検索
[更新:2026年07月30日]

高精度な全文検索や意味検索を実現するため、オブジェクトストレージとETL、AI検索を組み合わせます。必要な情報へ迅速にアクセスすることで、情報探索の効率化やナレッジ活用の向上を促し、業務スピードと生産性を大幅に高めます。
各機能のサービス対応
機能 |
対応サービス |
|---|---|
データレイク |
Azure Data Lake Storage Gen2 |
ETL/データ変換 |
Azure Data Factory |
検索 |
Azure AI Search |
システム構成要素
さくらのクラウド
オブジェクトストレージ
Addon
Azure Data Lake Storage Gen2
Azure Data Factory
Azure AI Search
構築手順
さくらのクラウドオブジェクトストレージでの事前準備
バケットの作成
さくらのクラウドのコントロールパネルにアクセスし、オブジェクトストレージからバケットを作成する。

バケットを新規作成する。バケット名は「
usecase-a4-bucket」とする。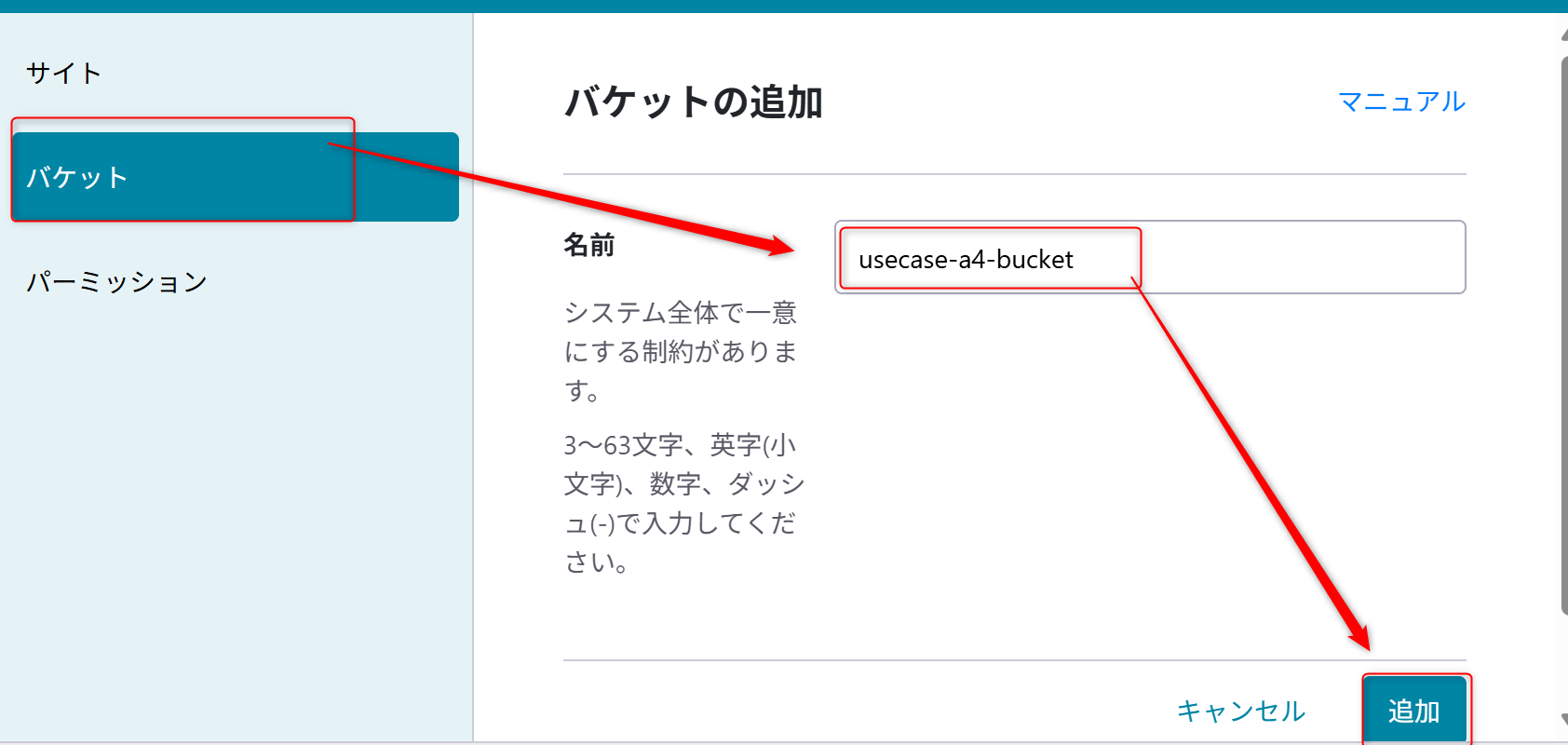
パーミッションの設定
後ほど Azure Data Factoryでオブジェクトストレージの内容を読み込むためにパーミッションを設定する。
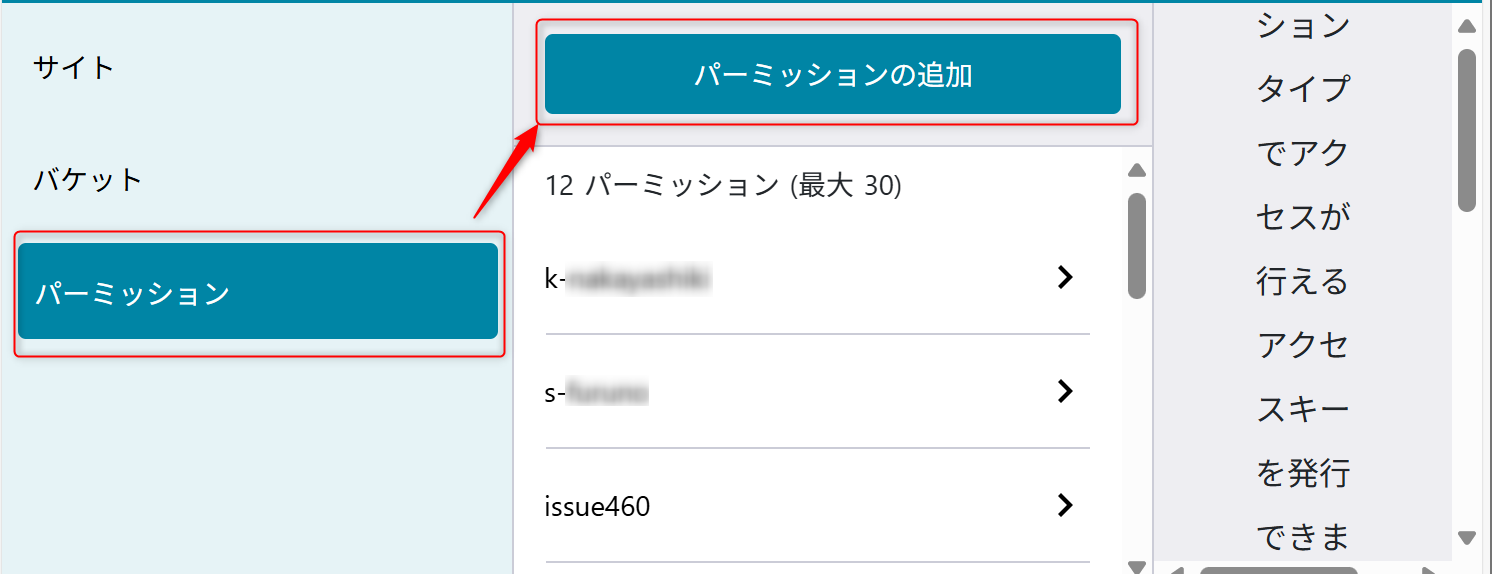
パーミッション名は「usecase-a4」を設定する。
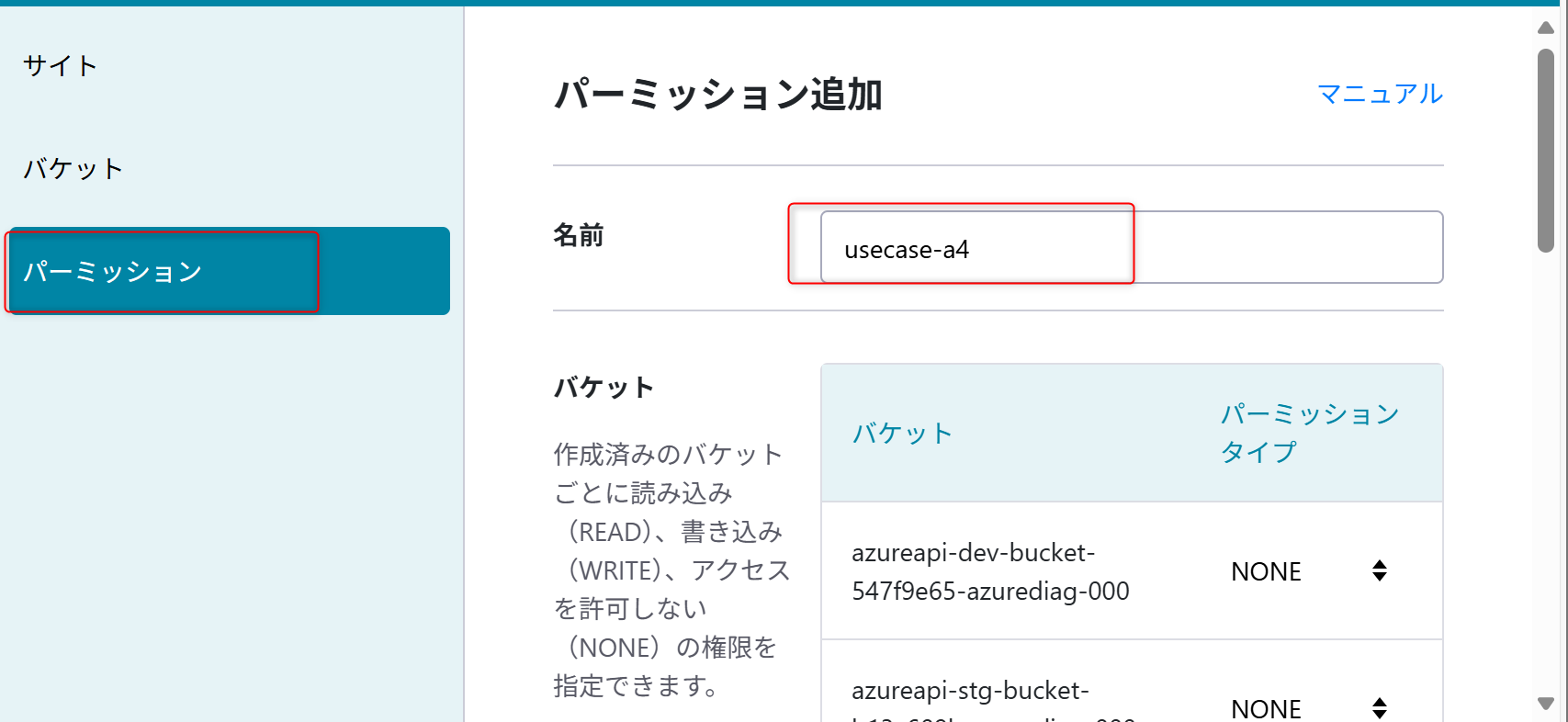
権限は「usecase-a4-bucket」の「READ/WRITE」を設定する。
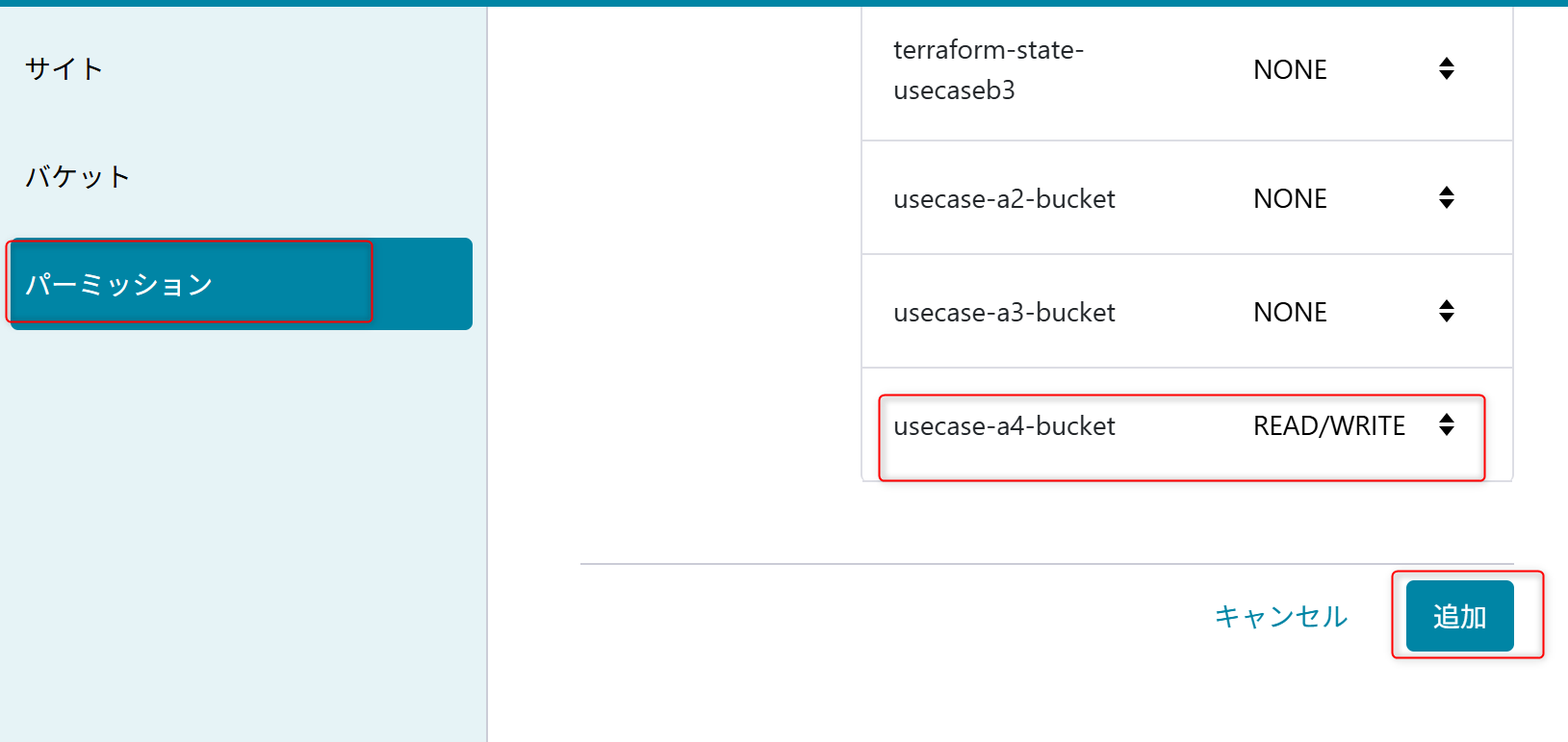
作成時に表示されるアクセスキーIDとシークレットアクセスキーを記録しておく。
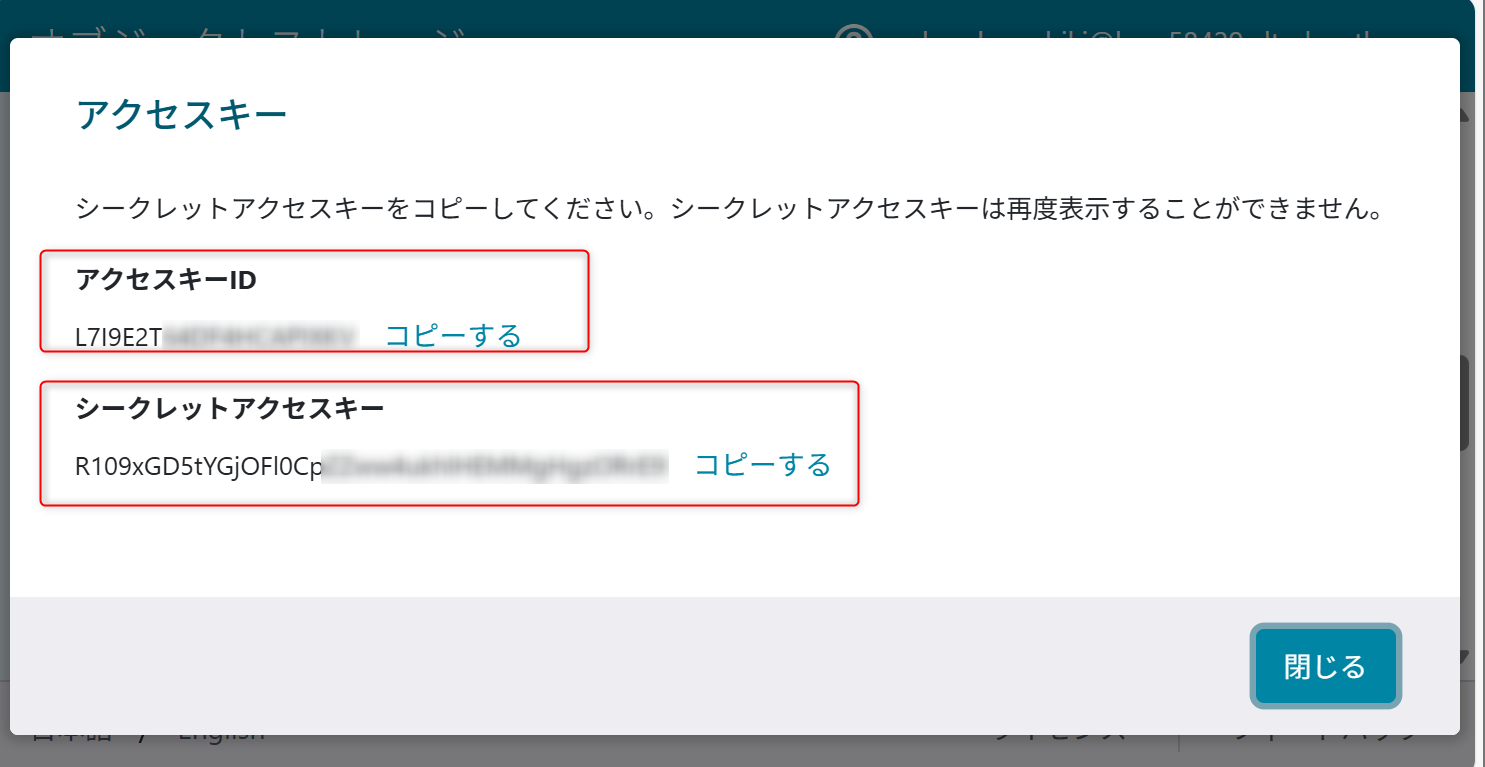
S3エンドポイントを利用するため、「サイト」から、「usecase-a4-bucket」のバケットを作成するサイトのS3エンドポイントの値を確認しておく。
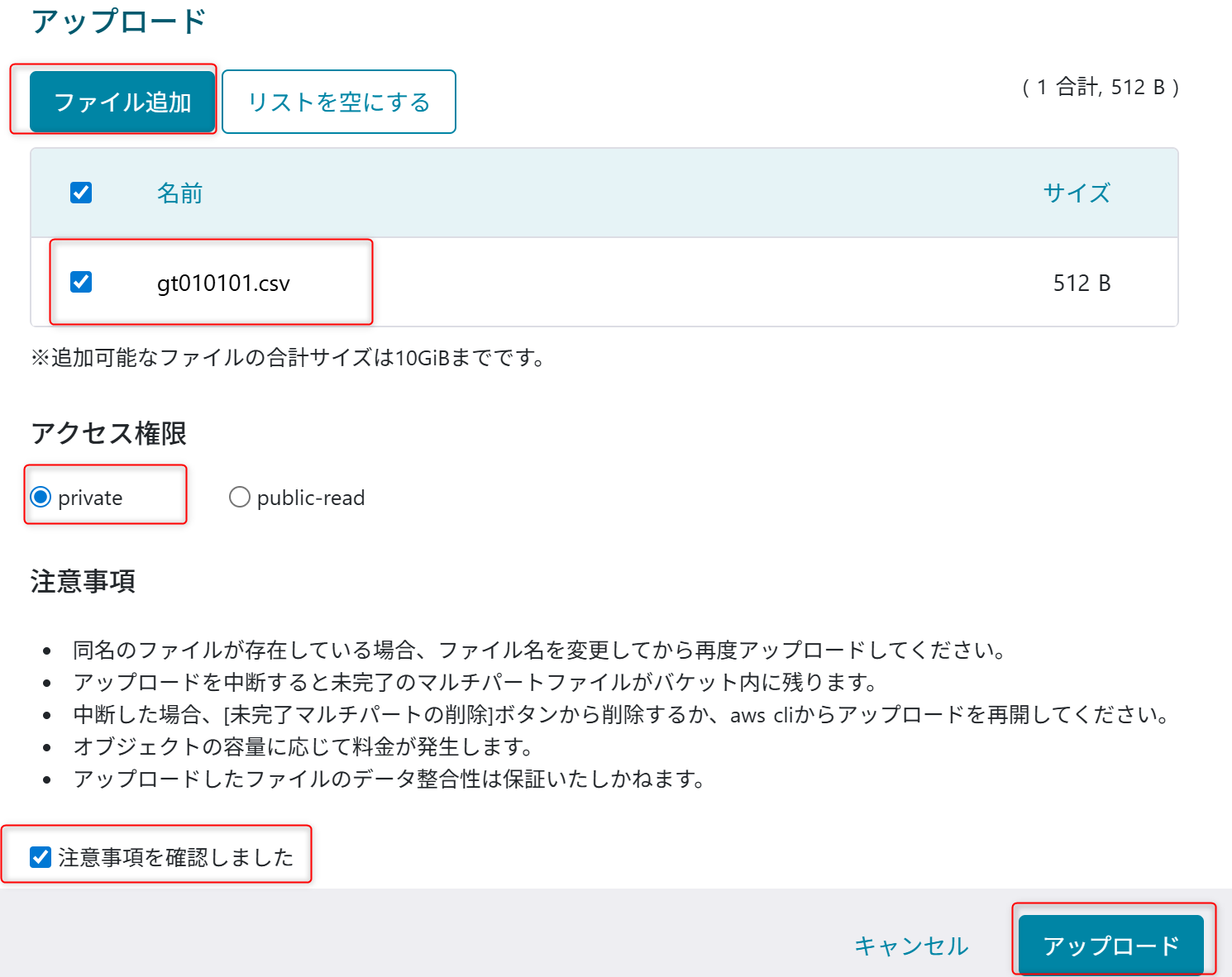
オブジェクトストレージにデータをアップロードする
参考情報:オブジェクトストレージ サービス基本情報
オブジェクトストレージにサンプルデータをアップロードします。
以下のサンプルデータをオブジェクトストレージの「usecase-a4-bucket」のバケットのメニューからアップロードする。

設定はprivateを選択してアップロードする。
Addon でのリソース作成
データレイク機能
Addon の 「データレイク機能」API を利用して Azure Data Lake Storage Gen2を作成します。
TOKEN='<サービスプリンシパルのアクセストークン>'
#POST
curl -v \
--location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/datalake' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $TOKEN" \
--data '{
"location": "japaneast",
"performance": 1,
"redundancy": 1
}'
ETL機能
Addon の 「ETL機能」API を利用して Azure Data Factory を作成します。
TOKEN='<サービスプリンシパルのアクセストークン>'
#POST
curl -v \
--location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/etl' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $TOKEN" \
--data '{
"location": "japaneast"
}'
検索機能
Addonの「検索機能」APIを利用してAzure AI Searchを作成します。
TOKEN='<サービスプリンシパルのアクセストークン>'
#POST
curl -v \
--location 'https://secure.sakura.ad.jp/cloud/api/addon/1.0/analytics/search' \
--header 'Content-Type: application/json' \
--header 'Accept: application/json' \
--header "Authorization: Bearer $TOKEN" \
--data '{
"sku": 1,
"replicaCount": 1,
"partitionCount": 1,
"location": "japaneast"
}'
RBACの設定
この操作を行うには、AzurePortalを操作するユーザーに対してユーザアクセス管理者ロールを付与します。
Azure Data Lake Storage Gen2 (データレイク用)のアクセス制御を開き、Azure Data FactoryのマネージドIDに対して「ストレージBLOBデータ共同作成者」を付与する。
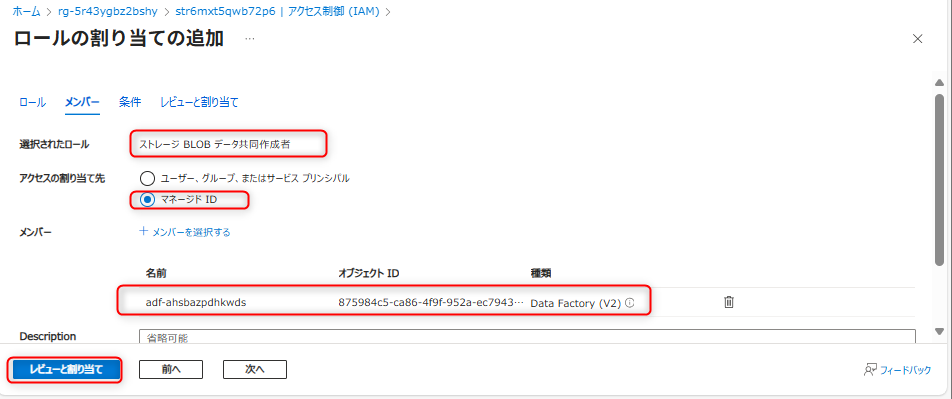
Azure Data Lake Storage Gen2 (データレイク用)のアクセス制御を開き、自身のアカウントに対して「ストレージBLOBデータ共同作成者」を付与する。
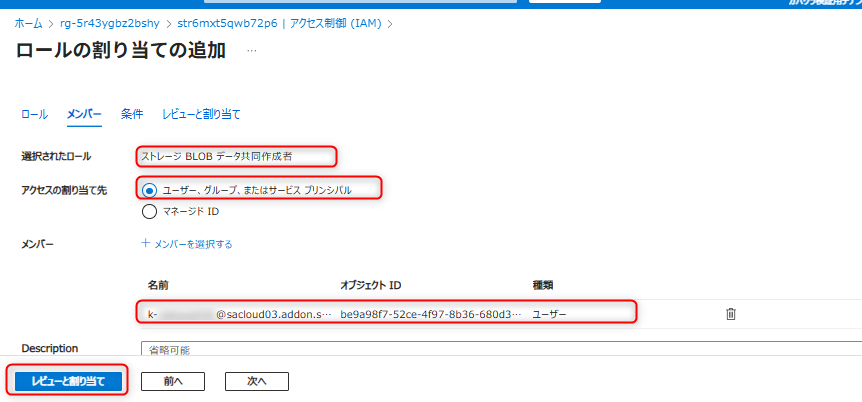
Azure AI SearchのシステムマネージドIDを作成する。Azure AI Searchを開き、「ID」のメニューへ遷移する。システム割り当てを選択し、「オン」にして保存する。
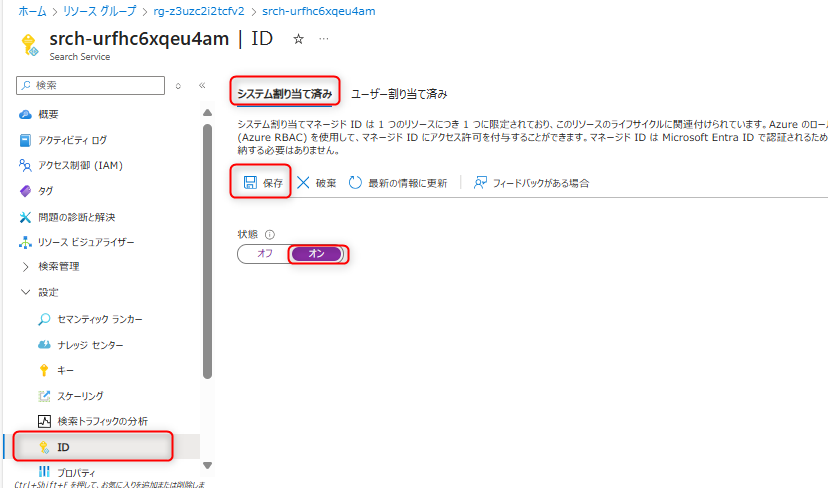
Azure Data Lake Storage Gen2 (データレイク用)のアクセス制御を開き、Azure AI Searchに対して「ストレージBLOBデータ閲覧者」を付与する。
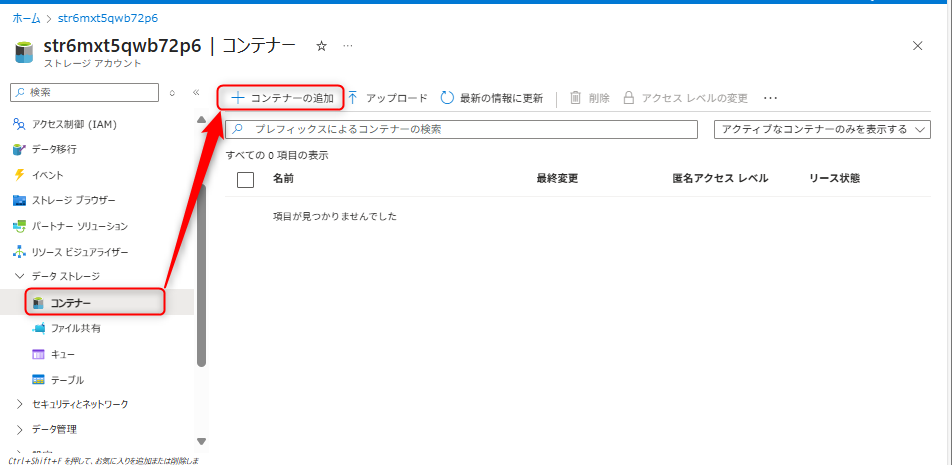
データレイクのコンテナ作成
データレイク用で利用するAzure Data Lake Storage Gen2に対してコンテナを作成する。コンテナタブから新規にコンテナを作成する(例:「test」コンテナ)。
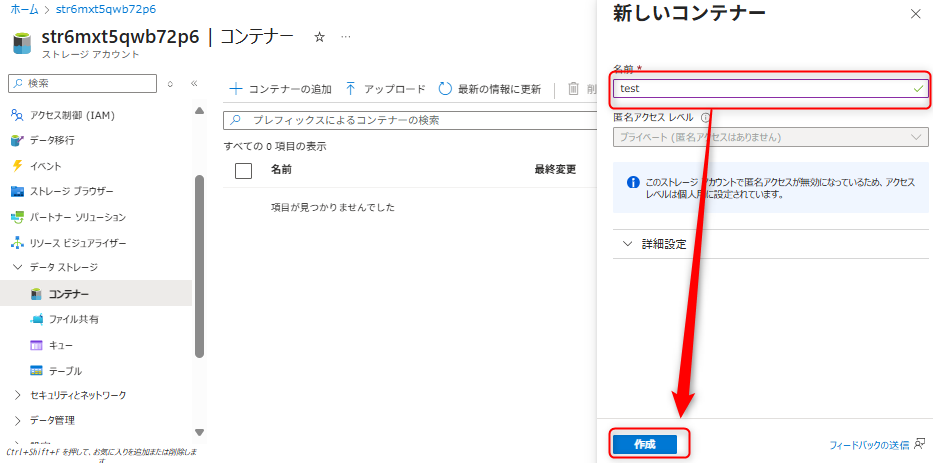
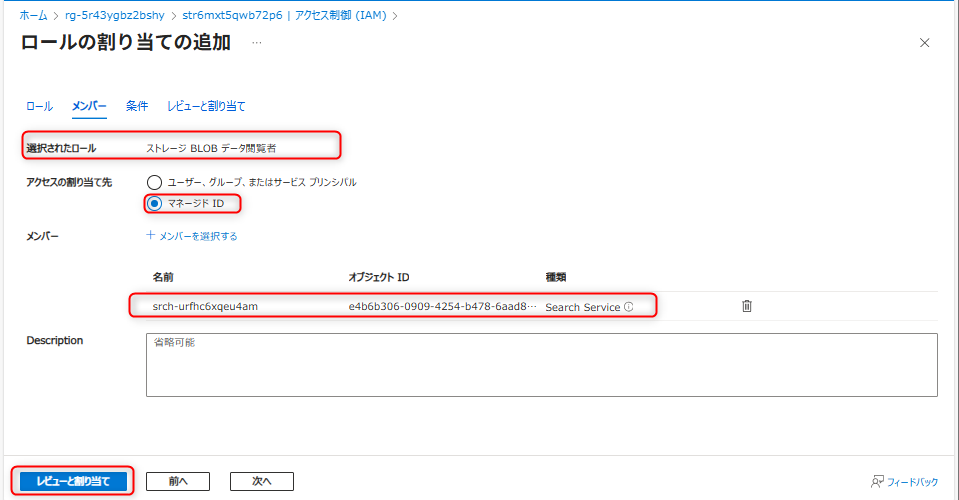
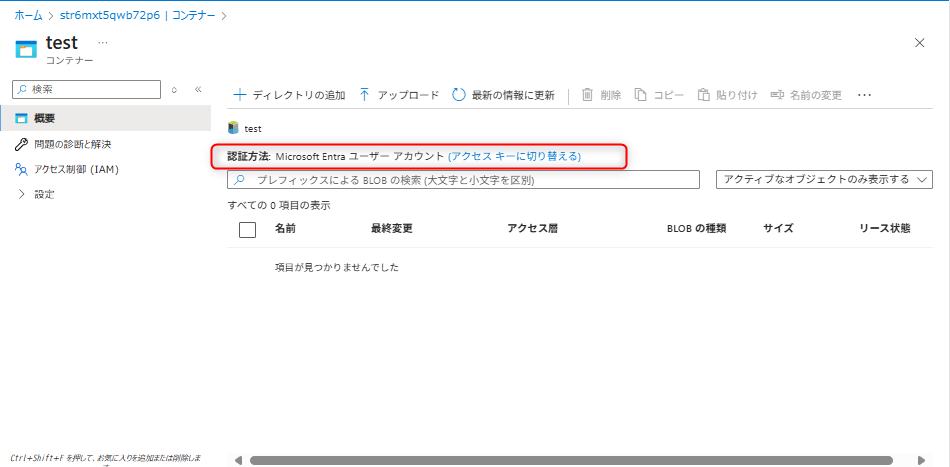
作成したコンテナを選択し、コンテナの認証方法はMicrosoft Entra ユーザーアカウントに設定する。
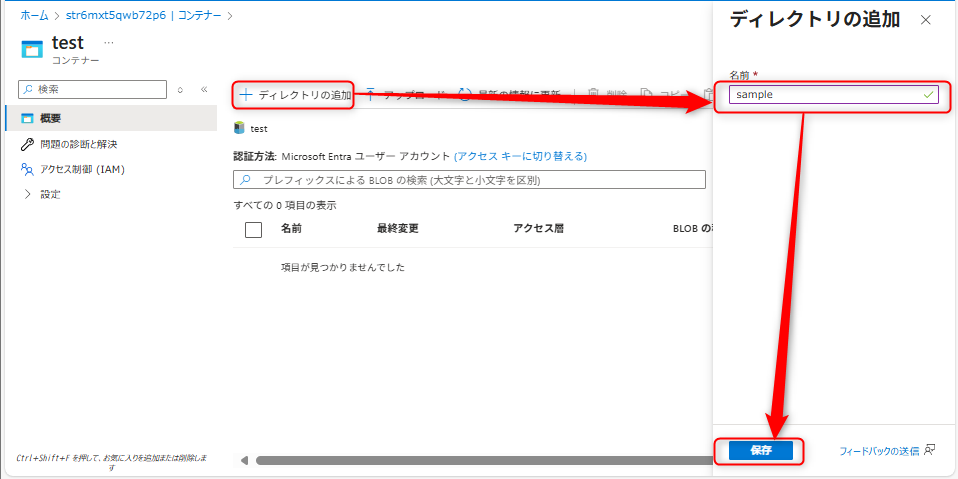
ディレクトリを追加する。
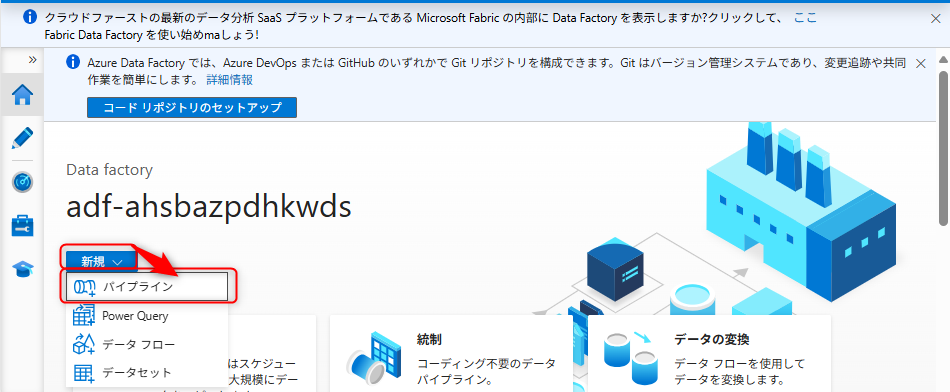
Azure Data Factoryのパイプライン構築
オブジェクトストレージからデータを取得し、Azure Data Lake Storage Gen2にデータを変換して格納するフローを構築します。
Azure Data FactoryのData Studioにアクセスし、「新規」、「パイプライン」から新しくパイプラインを作成する。
パイプラインのメニューでアクティビティ「データフロー」を選択し、キャプチャのようにドラッグする。
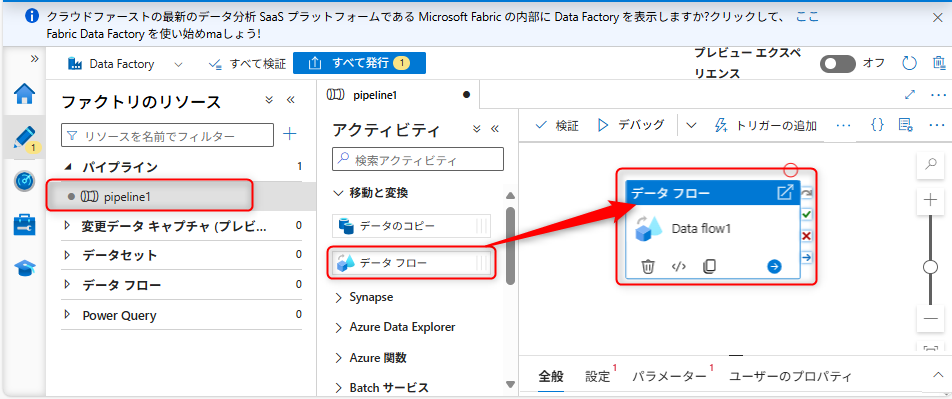
データフローの設定を行う。「設定タブ」から「新規」を選択する。
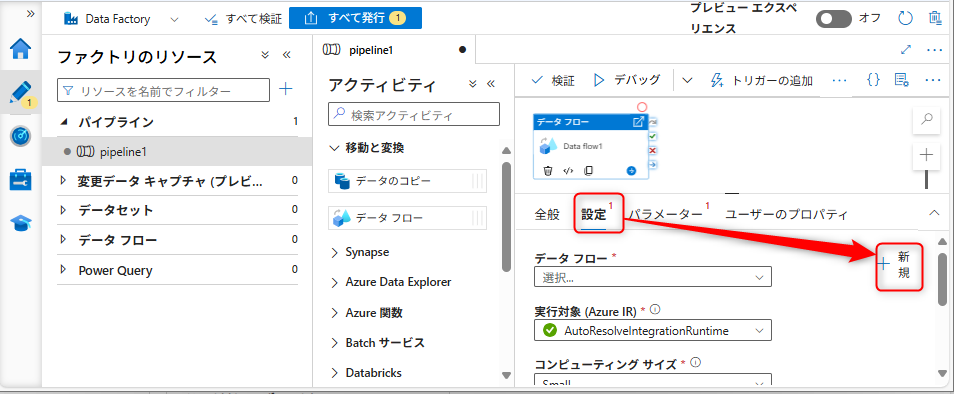
新規を選択すると「データフロー」の設定に移動する。ソースの追加と記載されてある部分の右側に表示されている矢印を選択し、「ソースの追加」を選択する。
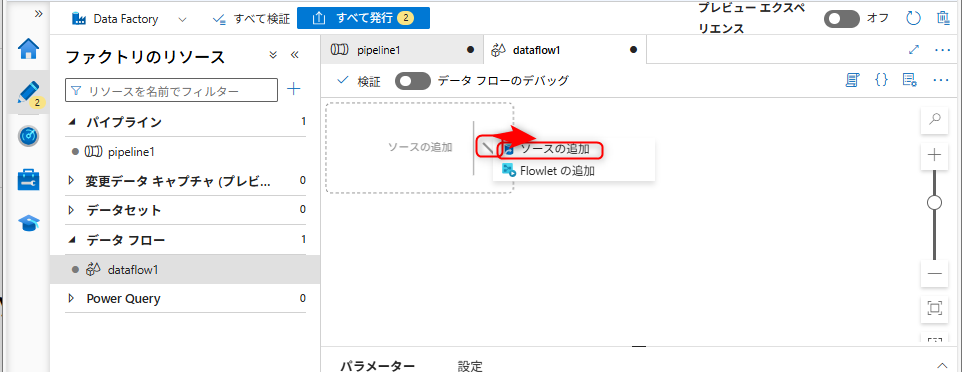
ソースの追加後、「ソースの設定」タブを開き、データセットの設定部分の「新規」を選択する。
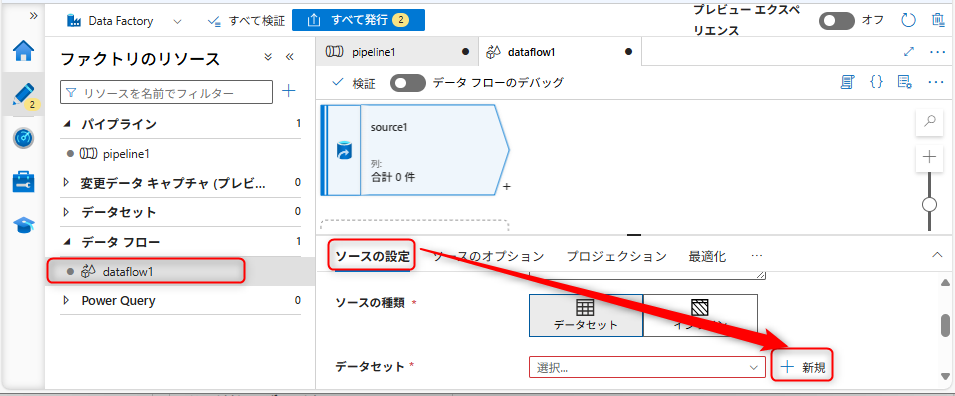
データセットは「Amazon S3」を選択して、「続行」を選択する。

データの種類は「DelimitedText」を選択して、「続行」を選択する。
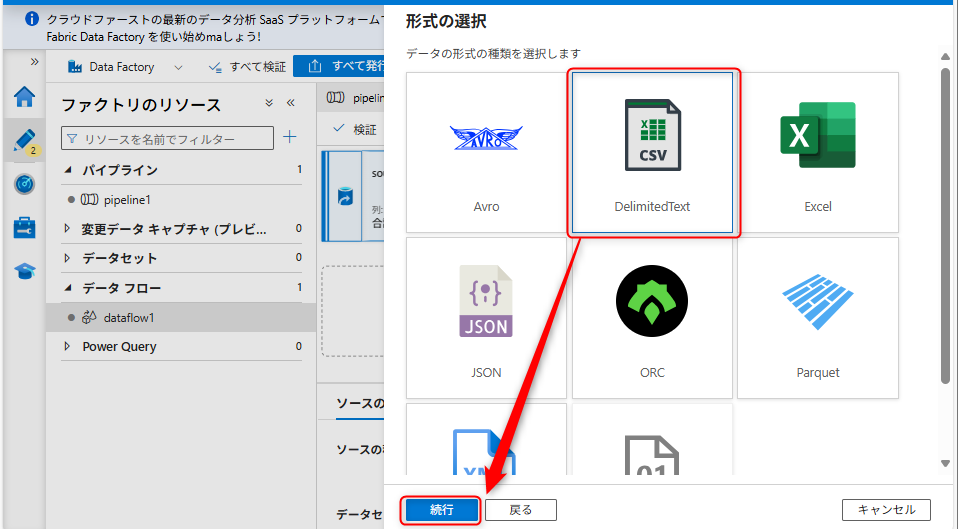
続いて、新規にソースのリンクサービスを作成する。キャプチャのように「新規」を選択する。
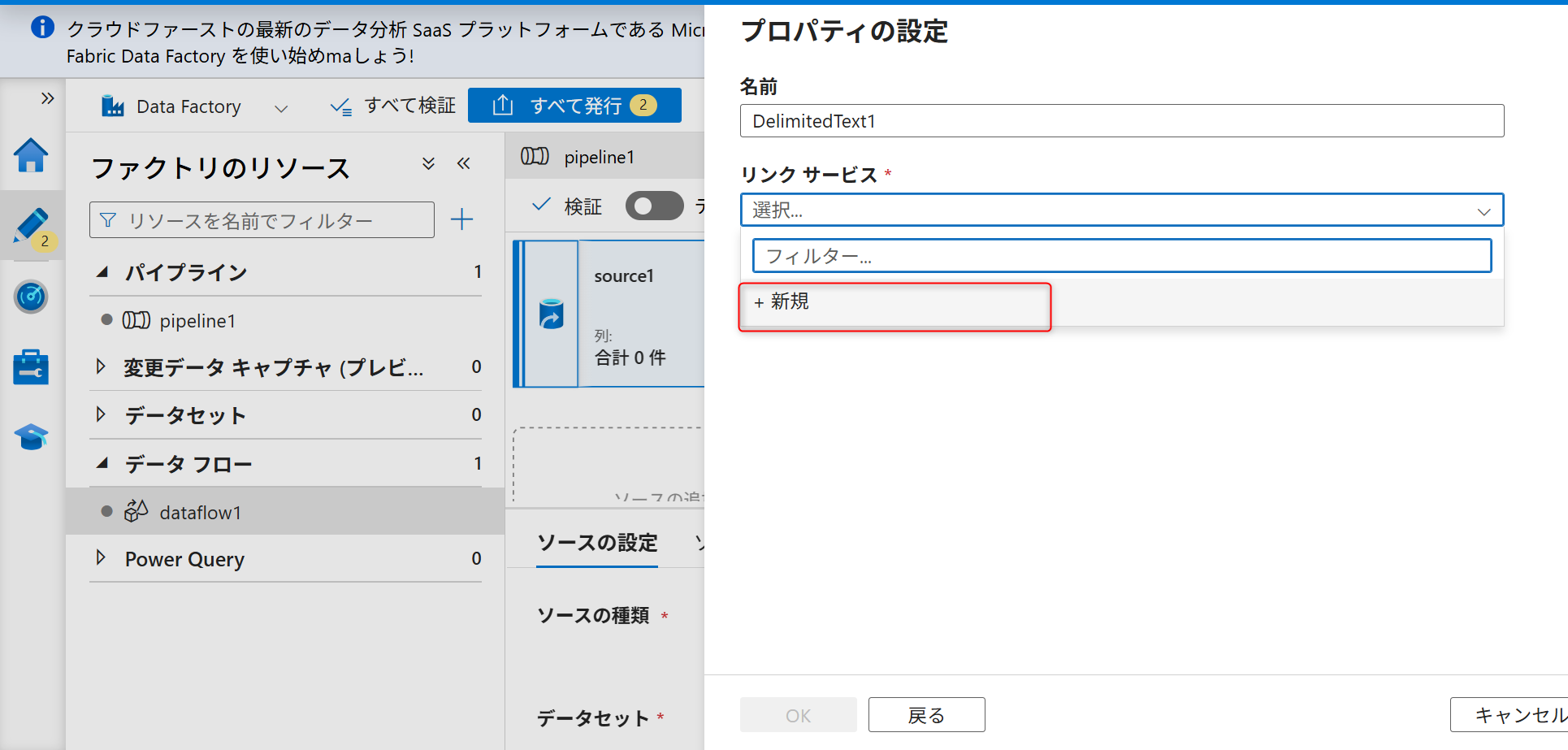
認証方法として「アクセスキー」を選択する。
オブジェクトストレージでの事前準備で確認したバケットのパーミッションのアクセスキーID、シークレットアクセスキー、S3エンドポイントを入力する。
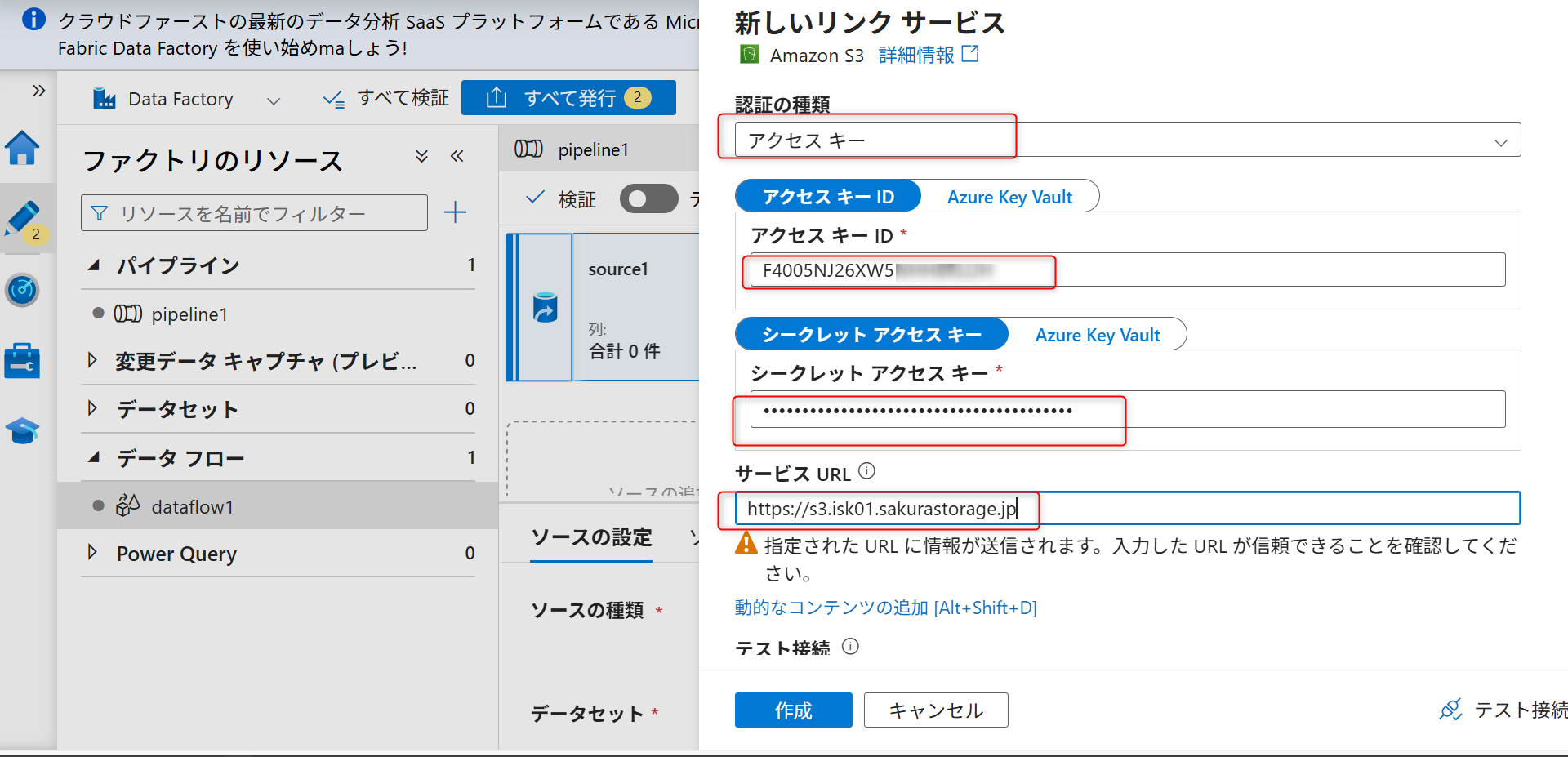
「宛先ファイルパス」を選択し、ファイルパスにバケット名を入力し、「作成」を選択する。

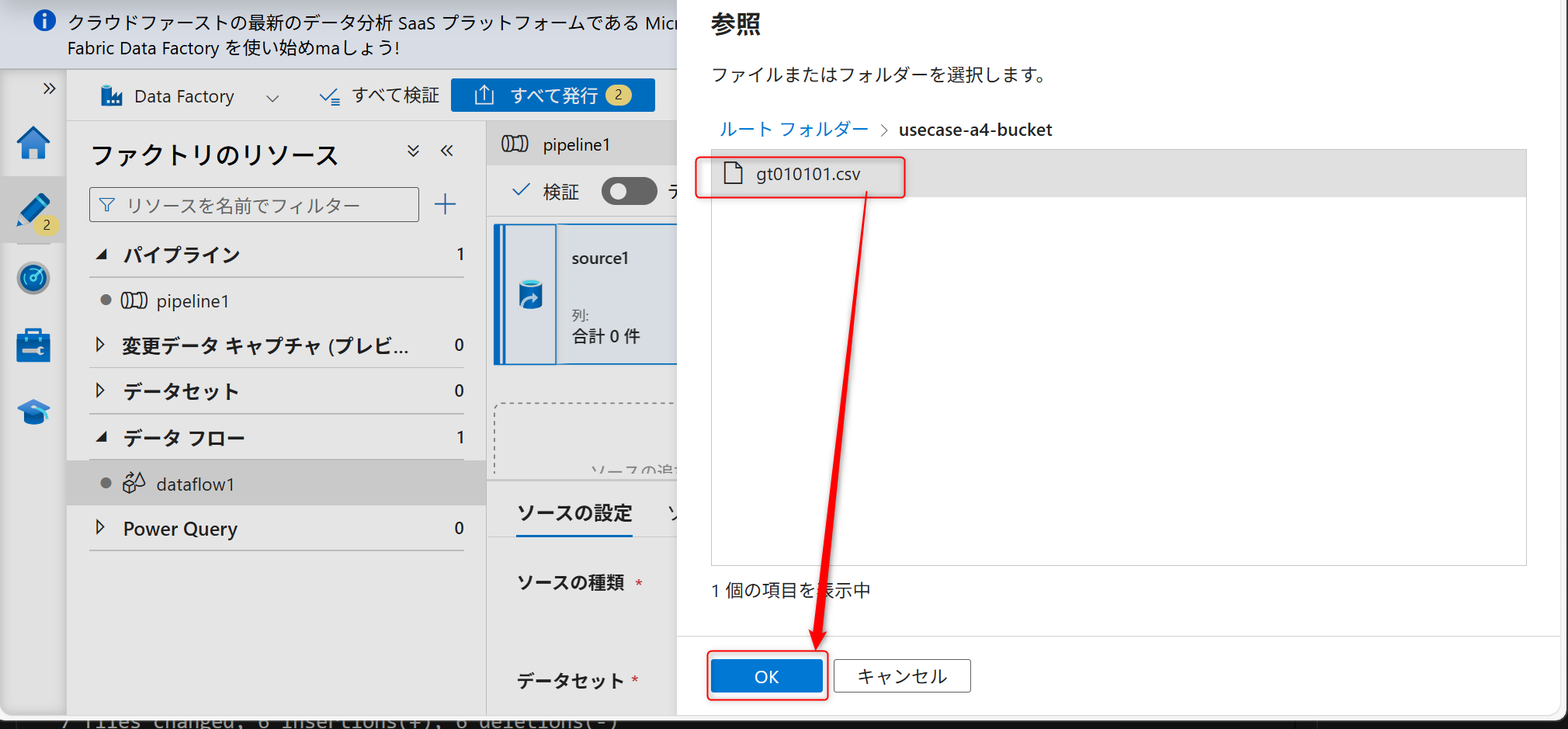
入力後、ファイルパスにオブジェクトストレージのバケット名とファイル名を入力し、矢印を選択し、「指定されたパスから」を選択する。
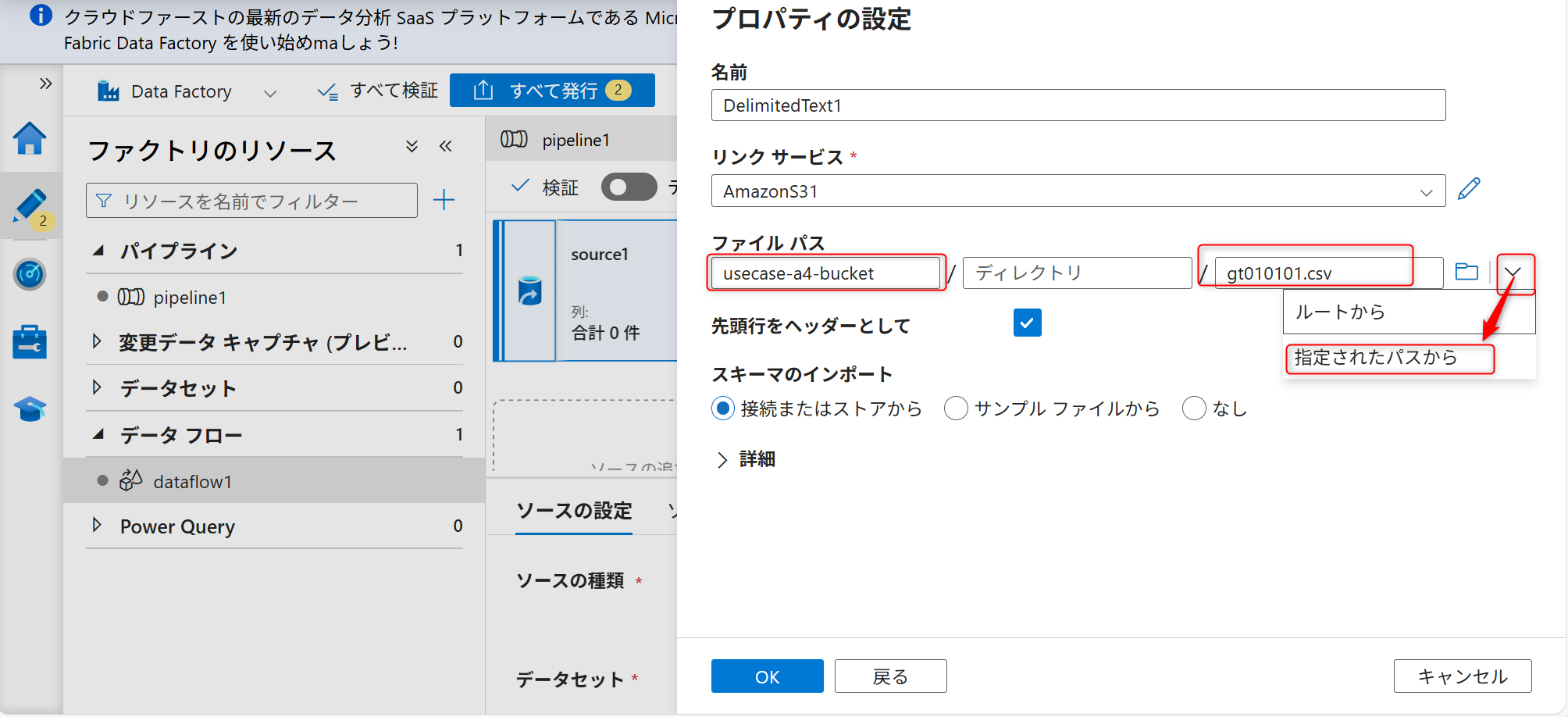
サンプルファイルを選択してOKを押す。
「先頭行をヘッダーとして」からのチェックを外してOKを押す。

データ内のインポートが不要な行をスキップするためのスキップ設定を行う。スキップ行数は「12」に設定する。

続いて、シンク(格納先)の設定を行う。+ボタンを選択し、シンクを選択する。
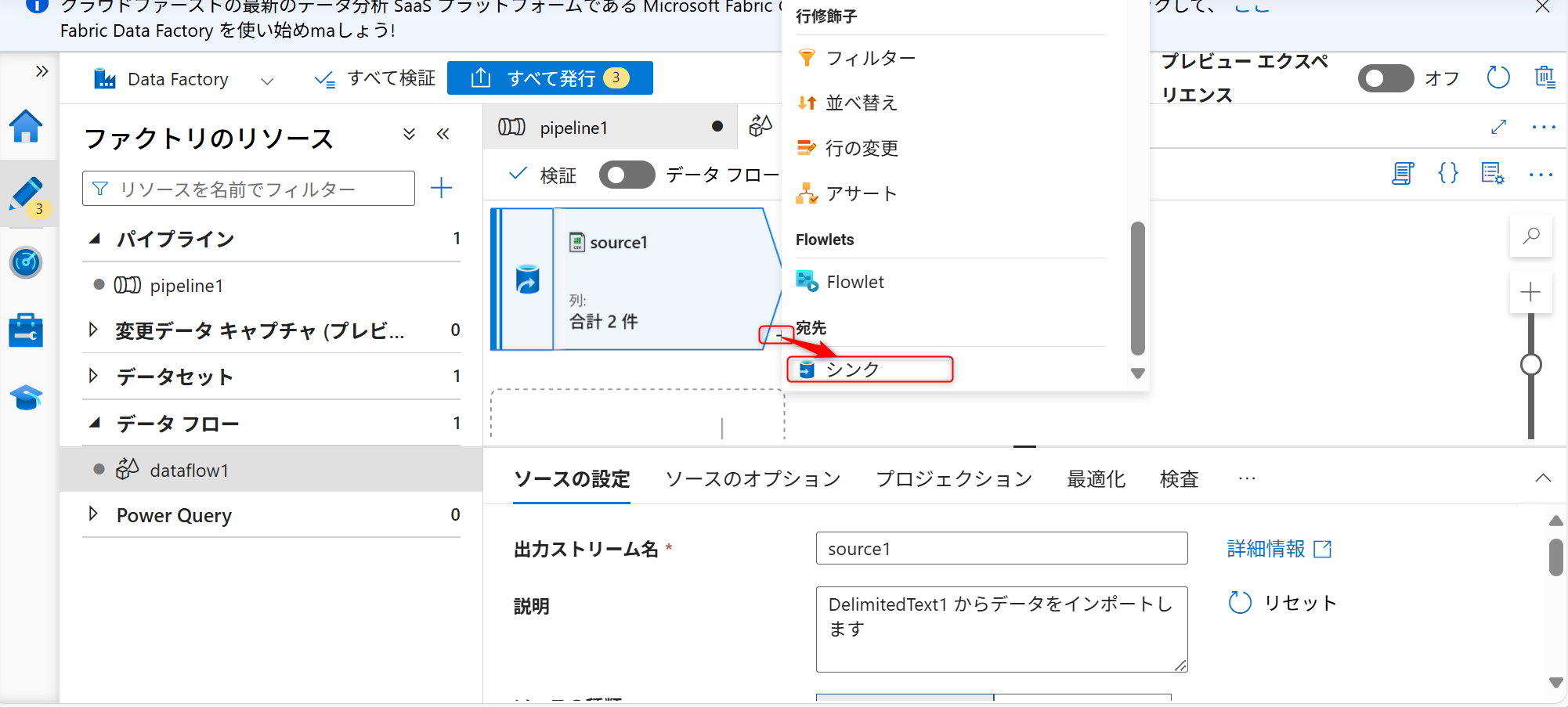
「シンク」タブからシンク用のデータセットを新規に作成する。
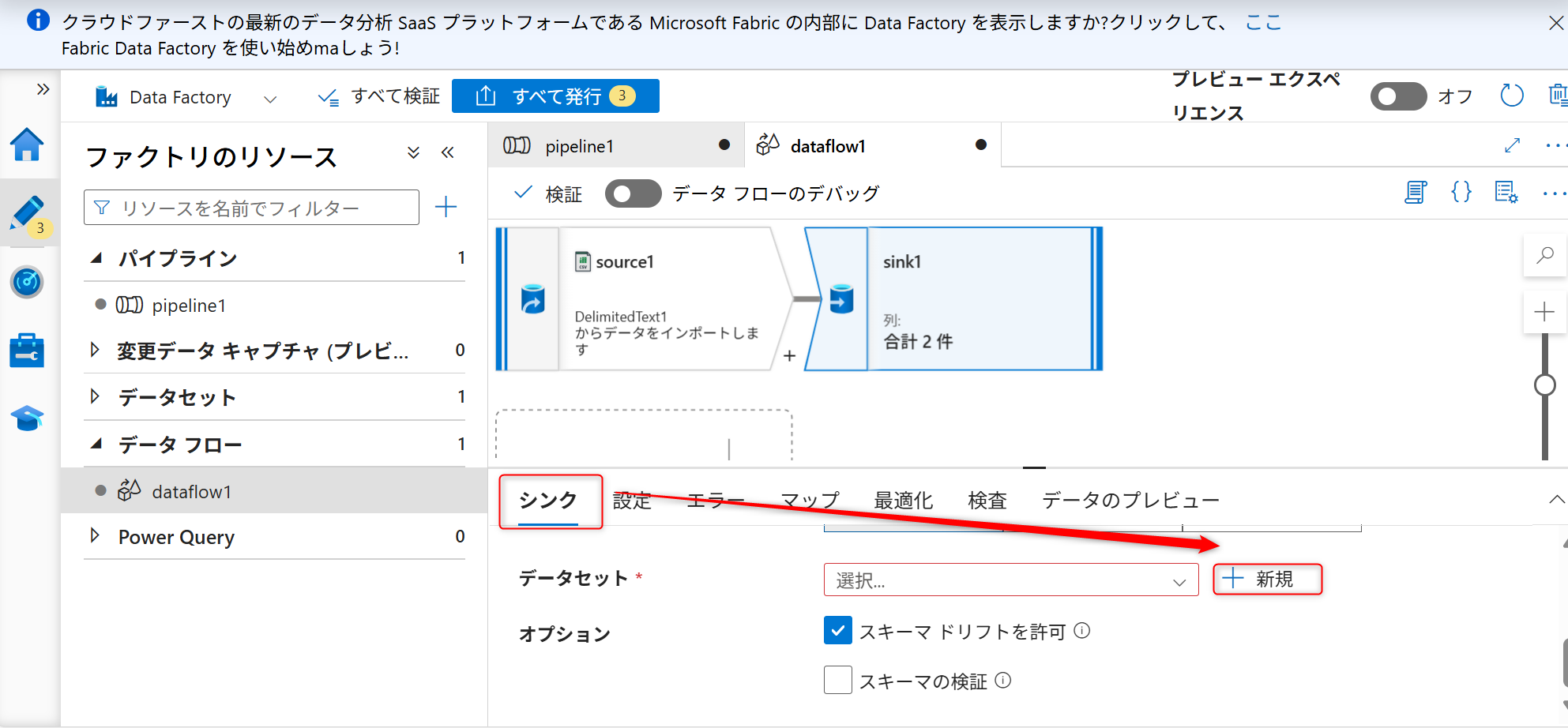
サービスはAzure Data Lake Storage Gen2を選択し、「続行」を選択する。
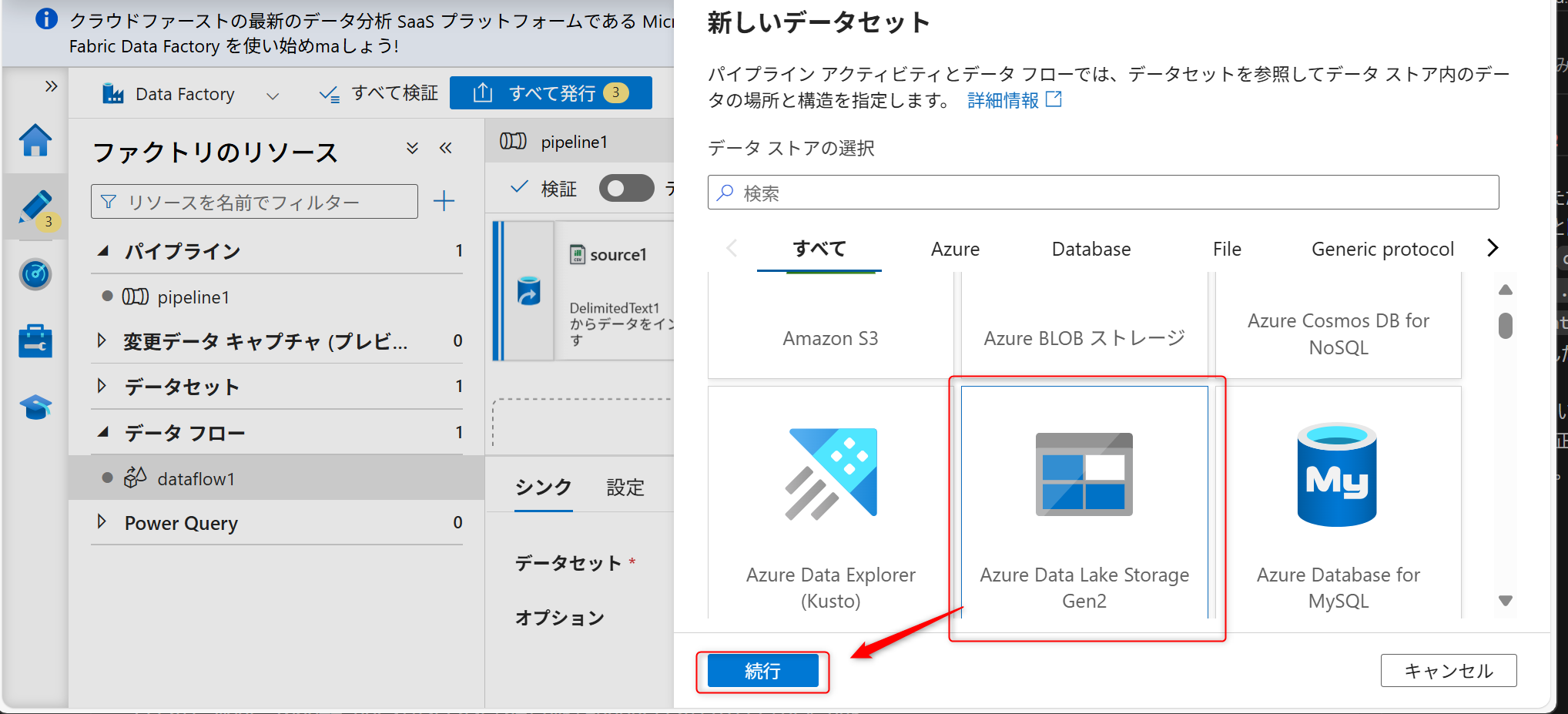
データの種類は「DelimitedText」を選択して、「続行」を選択する。
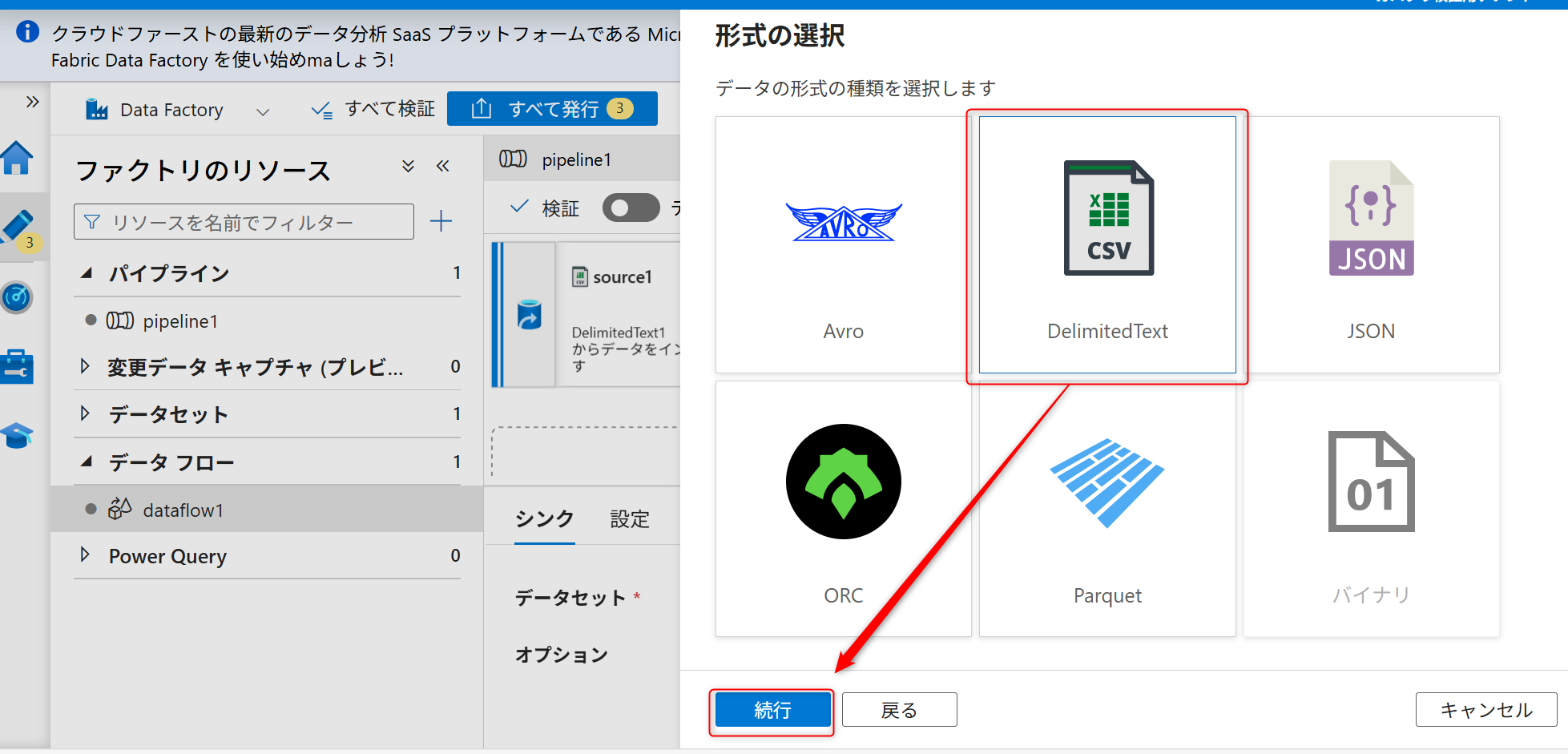
シンクも新しくリンクサービスを作成する。
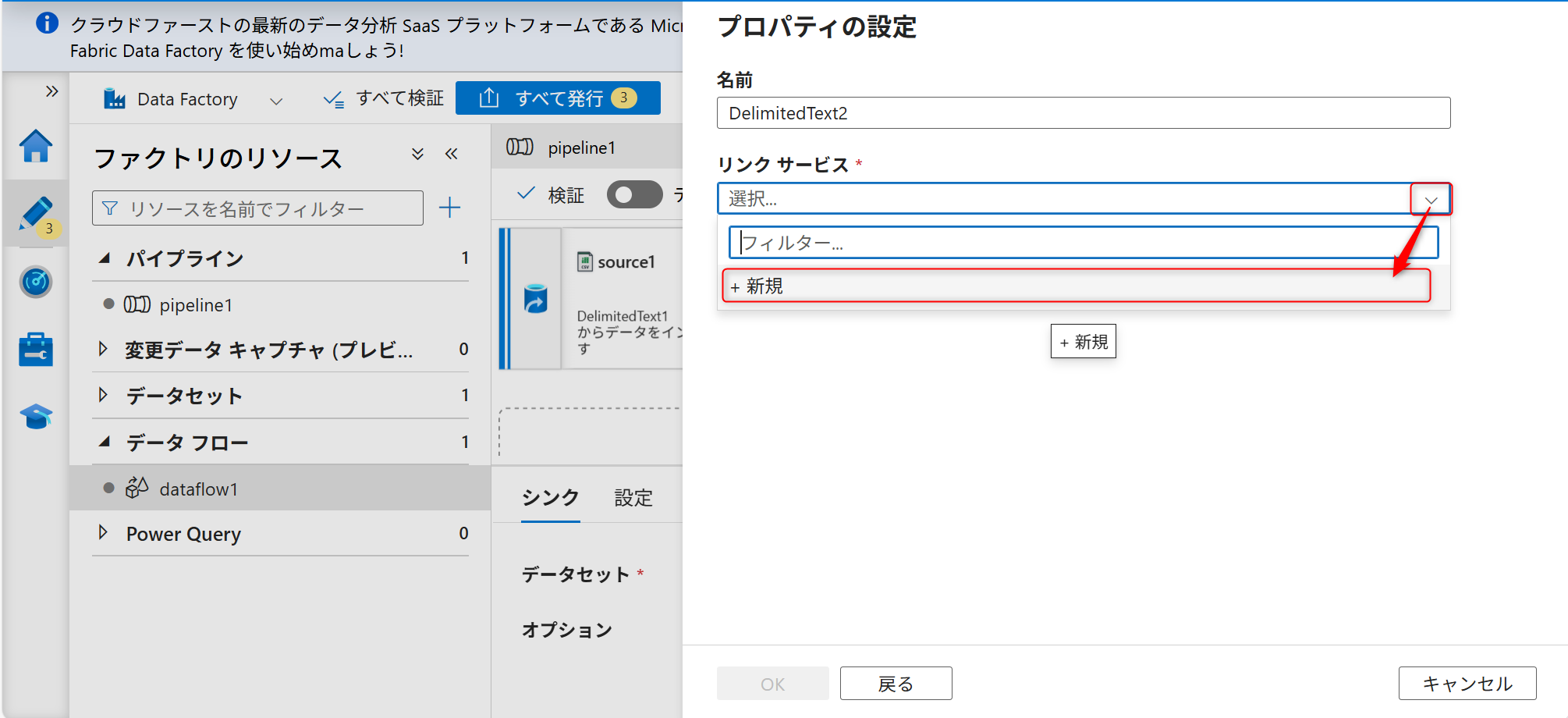
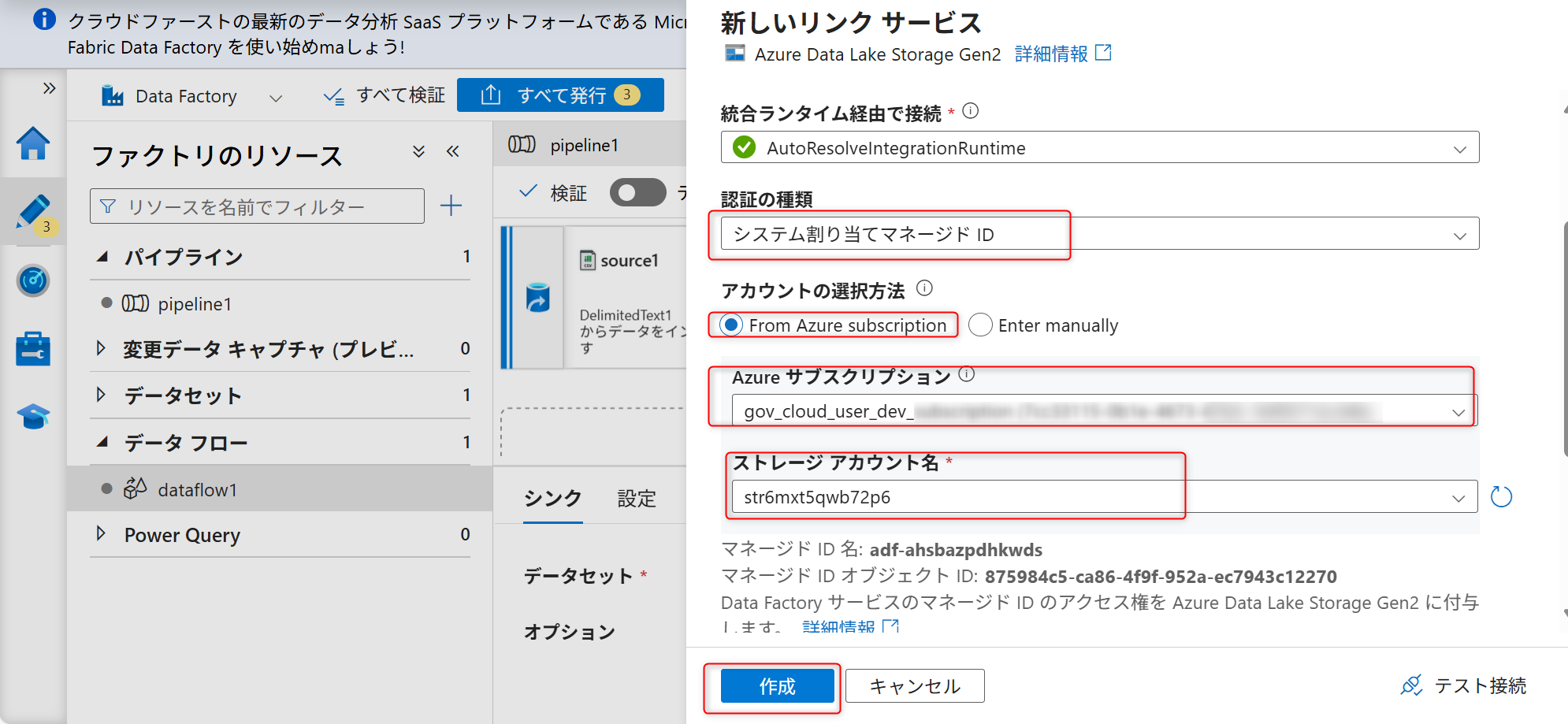
認証はシステム割り当てマネージドIDにし、データレイク機能として作成したAzure Data Lake Storage Gen2を選択する。
ファイルパスの設定でコンテナ名とフォルダ名を入力し、「先頭行をヘッダーとして」からチェックを外しOKを押す。

シンクへ格納時のファイル名を設定する。「設定」タブを開き、ファイルのオプションで「1つのファイルへの出力」を選択する。

ファイルオプション変更時に以下のような警告が表示されるため、「単一パーティションの」を選択する。
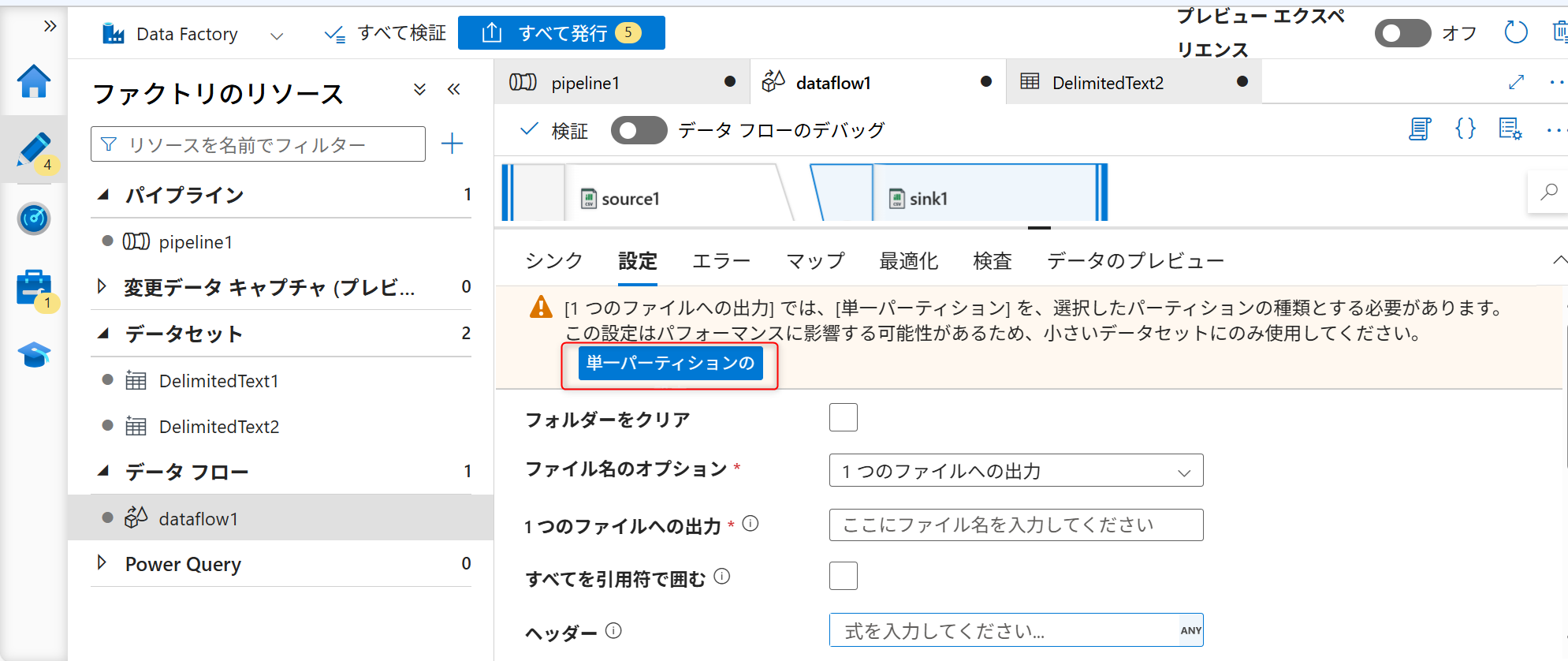
ファイル名を入力する(例ではtest.csvと入力)。
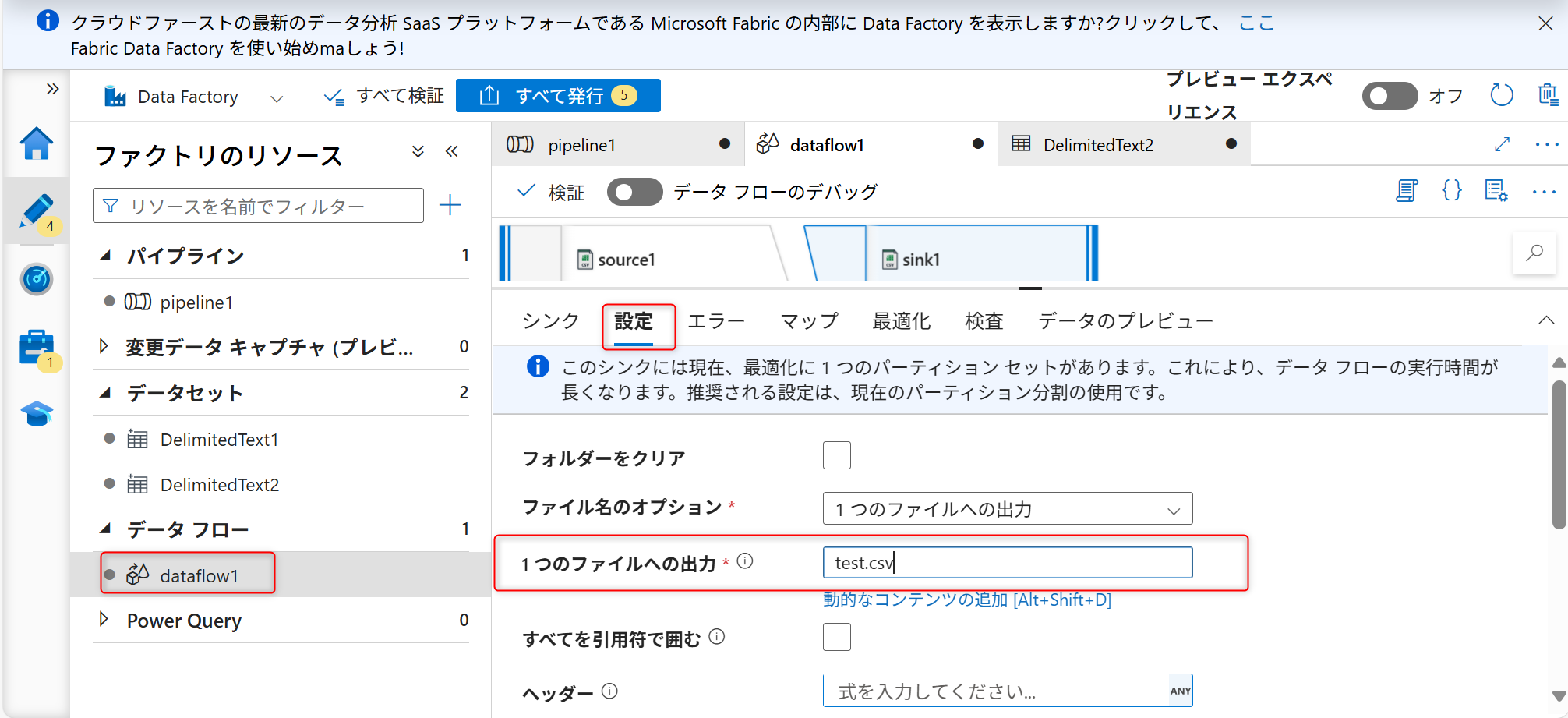
シンクの設定まで終えたら「発行」を選択し、パイプラインの構築内容を保存する。
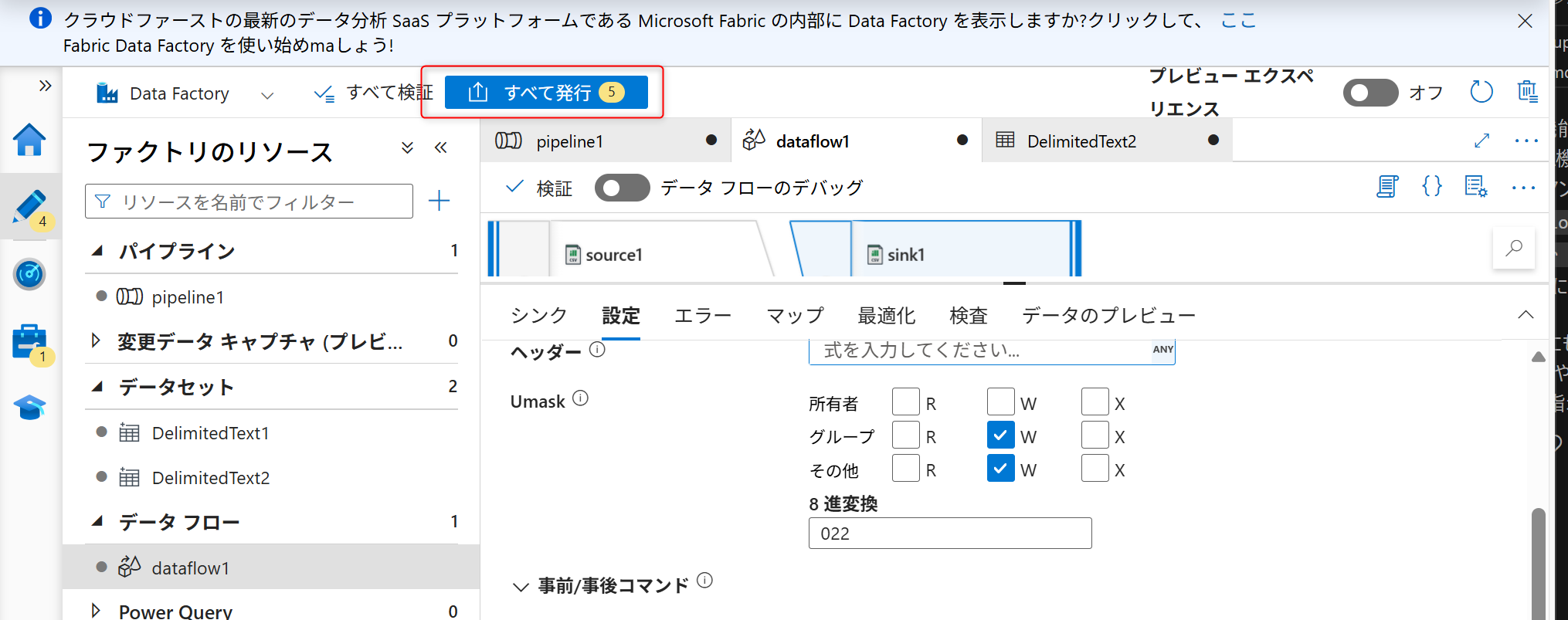
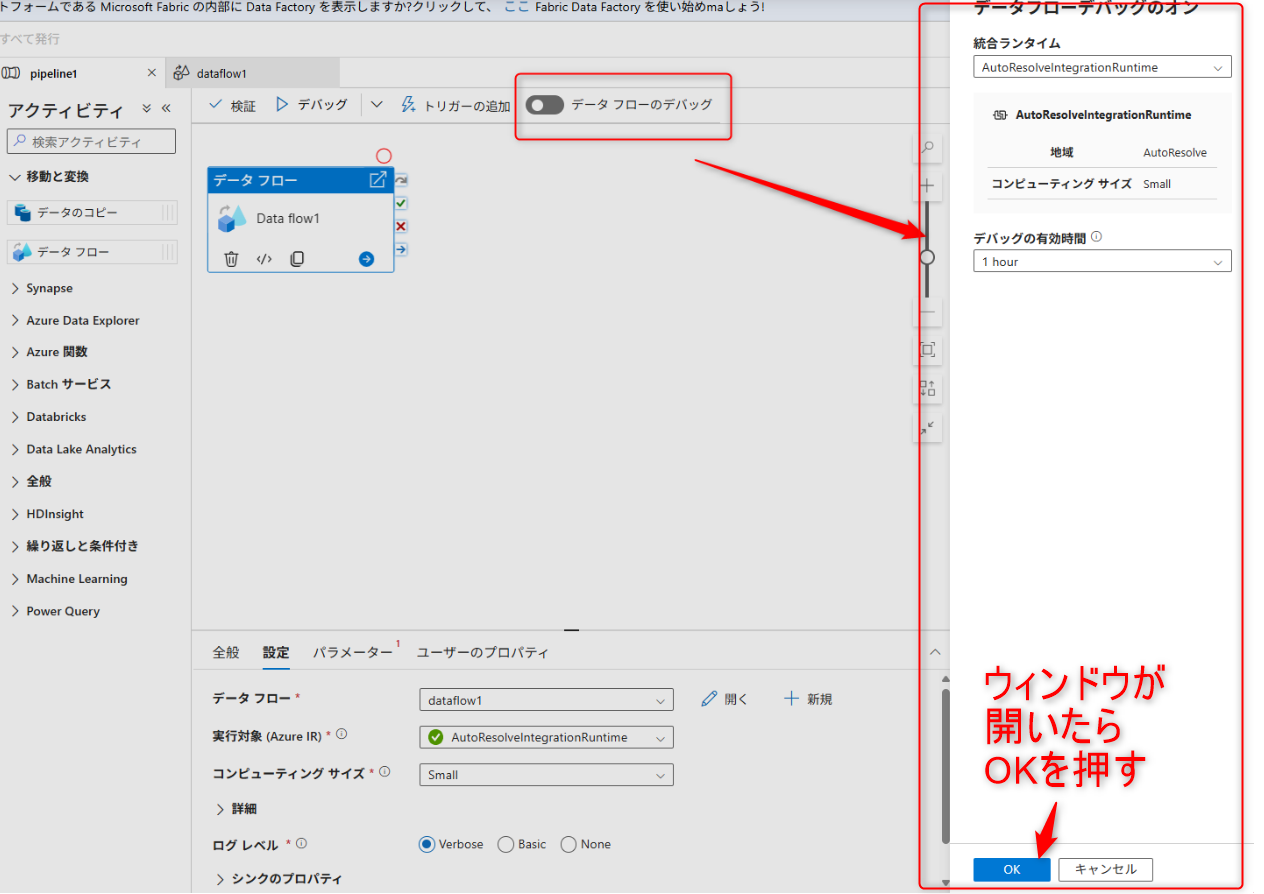
データフローの設定画面から「データフローのデバッグ」のトグルを選択してデバッグを有効化する。
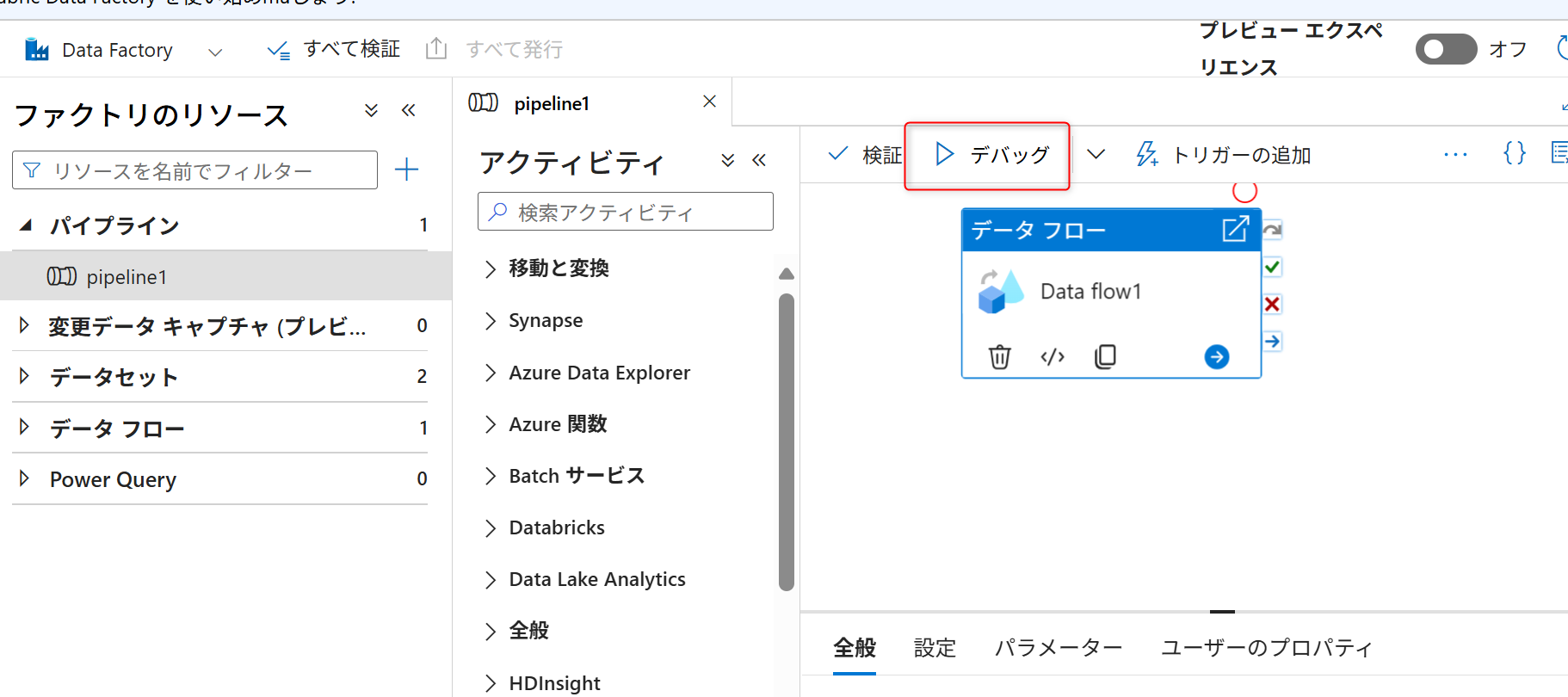
デバッグフローが有効になったら、パイプラインの設定画面から「デバッグ」を実行する。
Azure AI Searchを利用してデータの全文検索
セットアップ手順
Azure Data Lake Storage Gen 2に格納したデータをAzure AI Searchに取り込み全文検索を行います。
Azure AI Searchの概要の画面に遷移し、「データのインポート」を選択する。
接続設定を行う。
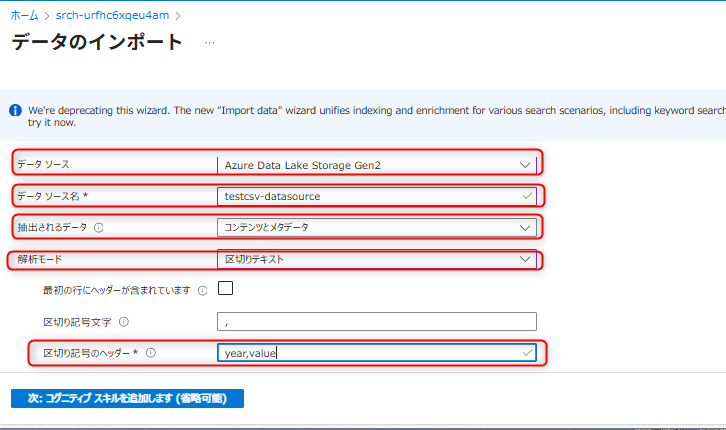
データソースは「Azure Data Lake Storage Gen2」を設定する。
データソース名は任意の値を入力する(例ではtestcsv-datasourceと入力する)。
抽出するデータは「コンテンツとメタデータ」を選択する。
解析モードは「区切りテキスト」を選択する。
最初の行にヘッダーが含まれますからチェックを外す。
区切り記号のヘッダーは「
year,value」とする。
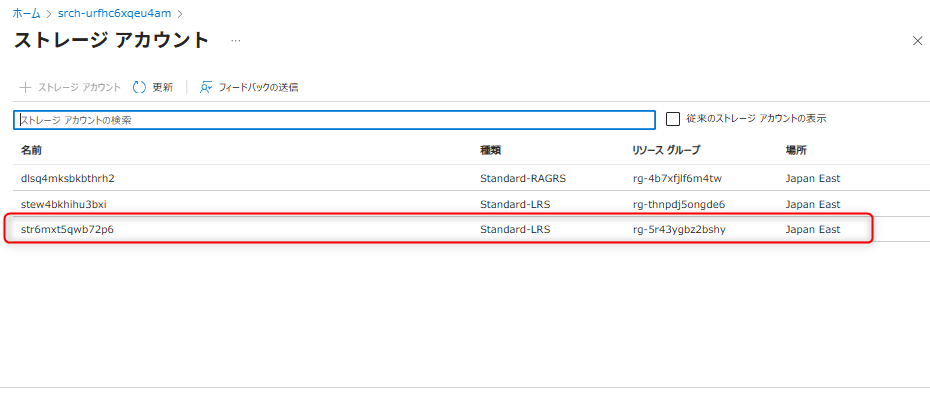
接続文字列は「既定の接続を選択します」を押す。

対象のストレージアカウントとコンテナを選択する。
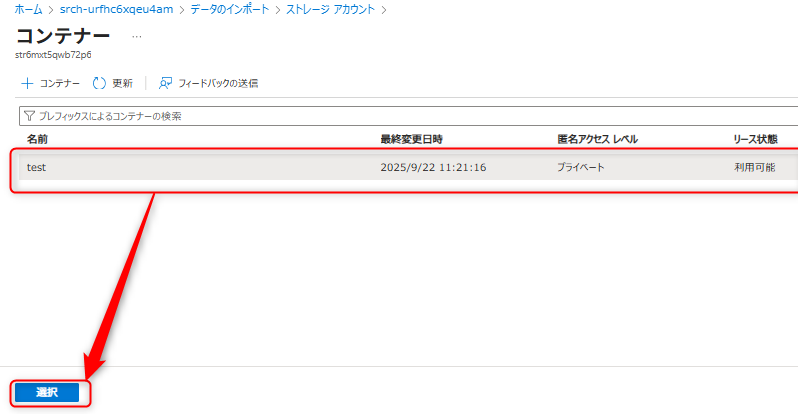
「マネージドIDの認証」はシステム割り当てを選択し、次に進む。
コグニティブスキルの追加は不要なため、対象インデックスのカスタマイズの設定に進む。
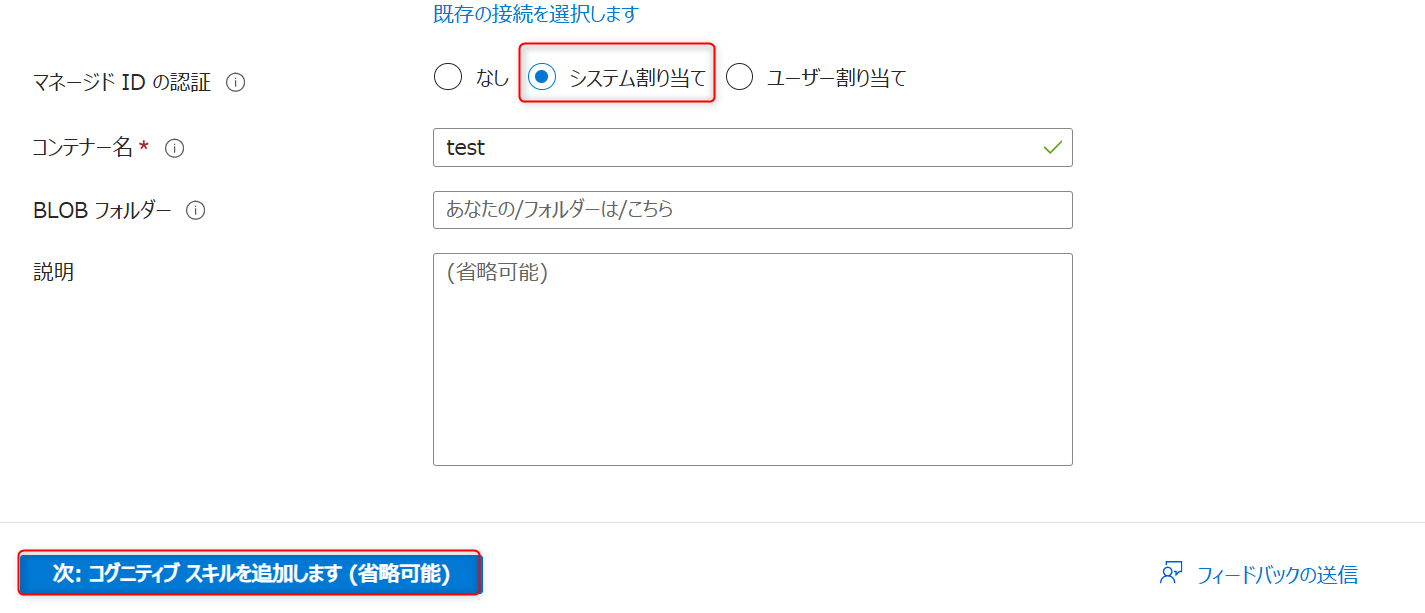
「対象のインデックスをカスタマイズ」では以下のように設定する。valueとyearの型はそれぞれ「
Edm.String」とし、設定後インデクサーを作成する。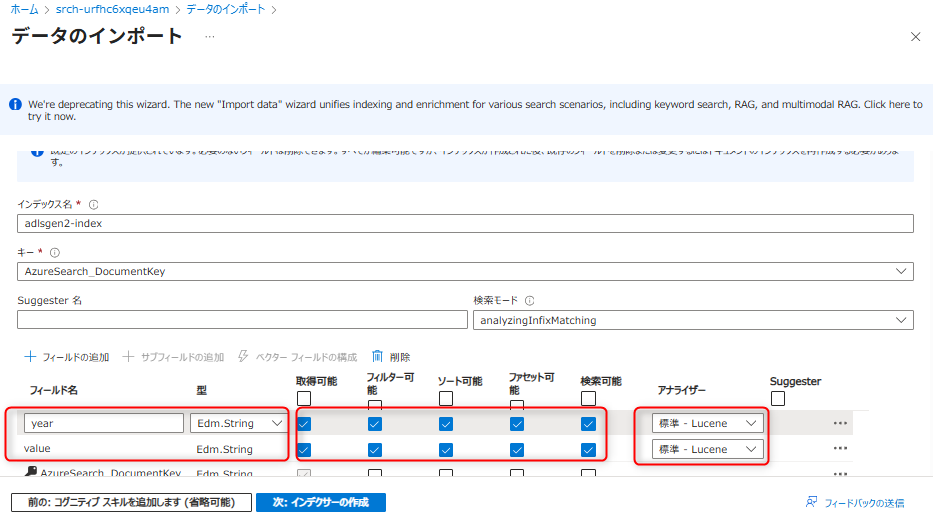

インデクサー作成後、検索を実行する。検索エクスプローラーを開き、例えば
2000というキーワードを入力すると、以下のように検索が実行される。
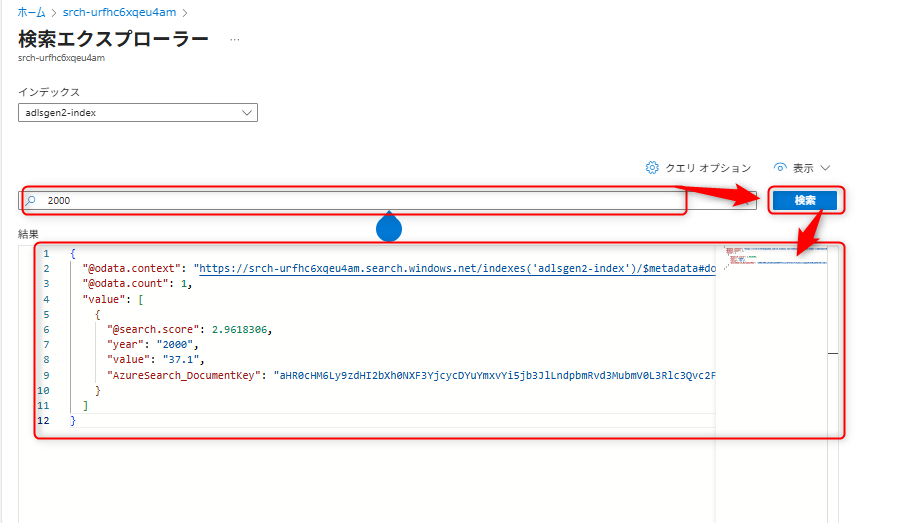
関連情報: