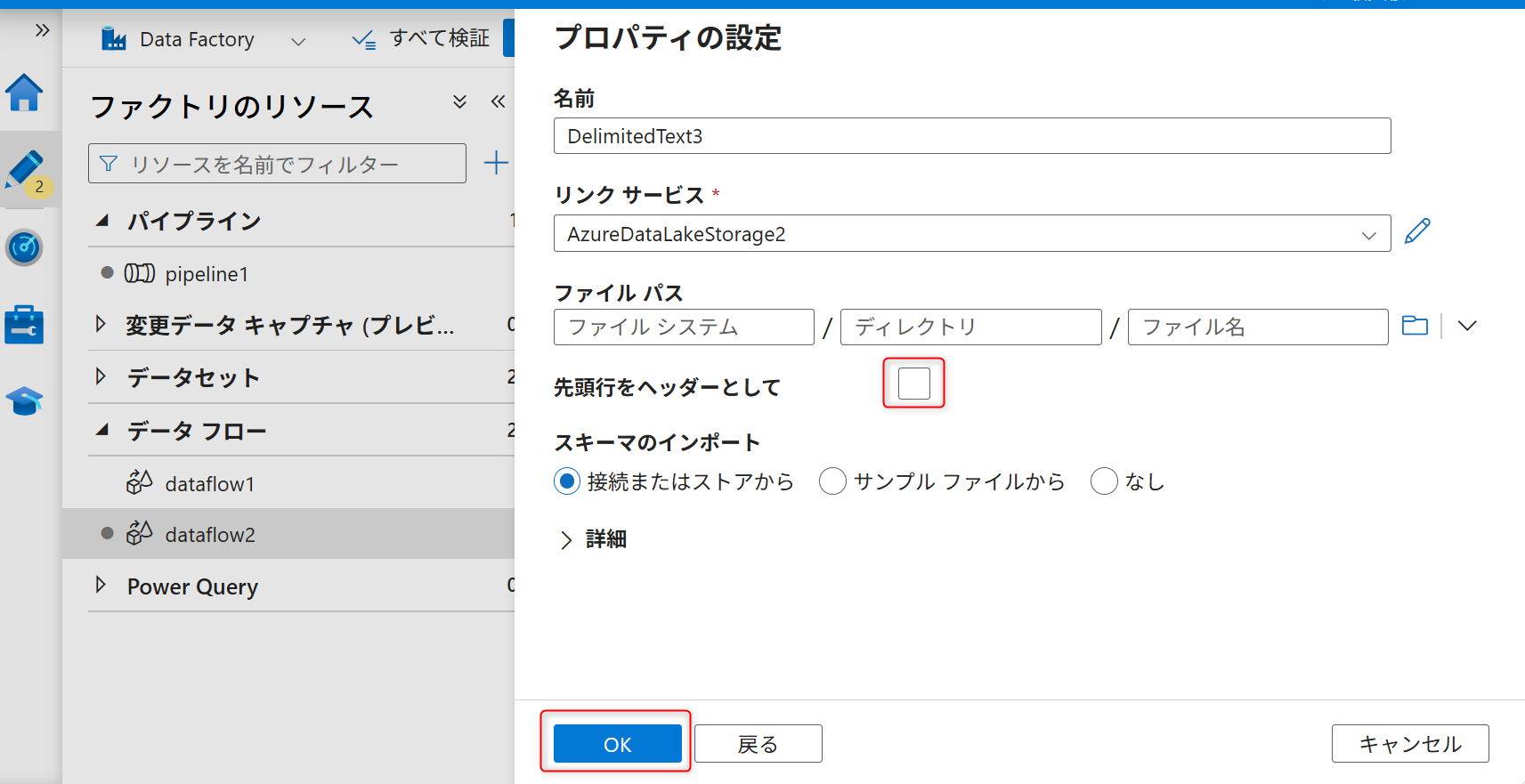
ファイルパスの設定でコンテナー名とフォルダ名を入力し、「先頭行をヘッダーとして」からチェックを外す。その後「OK」を選択する。
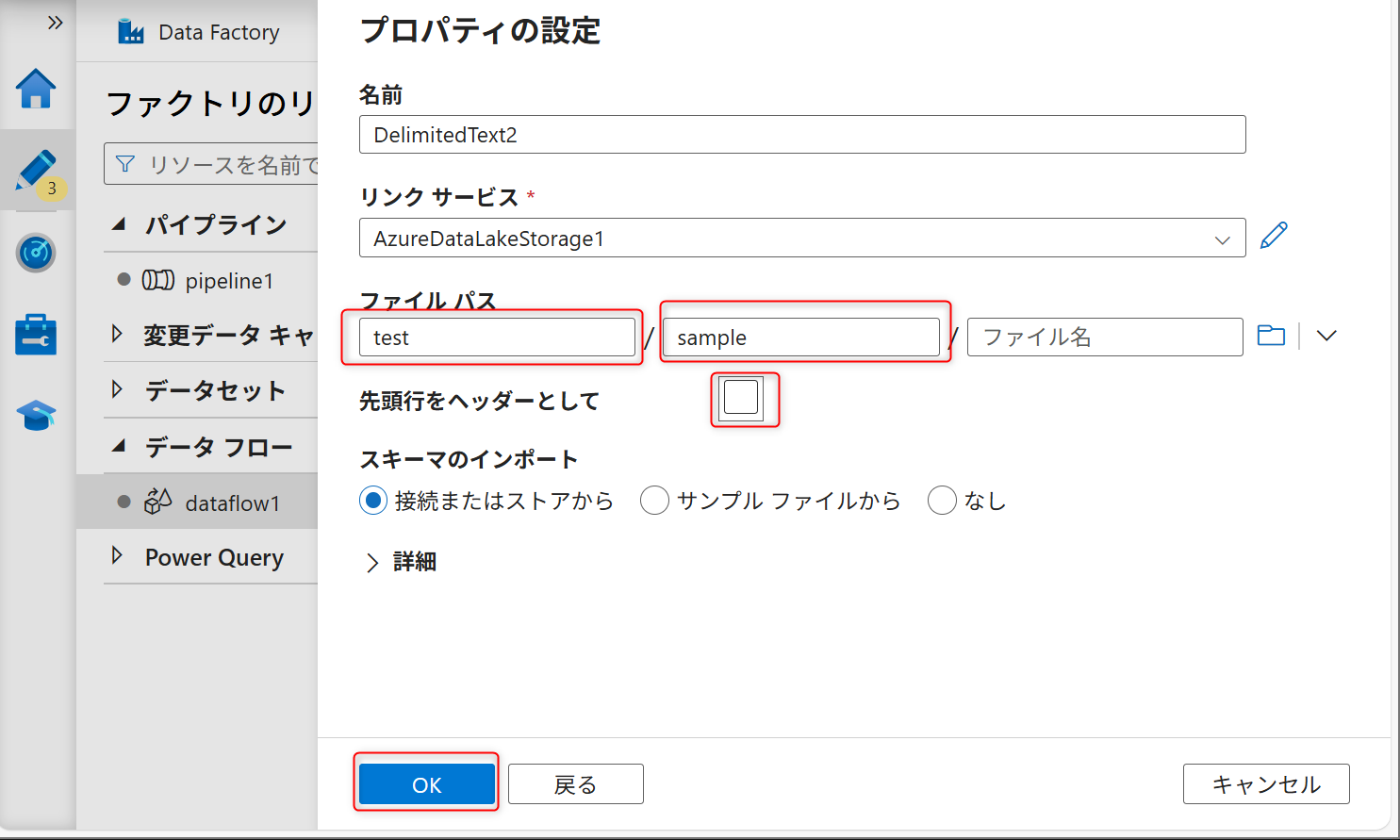
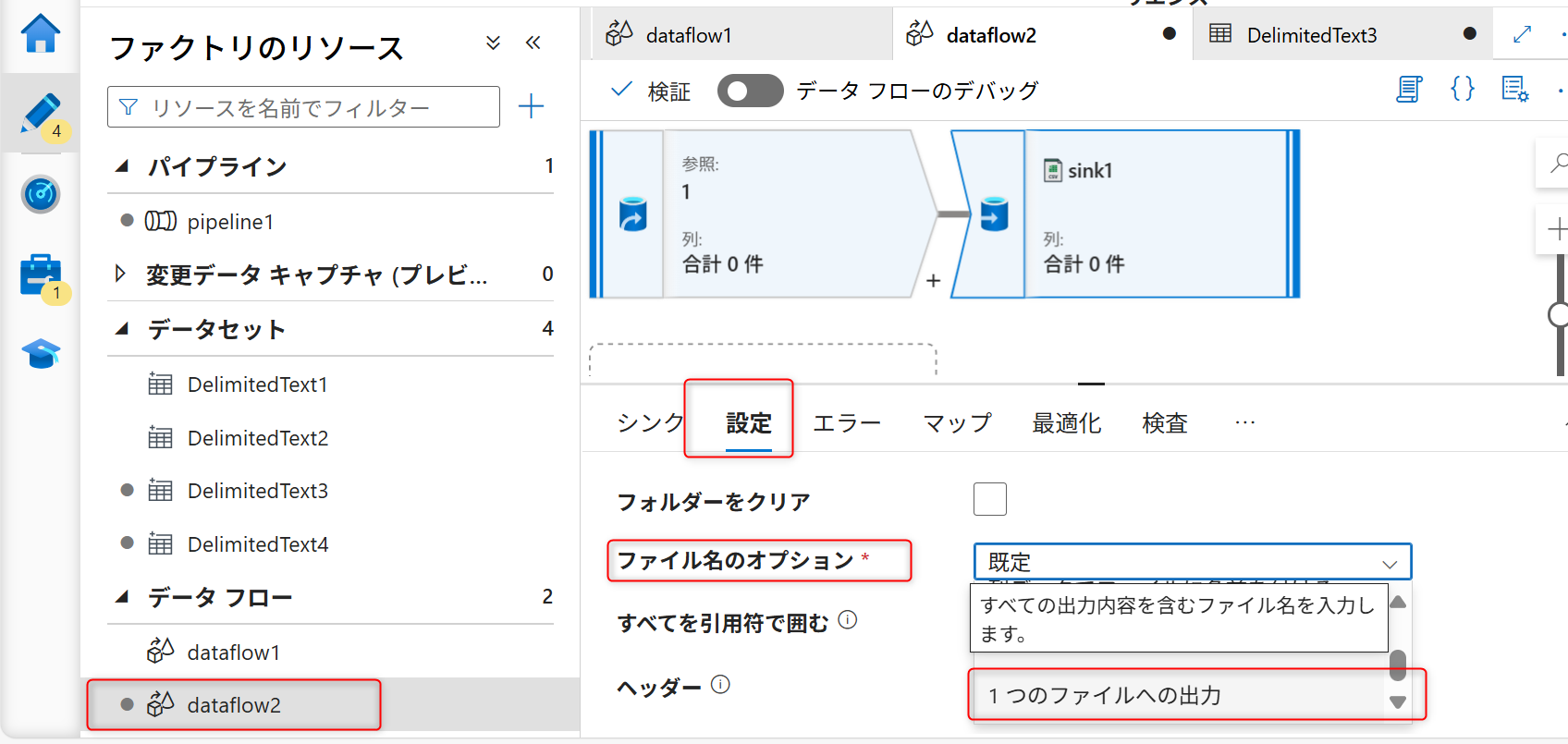
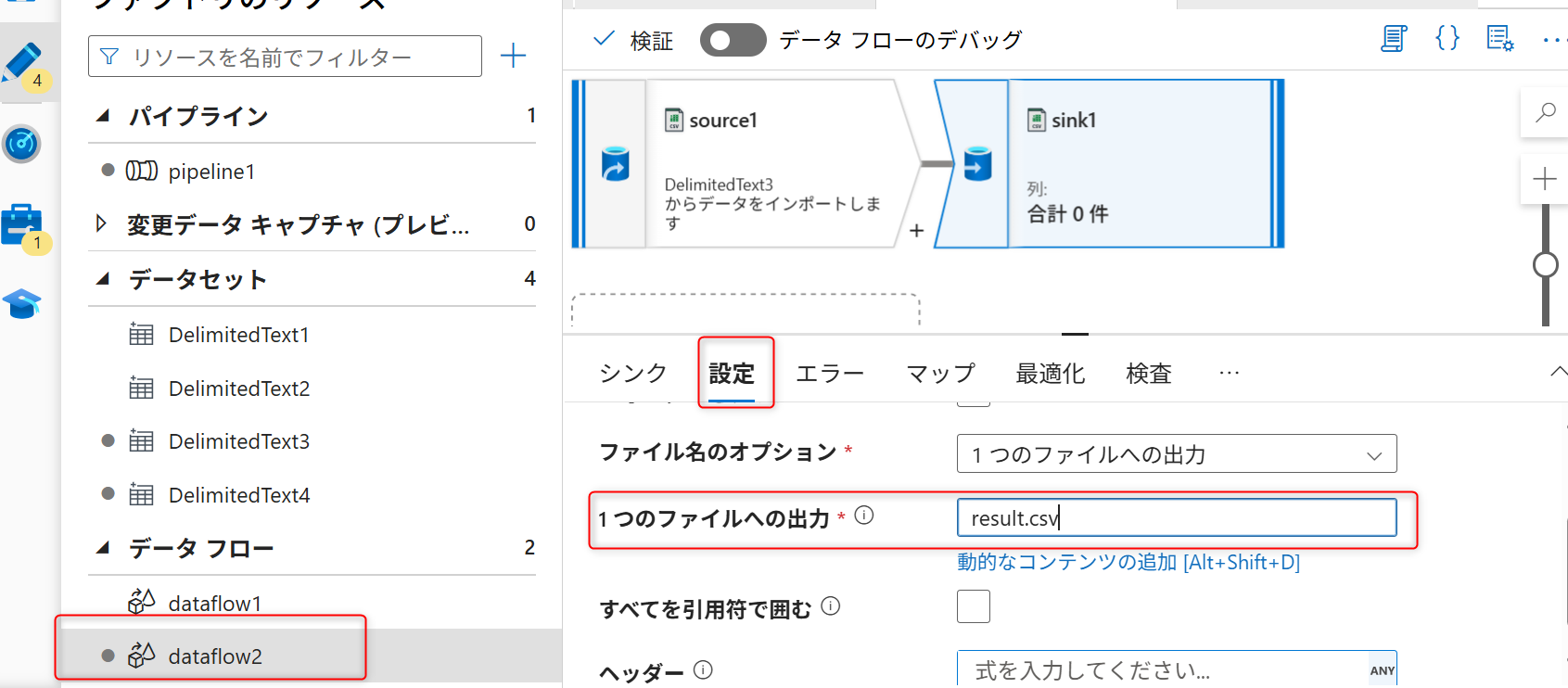
シンクへ保存されるデータのファイル名を指定する。データフローの設定画面のシンクの「設定」タブを開く。ファイル名のオプションを「1つのファイルへの出力」に変更する。
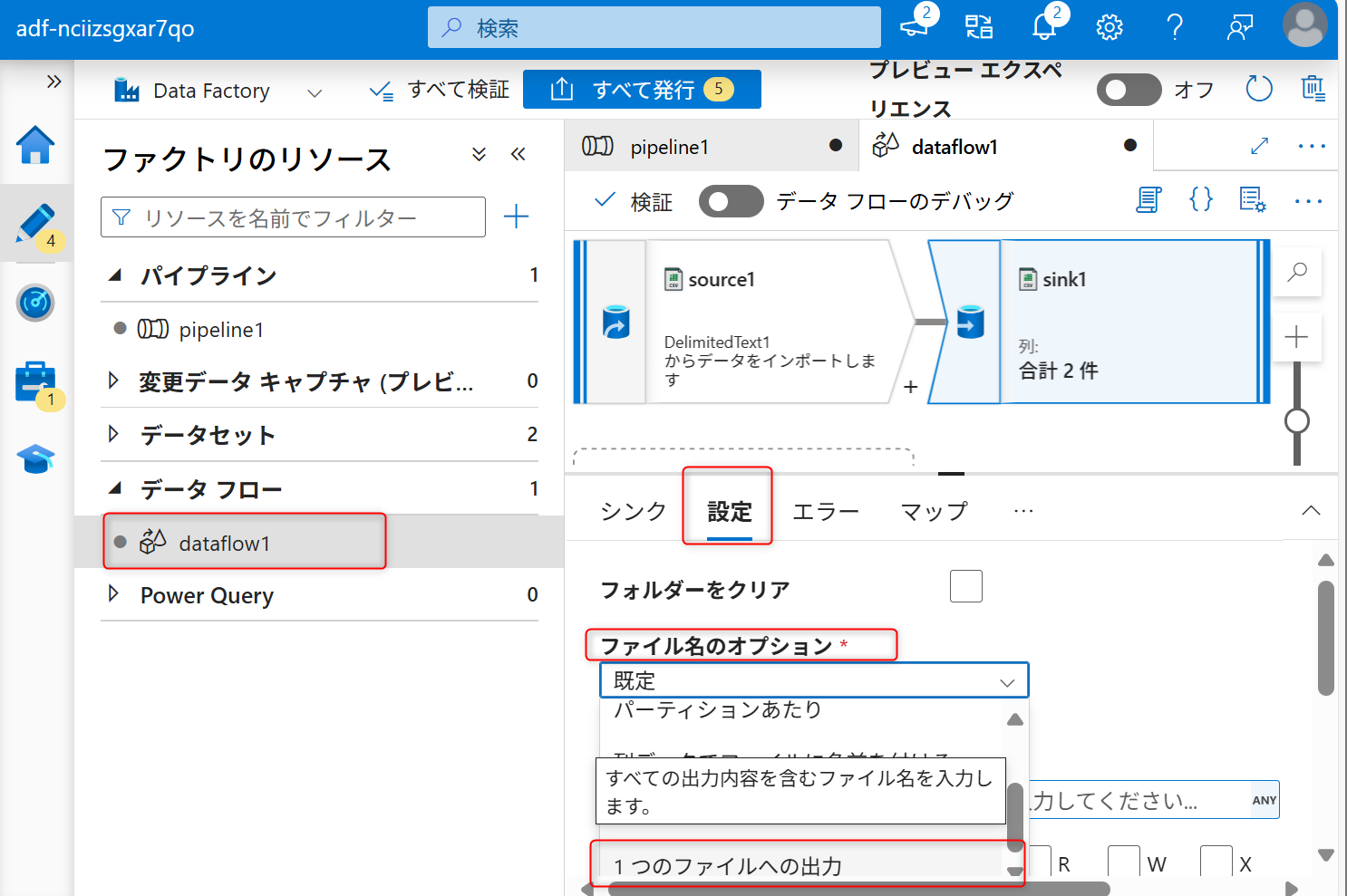
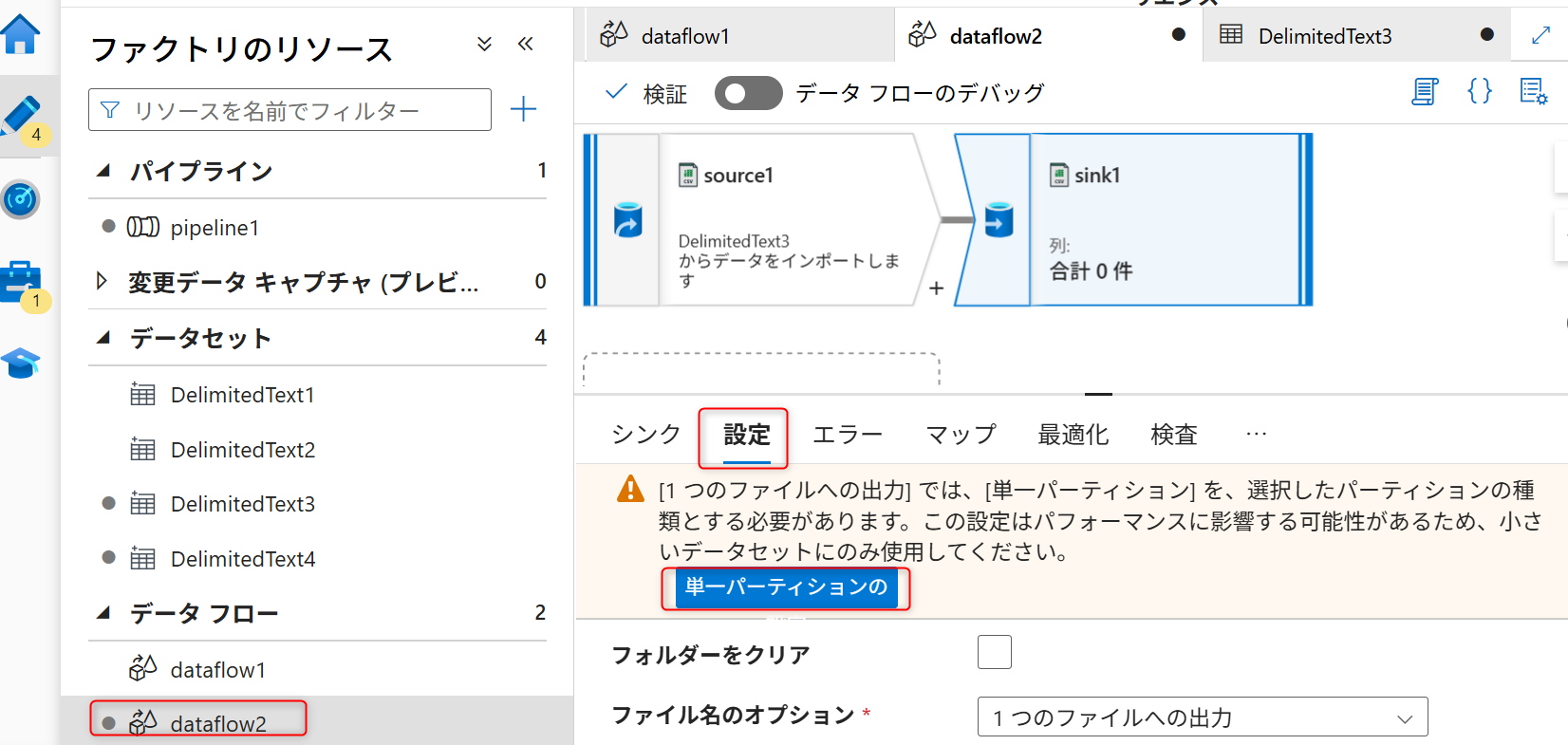
ファイル名のオプションを変更した際に図のような注意書きが表示される。「単一パーティションの」を選択する。
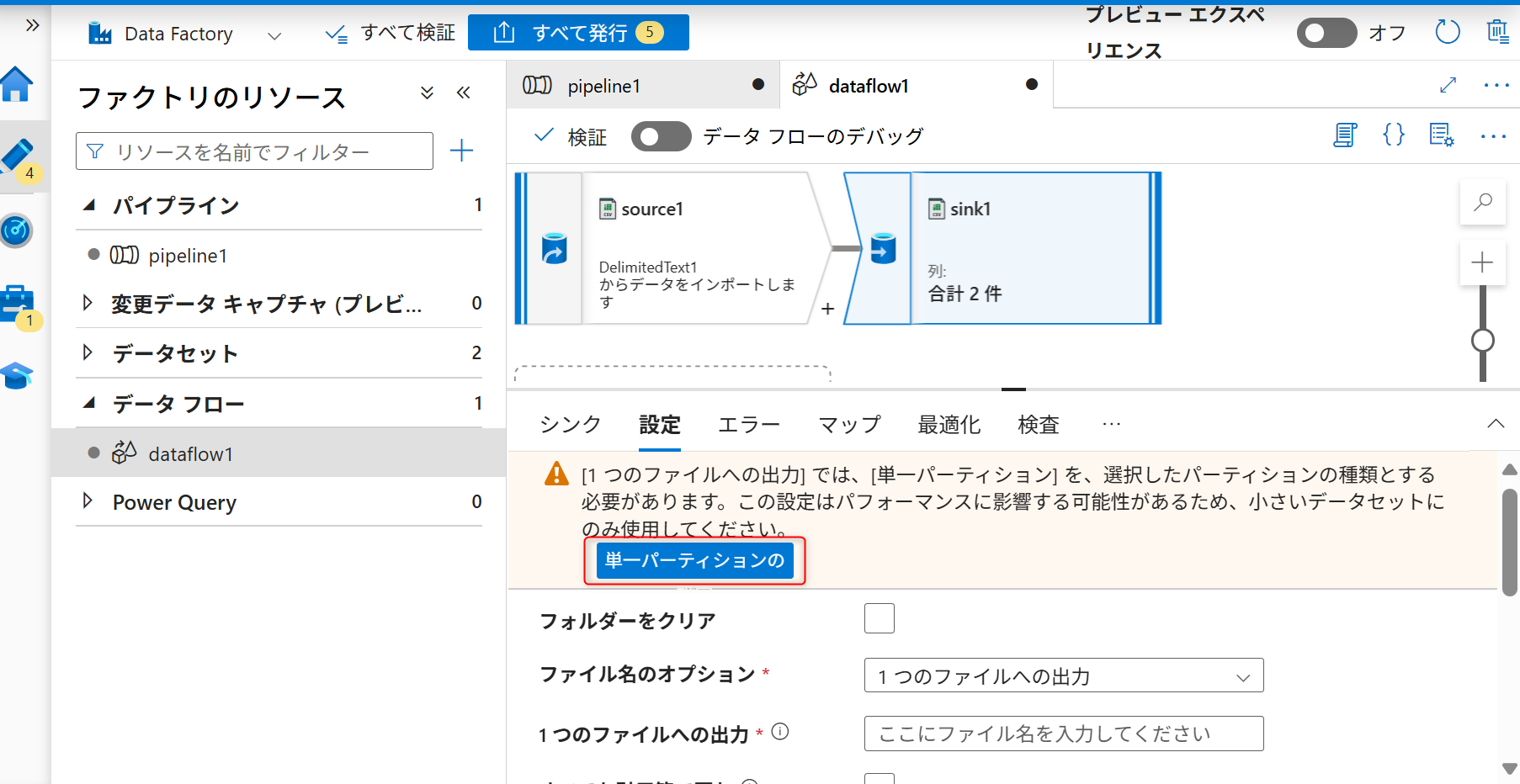
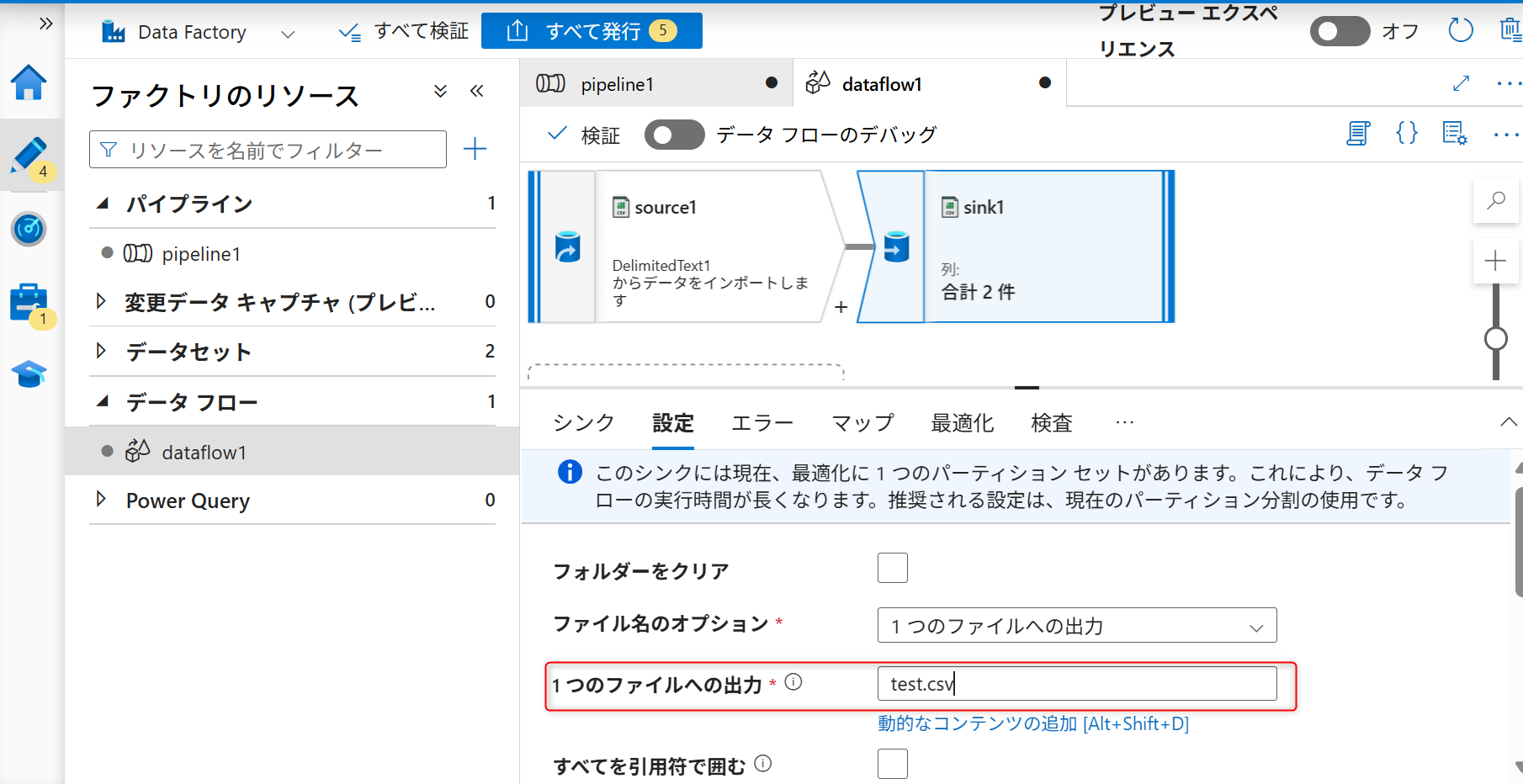
「一つのファイルへの出力」にAzure Data Lake Storage Gen2へ保存するデータファイル名を入力する(例では「test.csv」を指定する)。
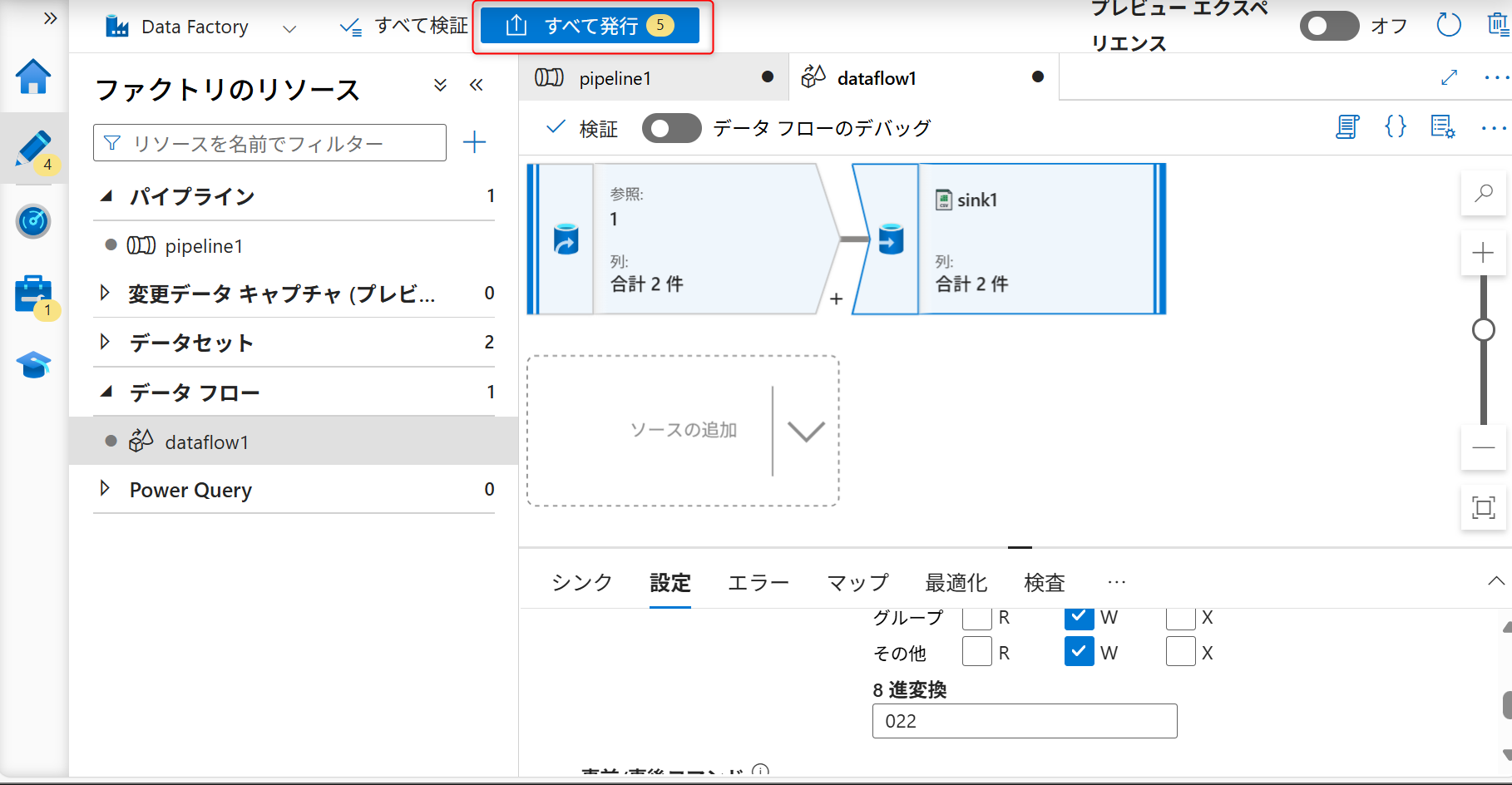
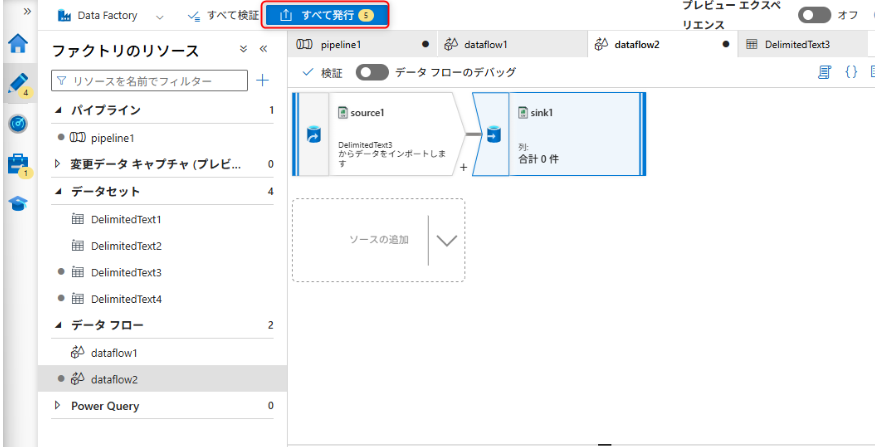
シンクの設定まで終えたら「すべて発行」を選択し、パイプライン上に作成したデータフローの構築内容を保存する。
Azure Data Lake Storage Gen2からオブジェクトストレージへ
先ほど作成したデータフローのアクティビティの下にもう一つ「データフロー」のアクティビティを追加する。パイプラインの設定画面に移動し、構成したデータフローの右下にある丸で囲まれた矢印ボタンをクリックして、「データフロー」をもう一つ追加する。

追加するアクティビティの種類は「データフロー」を選択する。
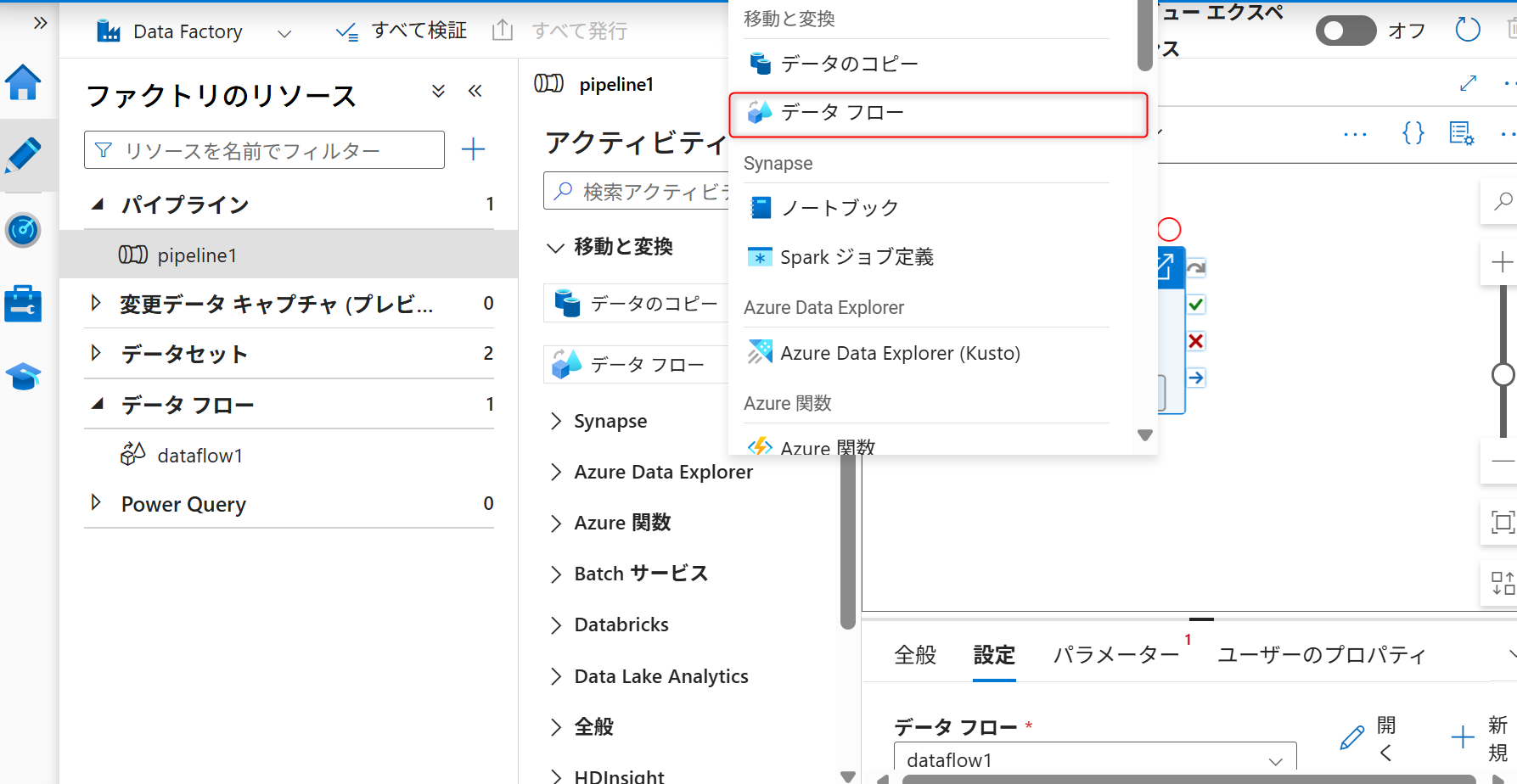
追加したデータフローのアクティビティを選択した状態で「設定」タブを開きデータフローを新規作成する。
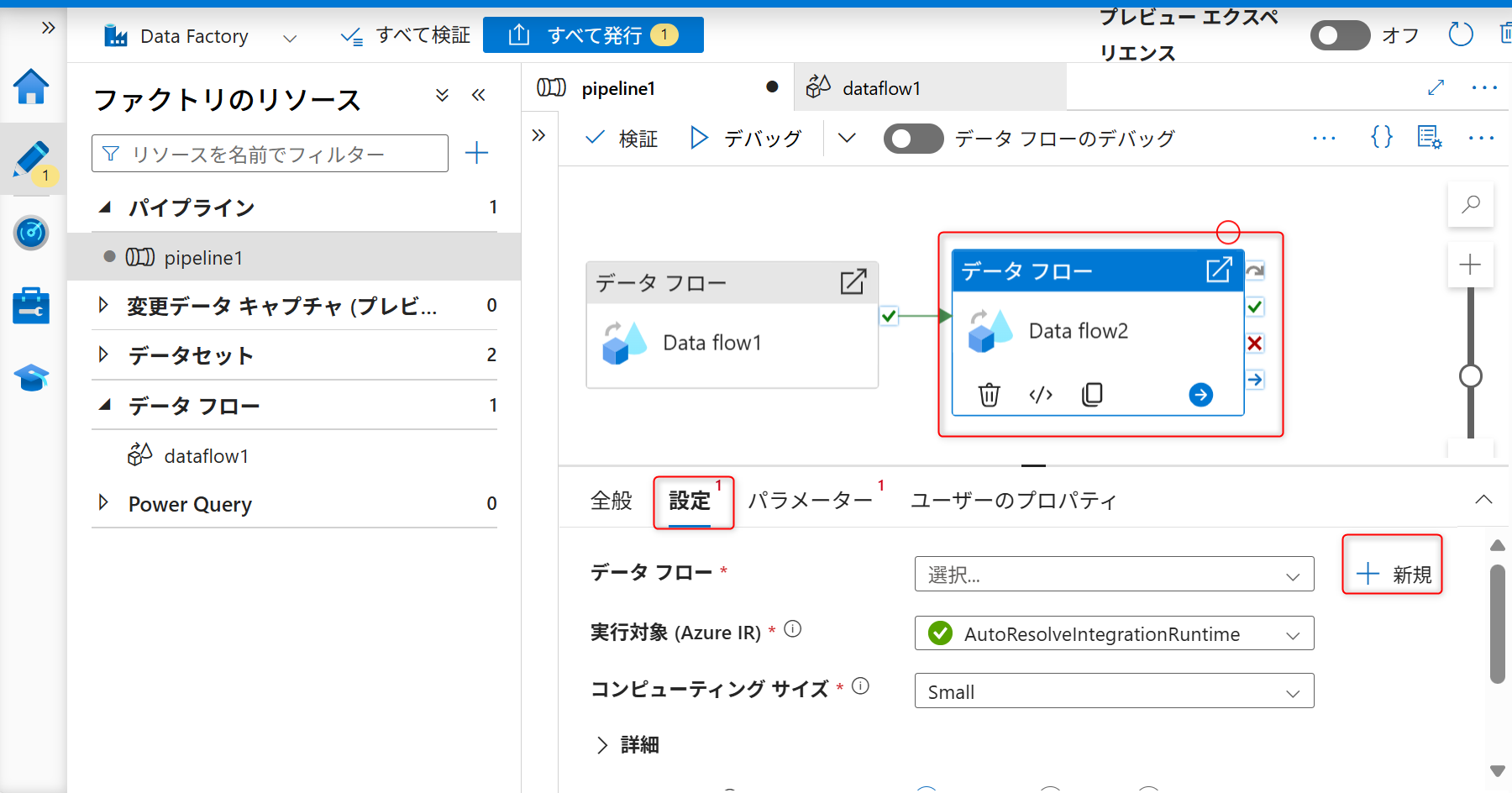
新規を選択すると「データフロー」の設定に移動する。ソースの追加と記載されてある部分の右側に表示されているソースの追加ボタン(右側の矢印アイコン)をクリックし、「ソースの追加」を選択する。
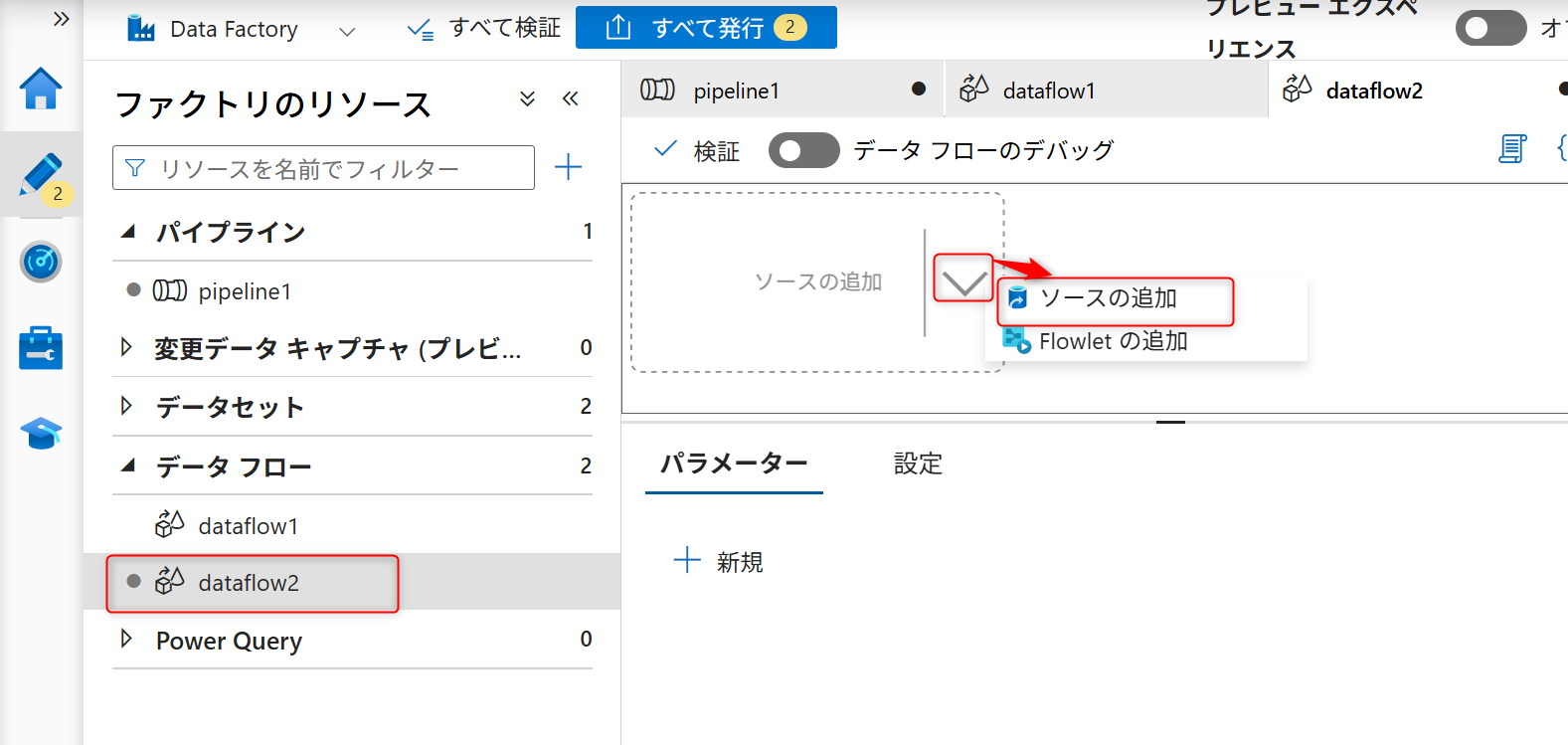
ソースの追加後、「ソースの設定」タブを開き、データセットの設定部分の「新規」を選択する。
サービスはAzure Data Lake Storage Gen2を選択する。
データの種類は「DelimitedText」を選択して、「続行」を選択する。
ソースのリンクサービスを新しく作成する。
認証はシステム割り当てマネージドIDにし、データレイク機能として作成したAzure Data Lake Storage Gen2を選択する。

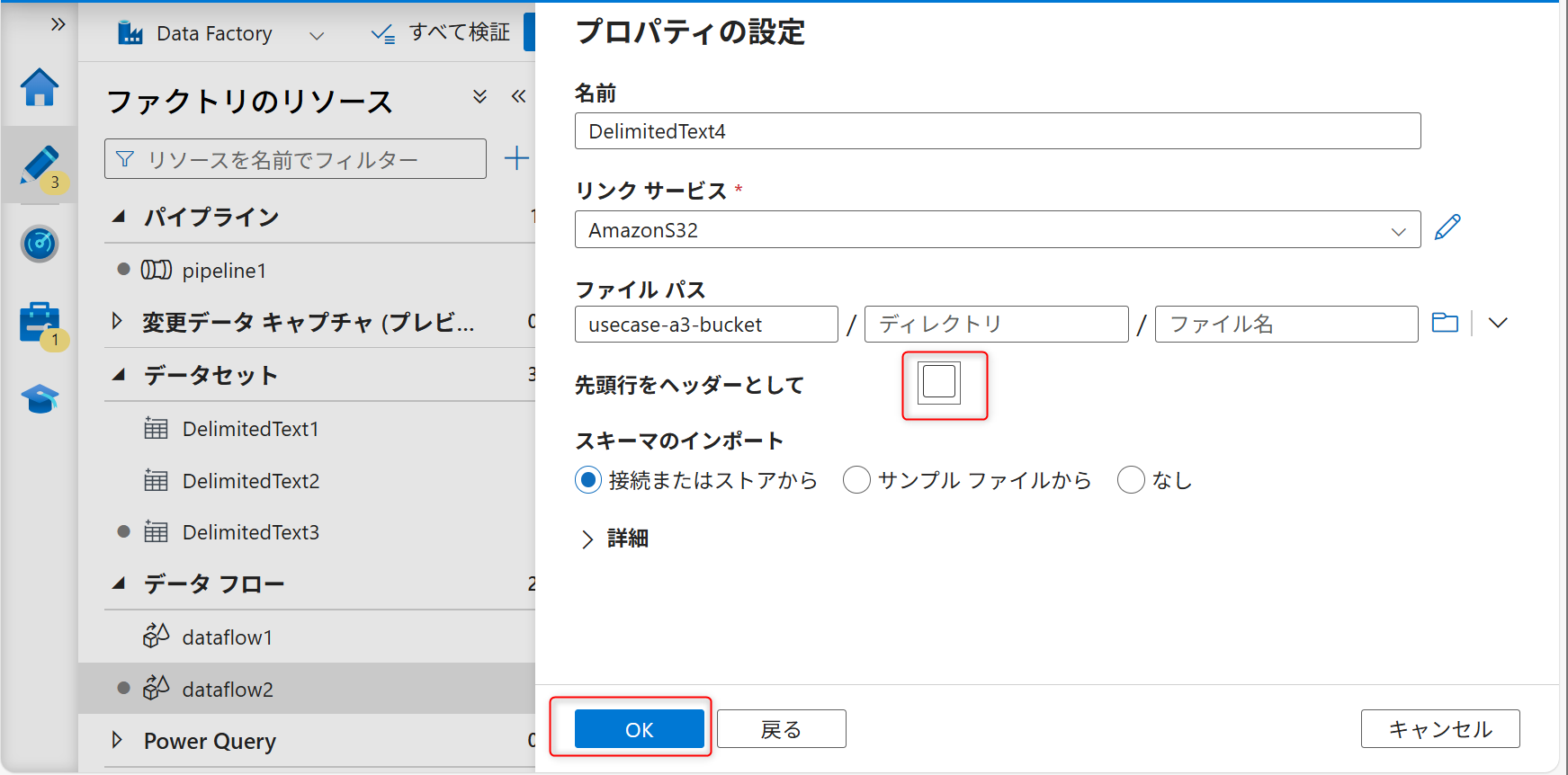
ファイルパスには何も入力せず、先頭行をヘッダーとしてからチェックを外し、「OK」を選択する。
新たに追加したデータセットの設定画面に移動し、「接続」のタブからファイルパスの設定でコンテナー名、ディレクトリ名、一つ目のデータフローで設定したさくらのオブジェクトストレージからAzure Data Lake Storage Gen2 に保存されるデータのファイル名を入力する。

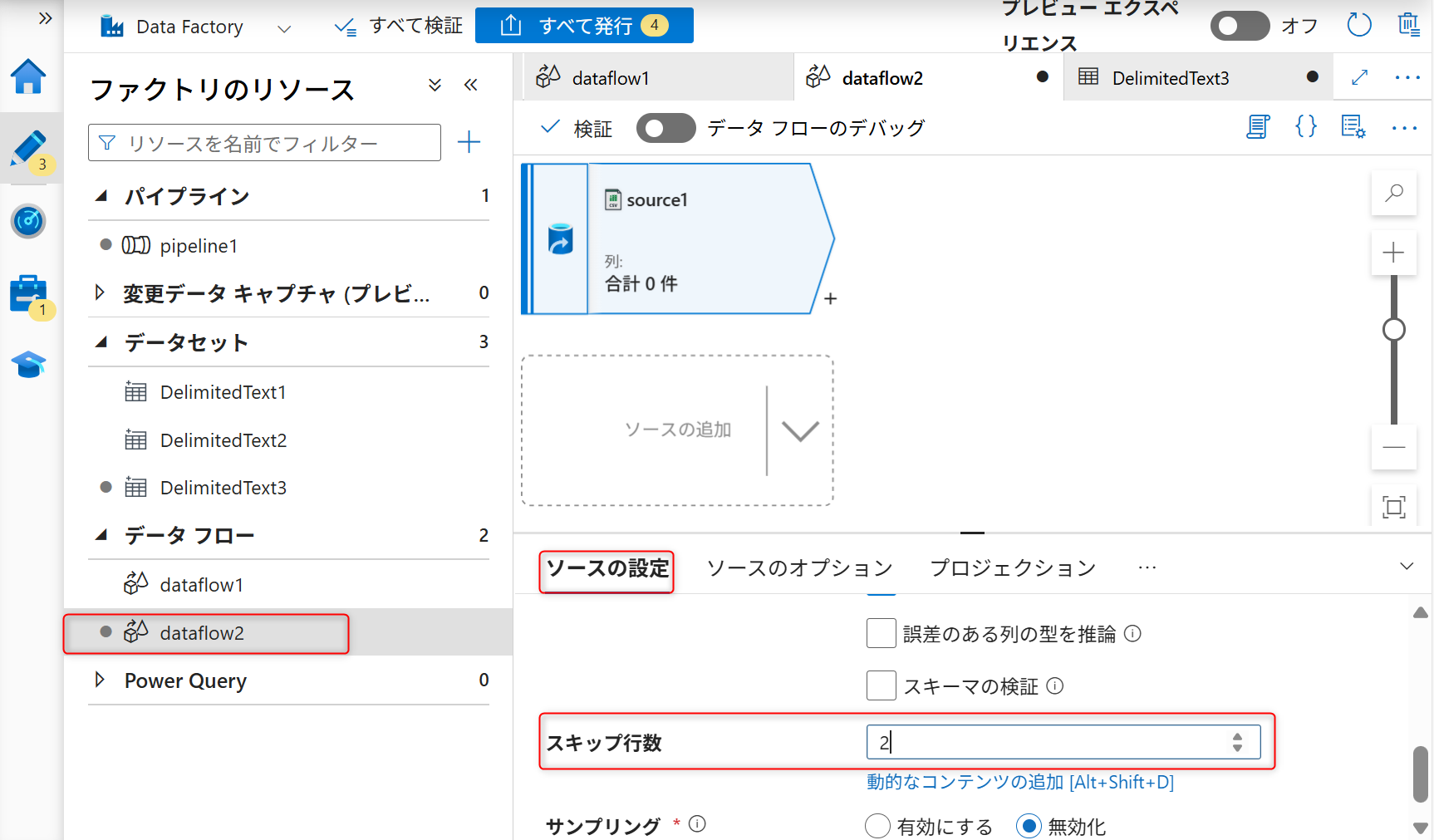
再度追加したデータフローの設定画面に移動する。データフローの設定画面より、「ソースの設定」を開く。2行スキップするように設定する。
続いて、シンク(格納先)の設定を行う。+ボタンを選択し、シンクを選択する。
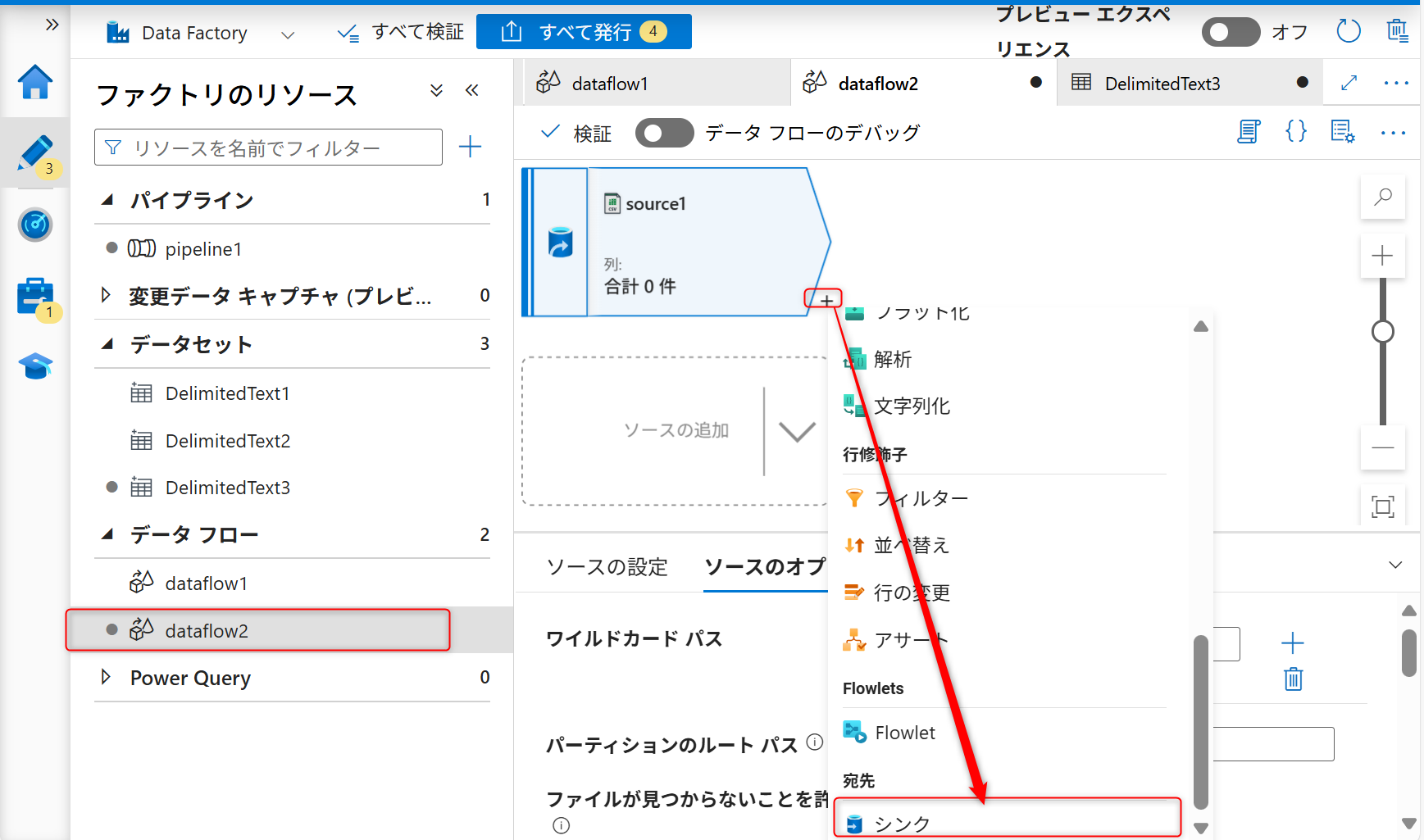
「シンク」タブからシンク用のデータセットを新規に作成する。

データセットは「Amazon S3」を選択して、「続行」を選択する。

データの種類は「DelimitedText」を選択して、「続行」を選択する。

シンクも新しくリンクサービスを作成する。
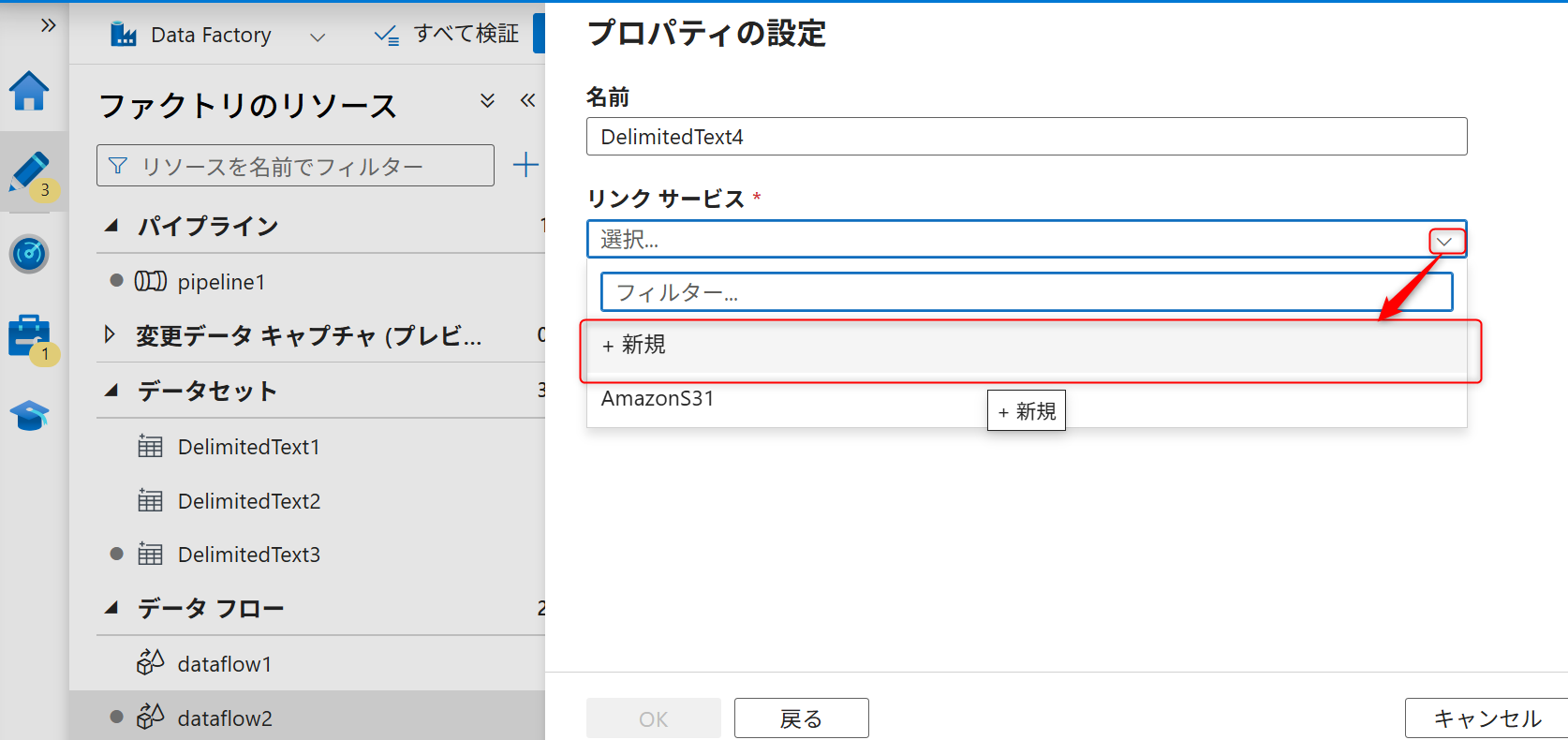
認証方法は「アクセスキー」を選択し、先ほど取得したオブジェクトストレージのバケットのパーミッションのアクセスキーID、シークレットアクセスキー、S3エンドポイントを入力する。
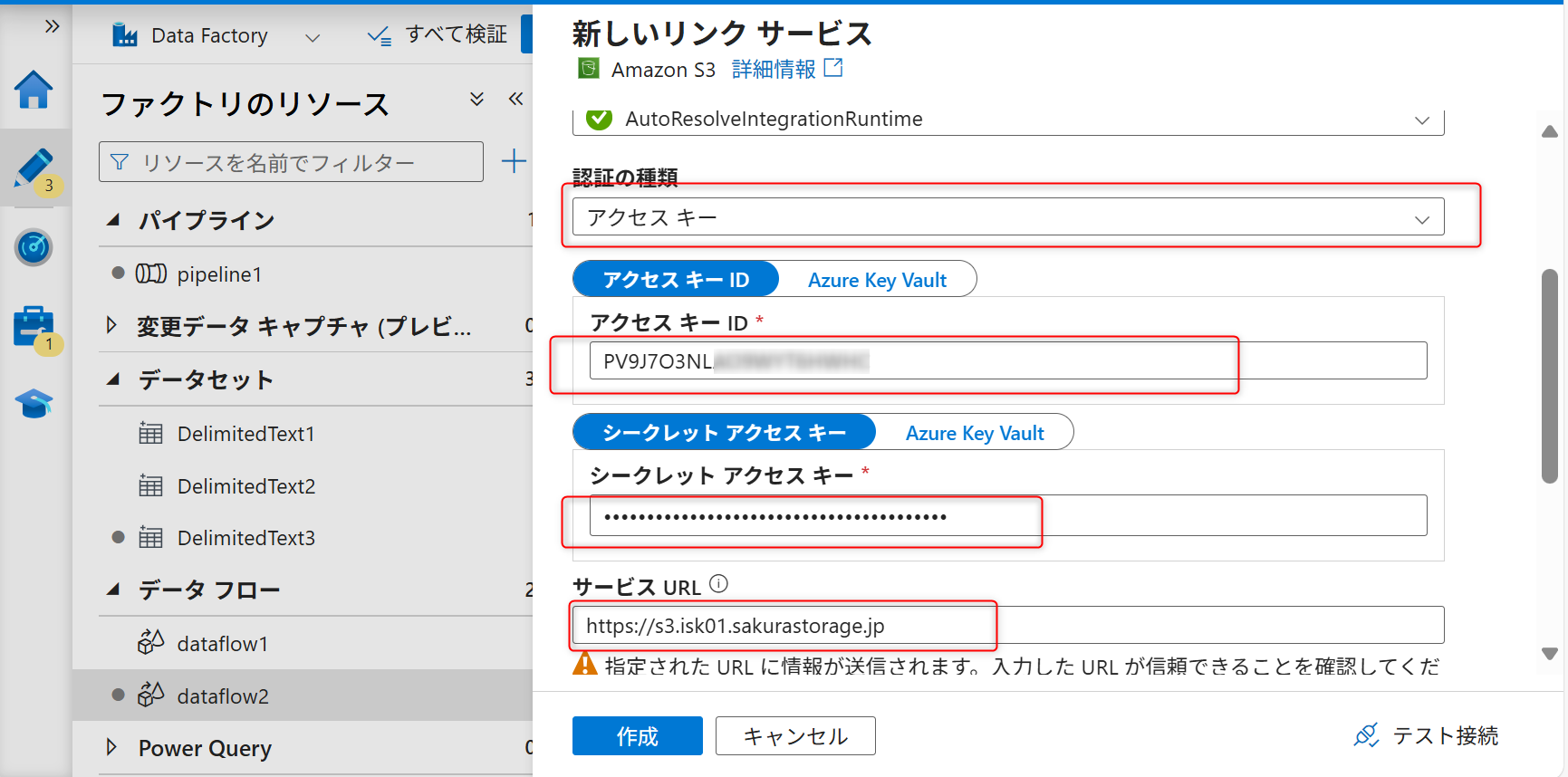
「宛先ファイルパス」を選択し、ファイルパスにバケット名を入力する。入力したら「作成」を選択する。

ファイルパスに再度バケット名を入力し、矢印ボタンを選択し、「指定されたパスから」を選択する。
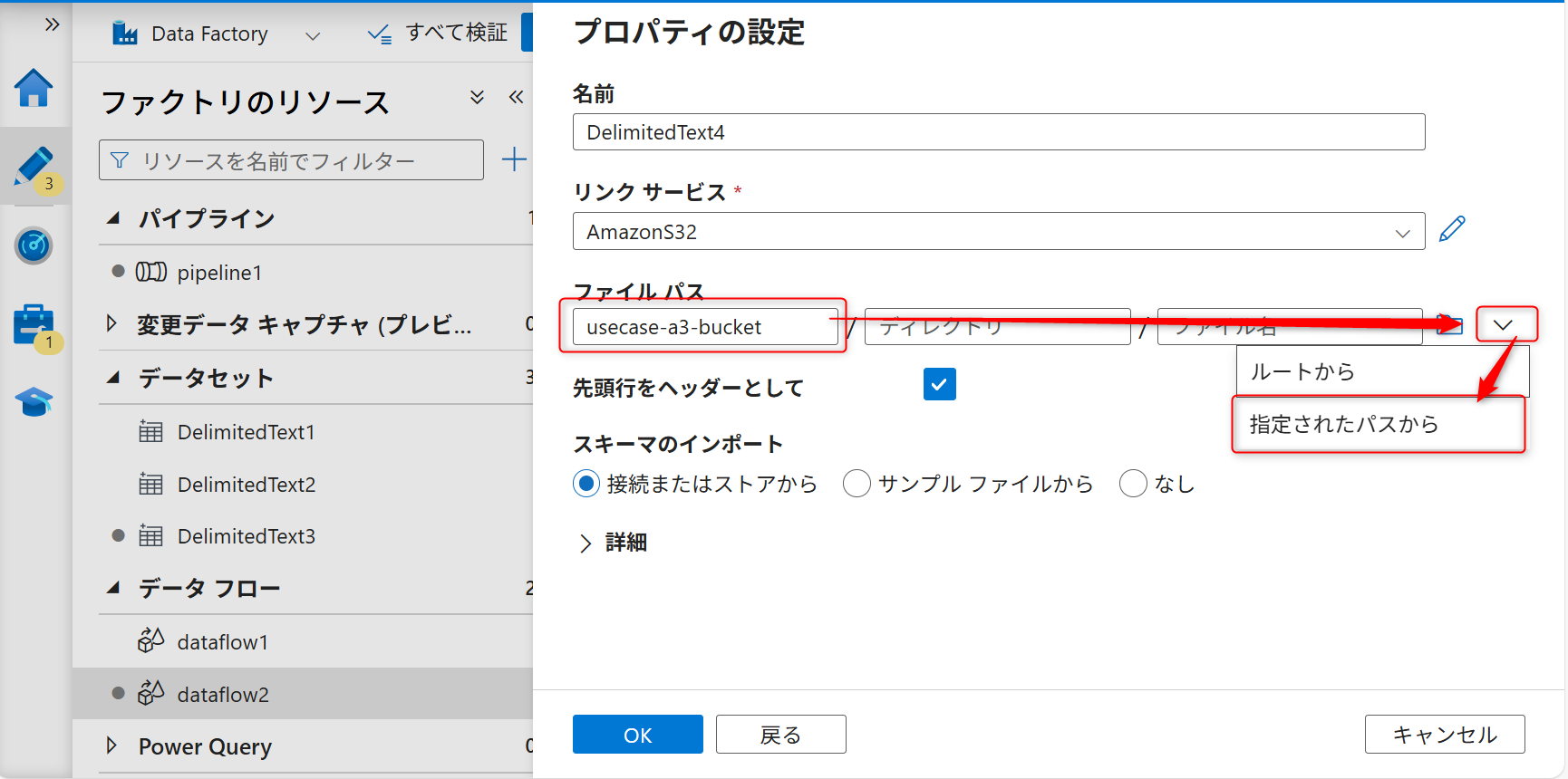
何も指定せずOKボタンをクリックする。
「先頭行をヘッダーとして」をチェックを外し、OKボタンをクリックする。
シンクのファイル名を以下のように設定する。
ファイル名のオプションを変更した際に図のような注意書きが表示される。「単一パーティションの」を選択する。
「一つのファイルへの出力」にAzure Data Lake Storage Gen2へ保存するデータファイル名を入力する(例では「result.csv」を指定する)。
全ての設定を完了したら発行ボタンをクリックする。
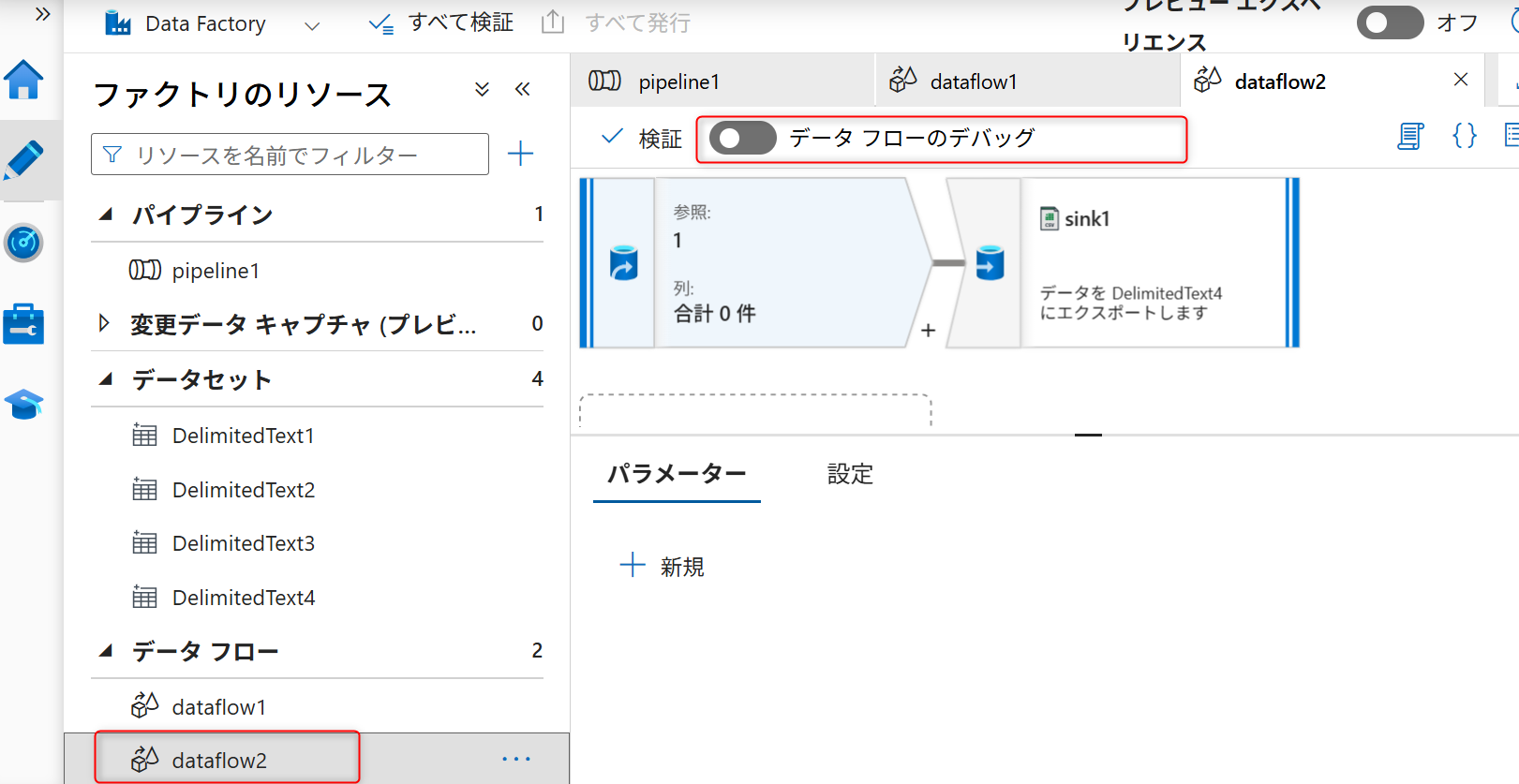
データフローの設定画面から「データフローのデバッグ」のトグルスイッチをオンにして、デバッグを有効化する。
デバッグフローが有効になったら、パイプラインの設定画面から「デバッグ」を実行する。
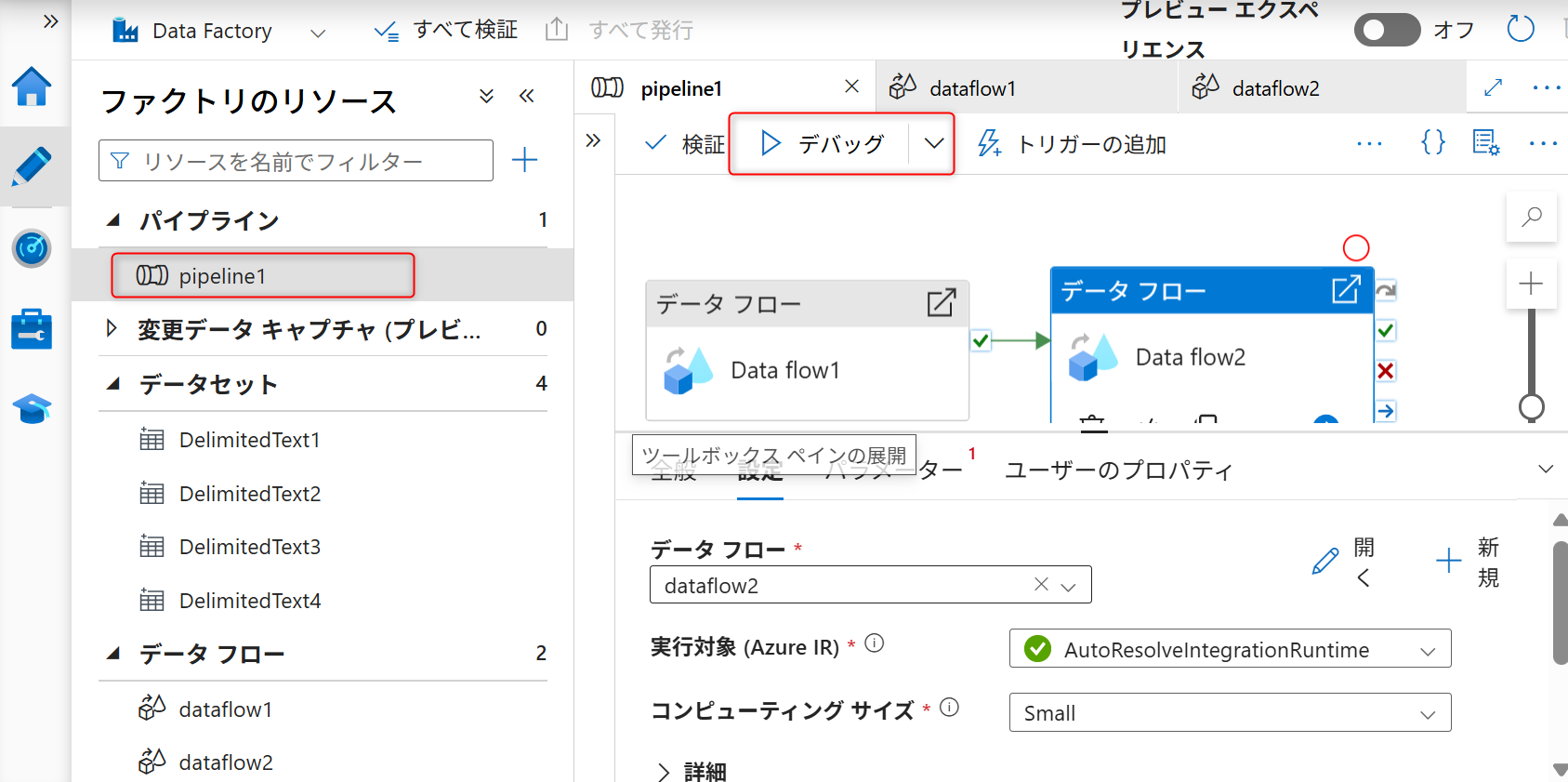
ウィンドウが表示されたら、「Integration Runtimeを使用する」を選択する。
実行後、さくらのオブジェクトストレージにデータが転送されていることを確認する。

関連情報:Azure Data Factory と Azure Synapse Analytics のパイプラインとアクティビティ
AWS CLIを利用したオブジェクトのダウンロード
オブジェクトストレージには、Amazon S3互換APIが搭載されており、対応したクライアントやツールによる操作が可能です。ここでは、AWS CLIの利用例を取り上げます。
以下コマンドを実行してオブジェクトをダウンロードし、ファイルを保存する。
aws --endpoint-url="https://s3.isk01.sakurastorage.jp" \ --profile sakura_s3 \ s3api get-object \ --bucket {バケット名} \ --key result.csv \ result.csv
ファイルを確認し、先頭12+2の計14行が元データから削除されていることを確認する。
重要
一部バージョンの AWS CLI および AWS SDK において、オブジェクトストレージが正常に利用できないことを確認しています。
詳細は以下のさくらのクラウドニュースをご確認ください。