CData Sync DBアプライアンスのデータ抽出と加工(基本設定編)
[更新: 2025年10月8日]
本記事は、弊社で検証したデータの一部を公開しています。ご参考としてご活用ください。
1. はじめに
本記事は、CData Syncを用いたデータ抽出および加工の基本設定手順を解説します。
実際の検証データをもとに、設定例や操作手順をまとめています。
注釈
個別の要件定義や設計、開発・設定のサポートは、CData Syncのサービスには含まれませんのでご注意ください。
2. 検証環境の概要
2.1 検証条件
CData Syncバージョン:
25.1.9285.0仮想サーバーの作成やWindows Server OSの基本設定については、本記事では割愛します。
GUIは日本語表示で解説しています。
注釈
Windows Server OSのグループポリシーやセキュリティ設定は、OS管理者が別途設定する必要があります。
2.2 データベースの構成
本検証では、さくらのクラウド上に4台のデータベースアプライアンスを作成し、ローカル環境に配置しました。
構成図
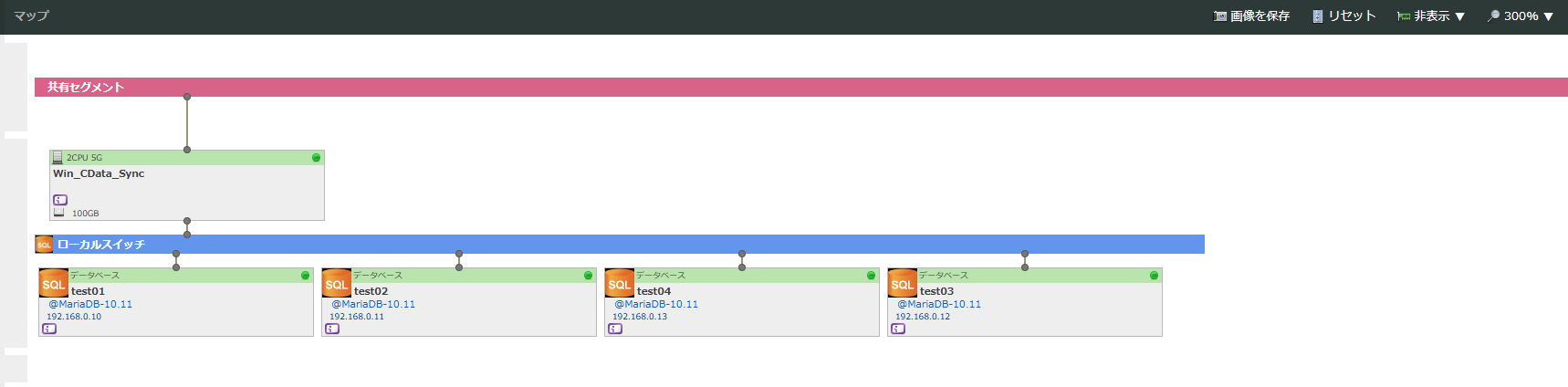
対象 |
説明 |
|---|---|
Win_CData_Sync |
CData Syncをインストールし、各DBを操作する踏み台サーバー |
test01 |
部署AのデータベースA' |
test02 |
部署BのデータベースB' |
test03 |
部署CのデータベースC' |
test04 |
部署DのデータベースD(分析・統合用)' |
注釈
本検証は、1社で複数DBを分散利用するケースを想定しています。
2.3 DBアプライアンスの詳細
データベースアプライアンスの構成は、下記の内容で作成・利用しました。
対象 |
説明 |
|---|---|
対象 |
test01 |
プラン |
1Core-2GB 10GB |
データベースエンジン |
MariaDB(バージョン10.11) |
対象 |
IPアドレス |
ゲートウェイアドレス |
|---|---|---|
test01 |
192.168.0.10/24 |
192.168.0.1 |
test02 |
192.168.0.11/24 |
192.168.0.1 |
test03 |
192.168.0.12/24 |
192.168.0.1 |
test04 |
192.168.0.13/24 |
192.168.0.1 |
2.4 テーブル作成内容
各データベースには以下のテーブルを作成しました。
SELECT * FROM `contract01`;
contract_id contract_date name product_id department_id team_id
1 2025-08-01 株式会社うさぎ 1 1 1
2 2025-08-01 株式会社うさぎ 2 1 1
3 2025-08-05 株式会社ライオン 1 1 2
SELECT * FROM `contract02`;
contract_id contract_date name product_id department_id team_id
1 2025-08-01 株式会社まぐろ 1 2 1
2 2025-08-02 株式会社さば 5 2 2
3 2025-08-10 株式会社あじ 1 2 3
SELECT * FROM `product_master`
product_id product_name amount eol updateat
1 水 100 0 2025-08-02 13:32:22
2 肉 500 0 2025-08-02 13:32:47
3 卵 80 0 2025-08-02 13:33:50
4 大根 150 1 2025-08-02 13:36:22
5 ちくわ 100 0 2025-08-02 13:38:24
30 からし 100 0 2025-08-02 13:38:37
SELECT * FROM `contract01`;
contract_id contract_date name product_id department_id team_id
注釈
テーブルのカラムやサンプルデータは省略しています。
3. CData Syncの概要と前提
CData Syncは、DBやSaaSサービス、ファイルのデータを抽出・加工・転送できるETL/ELTツールです。
本記事では、CData Syncがインストール済みのWindows Server OSサーバーを用い、サブスクリプションキーの設定が完了している前提で解説します。
4. CData Syncによるデータレプリケーション手順
4.1 単純なレプリケーション
4.1.1 シナリオ概要
部署Dが、test01データベースのcontract01テーブルをtest04データベースへ定期的にレプリケーションする必要がある、という想定で手順を説明します。
上記のシナリオを想定し、設定手順と結果を掲載します。
4.1.2 接続の追加
CData SyncのGUIで以下の手順に従い、 データソース(test01) 同期先(test04) の接続を設定します。
・接続 >>> 接続を追加を表示
・コネクタ選択(MySQL)
・接続名、サーバーアドレス、ポート、認証方式、ユーザー名、パスワード、データベース名、SSL利用有無、ログレベルを入力
新しい接続画面(初期画面)
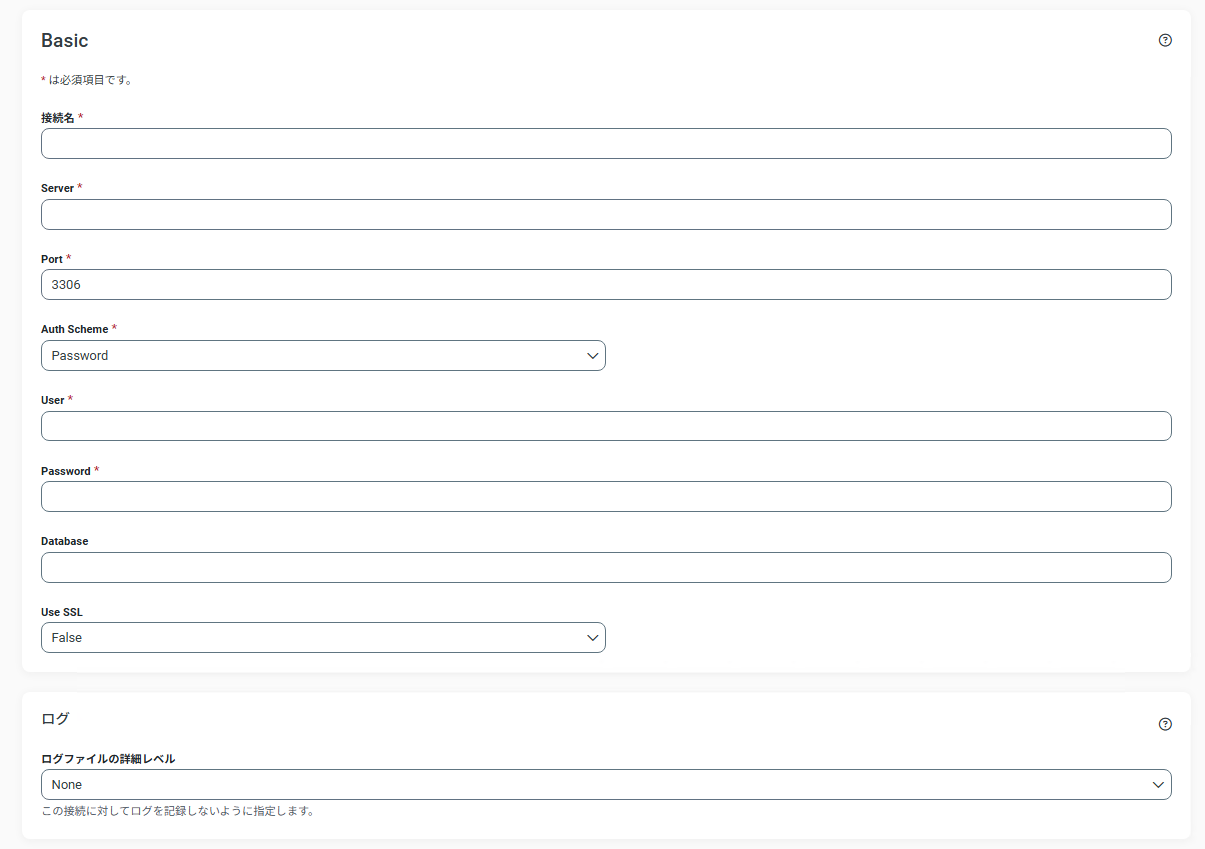
対象項目 |
参考設定 |
説明 |
|---|---|---|
接続名 |
test01 |
CData Sync 接続画面上の名前を設定(任意)します。 |
Server |
192.168.0.10 |
サーバーのアドレス、ホスト名を設定します。 |
Port |
データベースのポート番号 |
データベースアプライアンス test01のポートを設定します。 |
Auth Scheme |
認証方式を指定 |
データベースアプライアンス test01の認証方式を指定します。 |
User |
データベースアプライアンス作成時に設定したユーザ名 |
データベースアプライアンス test01で作成・指定したユーザ名を指定します。 |
Password |
データベースアプライアンス作成時に設定したパスワード |
データベースアプライアンス test01で作成・指定したパスワードを指定します。 |
Database |
test01 |
データベースアプライアンス test01に作成済みのデータベースを指定します。 |
Use SSL |
False |
SSLの利用を指定します(TIPSの検証環境ではFalse)。 |
ログ |
info |
接続に関するログ情報のレベルを指定します(TIPSの検証環境ではinfo)。 |
注釈
設定は、作成後に変更できます。
重要
test02以降も同様に設定します。操作が重複するため掲載は省略いたします。
注意
接続先の登録可能数はライセンスに依存します(Standard:最大5、Enterprise:制限なし)。
4.1.3 ジョブの追加
抽出や加工の指定、および同期先への転送設定は、ジョブによって管理・制御します。
・ジョブ >>> ジョブを追加を表示
・ジョブ名、データソース(test01)、同期先(test04)を指定
ジョブを追加画面
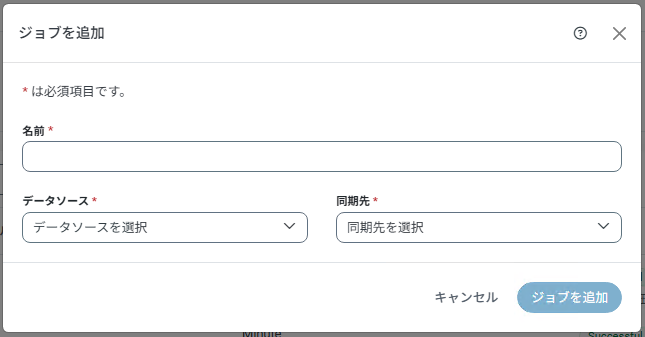
対象項目 |
参考設定 |
説明 |
|---|---|---|
名前 |
任意ジョブ名 |
CData Sync ジョブ画面上の名前を設定(任意)します。 |
データソース |
test01 |
データソースを予定する接続:test01を指定します。 |
同期先 |
test04 |
同期先を予定する接続:test04を指定します。 |
注釈
本TIPSは、標準を指定・作成します。
4.1.4 カラムの設定
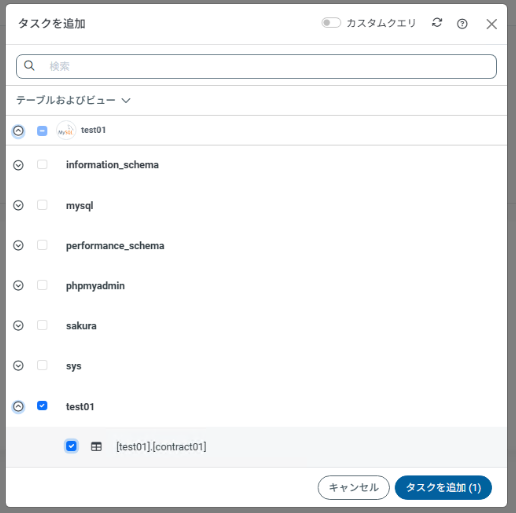
ジョブ作成後、タスク画面で抽出対象テーブル(contract01)を指定します。
単純なレプリケーションの想定では、カラムマッピングはすべてデフォルト(全カラム)とし、その他の項目もデフォルト設定としました。
タスクを追加画面
4.1.5 プレビュー(テスト)
抽出・加工準備後、プレビュー機能で実行結果を確認します。
タスクを追加画面
4.1.6 同期先の指定
必要に応じて、同期先の接続に対し対象のデータベース名、テーブル名を指定します。
同期先情報画面

4.1.7 タスクスケジュール指定
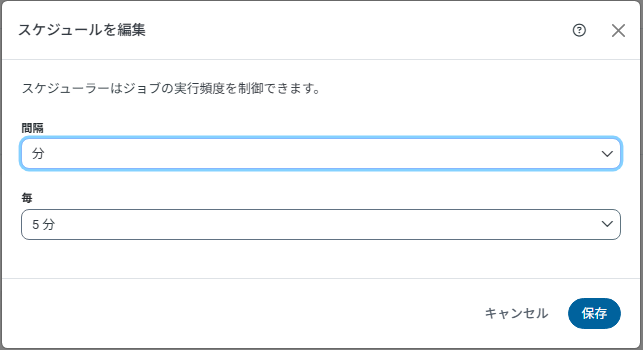
ジョブ画面に戻りスケジュールを指定します。cron設定同様に開始間隔、間隔値を指定します。
・ジョブ画面でスケジュールを設定(間隔指定、最小1分)
スケジュール編集画面
注釈
実行時には大量のログが生成・読み込まれます。そのため、ログによるサーバーリソースの消費にご注意ください。
重要
スケジュールは、保存と同時に適用されます。スケジュールの設定は、ジョブやタスクの設定完了後に行ってください。
4.1.8 ジョブの実行
作成したジョブは、手動実行が可能です。作成したジョブをテストするため実行します。
ジョブ画面

4.1.9 ジョブの結果
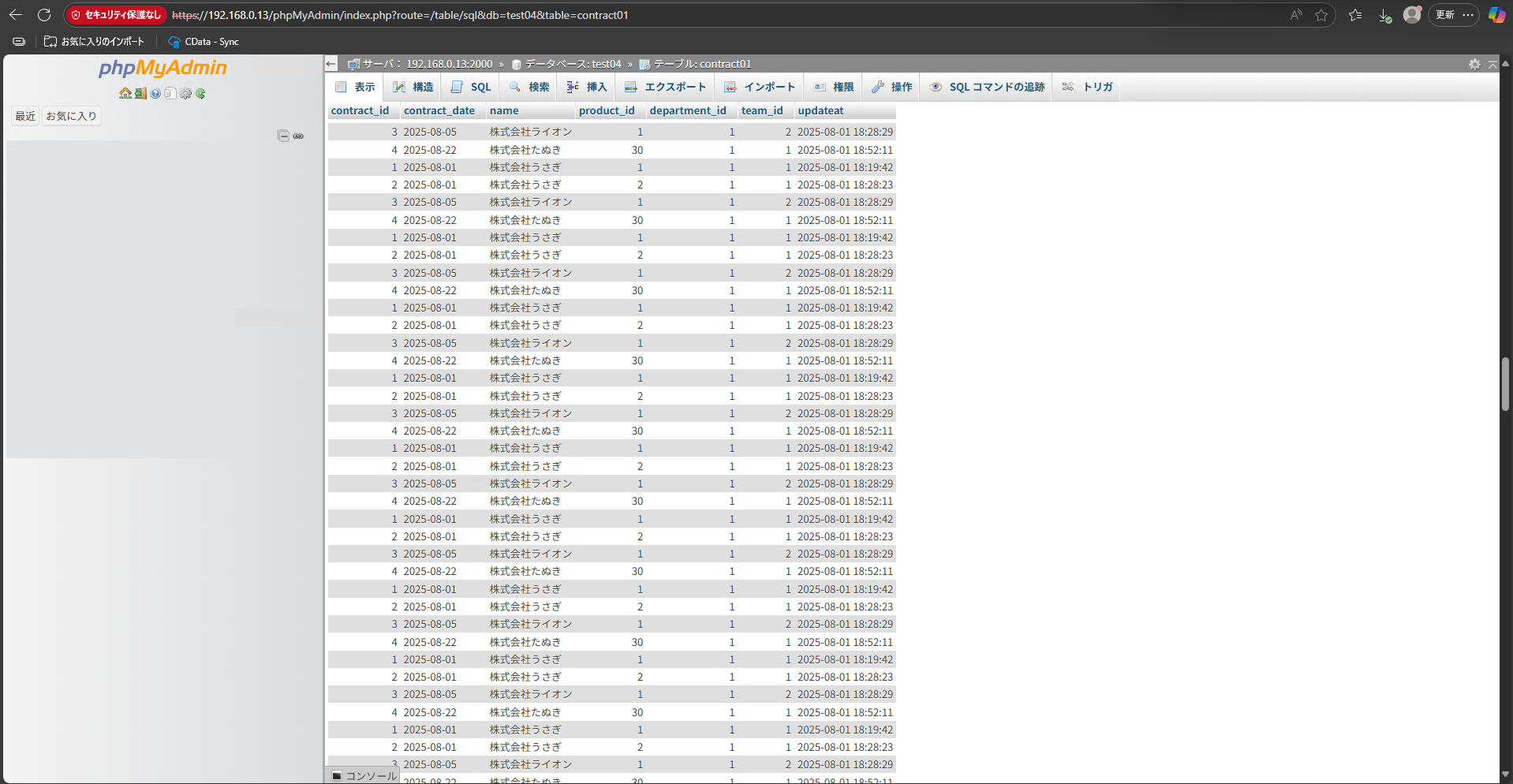
ジョブが成功すると、スケジュールに従ってテーブルがレプリケーションされます。
差分チェック用のカラムなどが未設定の場合、毎回すべてのデータが追加されます。
実行結果画面
注釈
高度な設定では、キャッシュや追加の前に、テーブルやテーブルデータを削除することが可能です。
4.2 差分レプリケーション
4.2.1 シナリオ概要
今後、contract01のレプリケーション量が増加することを見越し、差分のみをレプリケーションする場合の手順を説明します。
4.2.2 カラムの設定
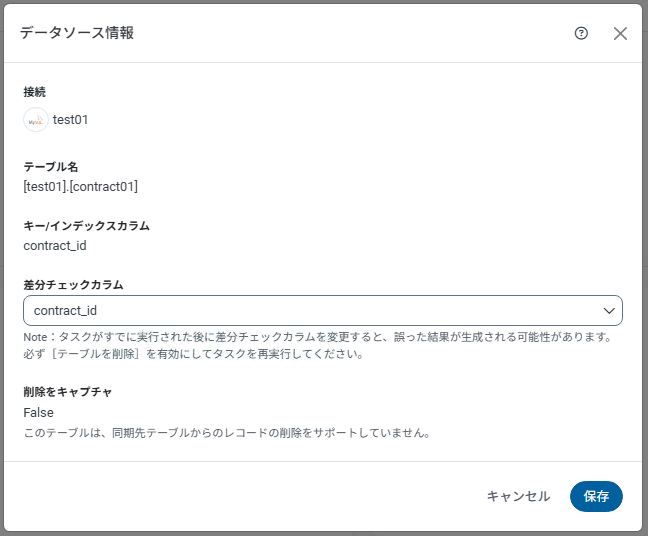
既存ジョブのカラム設定で、差分チェック用カラム(例:contract_id)を設定します。
・ジョブ >>> 対象ジョブを選択 >>> 対象カラムを選択 >>> 概要 >>> データソース情報 編集画面を表示
・差分チェック用カラムにcontract_idを指定
データソース画面
4.2.3 ジョブの設定
ジョブ画面で「差分レプリケーション」を追加設定します。
・ ジョブ >>> 差分レプリケーションを編集を表示
・ レプリケーション間隔を設定
差分レプリケーション画面
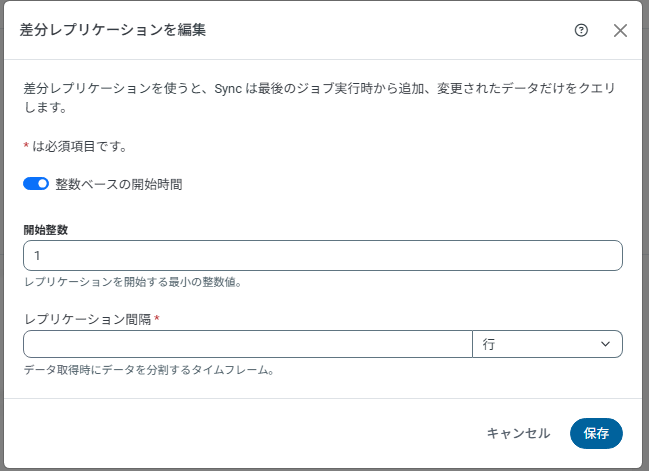
注釈
開始日/開始整数は、データソースの最小開始日または自動インクリメントカラムの最小整数値(データソースの最も古い利用可能なレコード)から、データのレプリケーションを開始します。開始日と開始整数のどちらを設定するかは、整数ベースの開始時間の設定状況に応じて選択します。
4.2.4 実行結果
設定を再度行い、実行します。再実行後は、設定したカラムと値を参照し、差分のみをレプリケーションします。
データソース画面
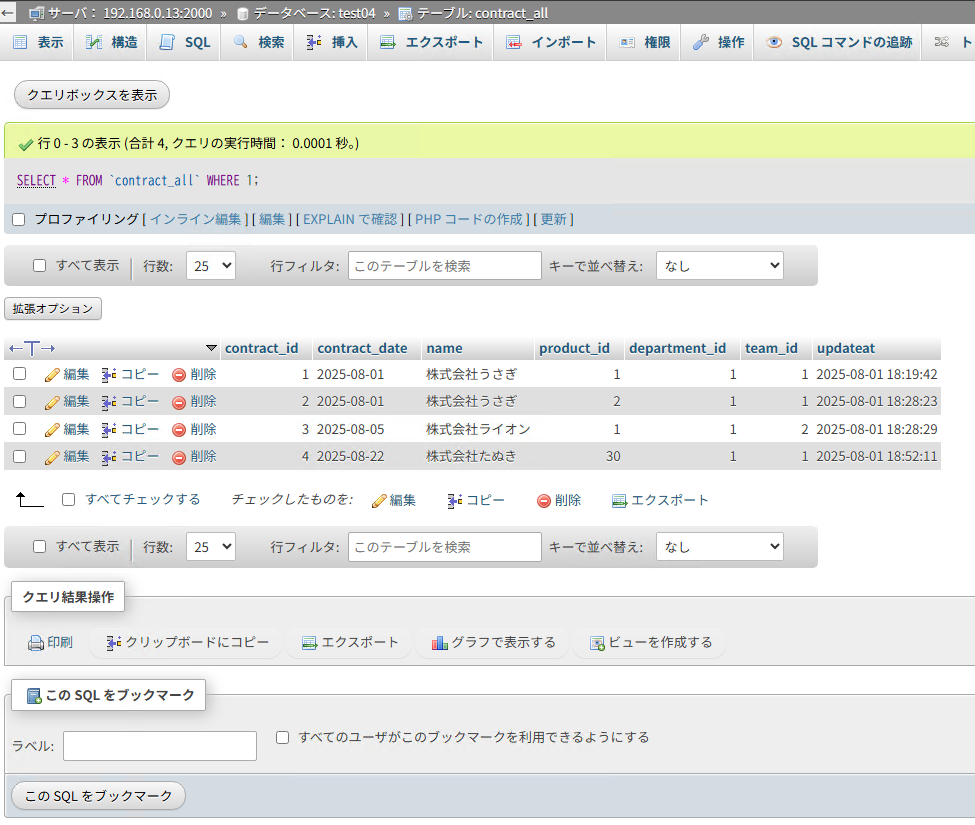
注釈
差分情報を掲載するため、test04に別のテーブル(contract_all)を作成、レプリケーションを実行しました。
注釈
古いテーブルやテーブルデータがキャッシュされていることなどが原因で、正常に動作しない可能性があります。エラーが発生した場合は、高度な設定からレプリケーション前に削除を実行してください。