CData Sync DBアプライアンスにおけるデータ抽出および加工手順(条件変更編)
[更新: 2025年10月8日]
本記事では、弊社にて実施した検証の一部データを公開しております。ご参考としてご活用いただけますと幸いです。
1. はじめに
本記事は、CData Syncを利用したデータ抽出および加工の基本的な設定手順について解説いたします
実際の検証データをもとに、設定例および操作手順をまとめております。
注釈
個別の要件定義や設計、開発・設定のサポートは、CData Syncのサービスには含まれませんのでご注意ください。
2. 検証環境の概要
2.1 検証条件
CData Syncバージョン:
25.1.9285.0仮想サーバーの構築やWindows Server OSの基本設定については、本記事では割愛いたします。
GUIは日本語表示を前提に解説しております。
解説に登場するデータベース情報は、前項をご参照ください。
カスタムクエリのサンプルは参考用としてご提供しております。クエリの開発や設計はサービスに含まれておりませんのでご注意ください。
カスタムクエリのご利用により生じた損害については、直接・間接を問わず一切の責任を負いかねます。
注釈
Windows Server OSのグループポリシーやセキュリティ設定は、OS管理者が別途設定する必要があります。
3. CData Syncの概要と前提
CData Syncは、データベースやSaaSサービス、ファイルのデータを抽出・加工・転送できるETL/ELTツールです。
本記事では、CData Syncがインストール済みのWindows Server OSサーバー上で、サブスクリプションキーの設定が完了していることを前提に解説いたします。
4. CData Syncによるデータレプリケーション手順
4.1 レプリケーション先テーブルの指定(カスタムクエリ)
4.1.1 シナリオ概要
部署Dが、test01データベース内のcontract01テーブルおよびcontract02テーブルを同一テーブルで分析するため、test04データベースの指定テーブルへデータを追加する必要がある、という想定で手順を説明します。
このシナリオをもとに、設定手順および結果を掲載いたします。
4.1.2 変更点
基本的な設定は前回の解説と同様ですが、以下の変更点を考慮し設定を行います。
1. test04の指定テーブルに対してETL処理を実施する
2. 差分データのみを追加する
3. 一部カラムの調整を行う
4.1.3 test04の指定テーブル
分析用テーブルへの集約を目的として、各ジョブおよびタスク設定において、データベース/スキーマ/テーブルを指定します。
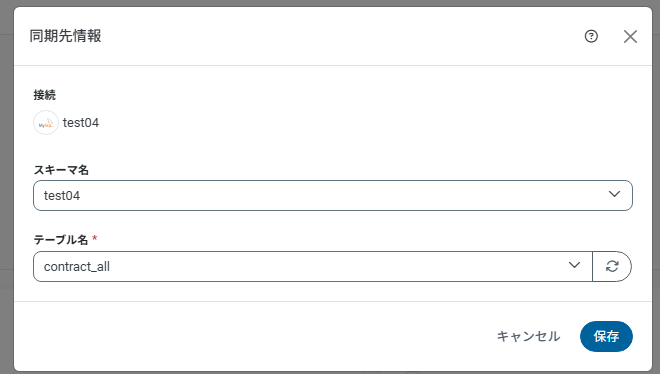
前回同様、ジョブおよびタスクを作成し、同期先情報には同一のスキーマ名およびテーブル名を指定します。
同期先情報画面
注釈
事前にデータベース test04に対し、適当な分析用テーブルの作成が必要です。参考掲載は contract_all テーブルを作成済みです。
重要
対応するカラムが存在しない場合、[0] [42S21] Duplicate column name 'hogehoge' (1060) などのエラーがジョブ履歴に記録されます。エラー発生の際は、記録内容を確認後にカラムマッピング、同期先のテーブルを調整するなどを実施してください。
4.1.4 差分レプリケーション
前述と同様に、差分レプリケーションをジョブおよびタスクに設定します。
設定方法は前回の解説をご参照ください。
4.1.5 カラムの一部を調整
元テーブルのカラムについて、以下のマッピングをカスタムクエリで調整しています。
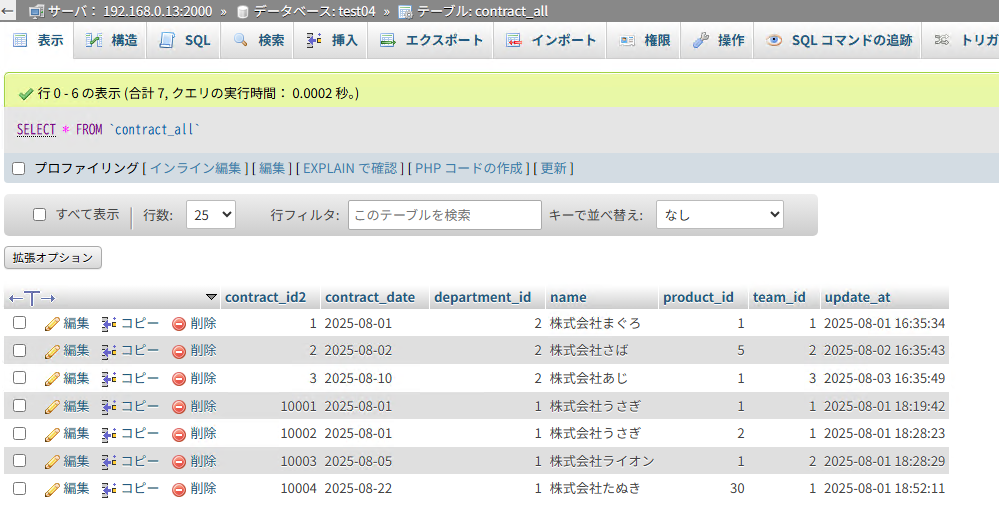
ジョブ1 カラム(contract01→contract_all)
1. [contract_id]に10000を加算し、[contract_id2]カラムとしてID重複を回避
2. 「updateat」カラムを「update_at」として別名でレプリケーション
3. カスタムクエリで「contract_id」を「contract_id2」として別名指定し、レプリケーション
REPLICATE [test04].[contract_all] WITH IncrementalCheckColumns = 'contract_id'
SELECT [contract_id] + 10000 AS [contract_id2], [contract_date], [department_id], [name], [product_id], [team_id],
updateat AS update_at FROM [test01].[contract01]
ジョブ2 カラム(contract02→contract_all)
1. 「updateat」カラムを「update_at」として別名でレプリケーション
REPLICATE [test04].[contract_all] WITH IncrementalCheckColumns = 'contract_id'
SELECT [contract_id] AS [contract_id2], [contract_date], [department_id], [name], [product_id], [team_id], [updateat] as [update_at]
FROM [test02].[contract02]
注釈
主キーやカラムマッピングの設定によっては、ジョブが正常終了してもデータベース側の制約によりレプリケーションが実行されない場合があります。
4.1.6 レプリケーション結果
レプリケーションが実行されると、contract_allテーブルが更新されます。
contract_all 結果
4.2 月毎にテーブルをレプリケーション
4.2.1 シナリオ概要
部署Dでは、一時的に1月および2月のtest01データベース内contract01テーブルの差分を確認するため、テーブル名を変更しレプリケーションを実施する必要が生じました。
このシナリオをもとに、設定手順および結果を掲載いたします。
4.2.2 イベントについて
イベント機能を利用することで、Syncアプリケーションに含まれるXMLベースのAPIScriptを用いてクエリパラメータの挿入や外部処理のトリガーが可能です。
本事例では、ジョブ実行前後に日時を取得し、テーブル名に付与する想定です。
<!-- NOTE: Do not edit api:info -->
<api:info title="Before Run" desc="This event is fired before running a job.">
<input name="JobName" required="true" desc="The name of the job being executed." />
<input name="Source" required="true" desc="The name of source connection." />
<input name="Destination" required="true" desc="The name of destination connection." />
<input name="JobStatus" required="true" desc="The previous job status." />
<output name="env:*" desc="A variable to be used later in the Job" />
<output name="CancelJob" desc="Set to true if you want to cancel job execution." />
</api:info>
<!-- Code goes here -->
4.2.3 変更点
基本設定は前回と同様ですが、以下の変更点を考慮し設定を行います。
1. ジョブのPre-Jobイベントを修正
2. Pre-Jobイベントで取得した値をテーブル名に付与
4.2.4 イベントの修正
Pre-Jobイベントに日時取得のコードを追加します。
<!-- NOTE: Do not edit api:info -->
<api:info title="Before Run" desc="This event is fired before running a job.">
<input name="JobName" required="true" desc="The name of the job being executed." />
<input name="Source" required="true" desc="The name of source connection." />
<input name="Destination" required="true" desc="The name of destination connection." />
<input name="JobStatus" required="true" desc="The previous job status." />
<output name="env:*" desc="A variable to be used later in the Job" />
<output name="CancelJob" desc="Set to true if you want to cancel job execution." />
</api:info>
<!-- Code goes here -->
<api:set attr="out.env:run_ts" value="[null | now('yyyyMMddHHmmss')]" />
<api:push item="out"/>
4.2.5 カスタムクエリの修正
env:run_ts に代入された「yyyyMMddHHmmss」形式の値をテーブル名に付与します。
レプリケーション実行前に日時を取得し、該当テーブルへレプリケーションを実施します。
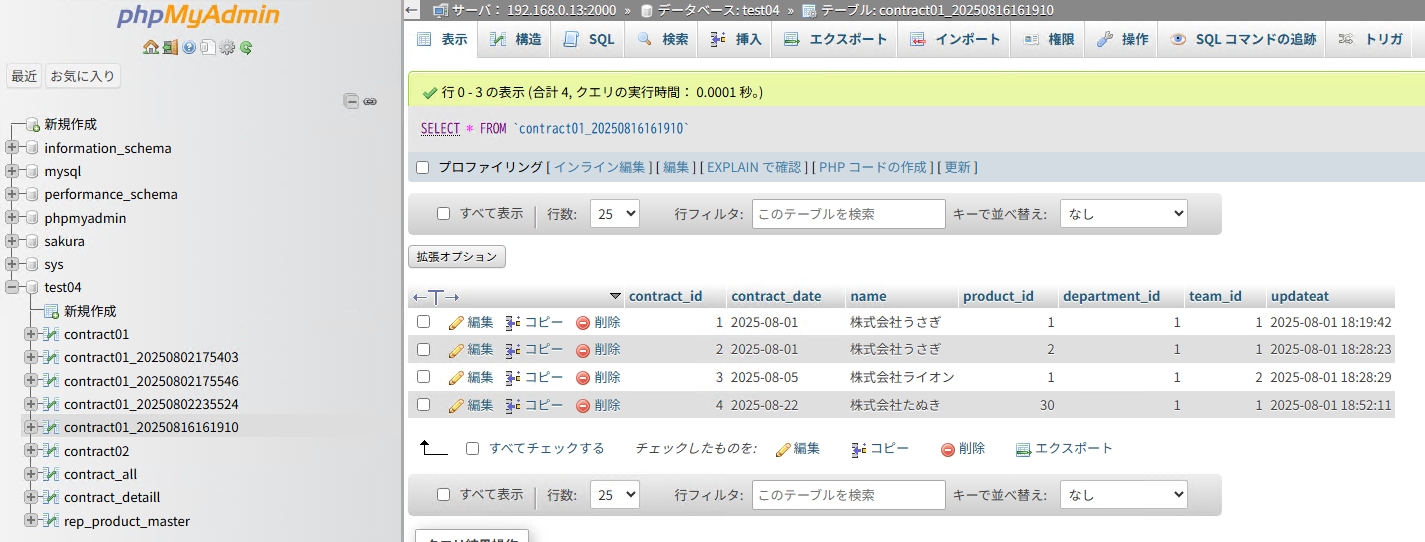
REPLICATE [contract01_{env:run_ts}] SELECT * FROM [contract01]
注釈
スケジュール設定の詳細は割愛いたします。
4.2.6 レプリケーション結果
手動でレプリケーションを実行すると、 contract01_{env:run_ts} テーブルが更新されます。
contract01_{env:run_ts} 結果
4.3 特定条件のデータをレプリケーション
4.3.1 シナリオ概要
部署Dでは、部署Cが管理するproduct_masterテーブルから特定データのみをレプリケーションする必要が生じました。
このシナリオをもとに、設定手順および結果を掲載いたします。
注釈
既に解説済みの操作については省略し、カスタムクエリの内容のみ記載します。
4.3.2 product_masterテーブル
部署Cは、取引先から仕入れる製品のマスタデータをtest03データベースのproduct_masterテーブルにて管理・更新しています。
仕入不可となった製品については、eolカラムに1を設定する運用です。
SELECT * FROM `product_master` WHERE 1;
product_id product_name amount eol updateat
1 水 100 0 2025-08-02 13:32:22
2 肉 500 0 2025-08-02 13:32:47
3 卵 80 0 2025-08-02 13:33:50
4 大根 150 1 2025-08-02 13:36:22
5 ちくわ 100 0 2025-08-02 13:38:24
30 からし 100 0 2025-08-02 13:38:37
4.3.3 変更点
基本設定は前回と同様ですが、以下の変更点を考慮し設定を行います。
1. カスタムクエリにwhere句を追加
2. テーブル名にプレフィックスを追加し、変更を明示
4.3.4 カスタムクエリの修正
SQLのwhere句を追加することで、特定レコードのみをレプリケーション対象とします。
本例では、eol=0(取引中)を条件に設定しています
REPLICATE [test04].[product_master] WITH IncrementalCheckColumns = 'updateat' SELECT * FROM [test03].[product_master] WHERE [eol] = 0
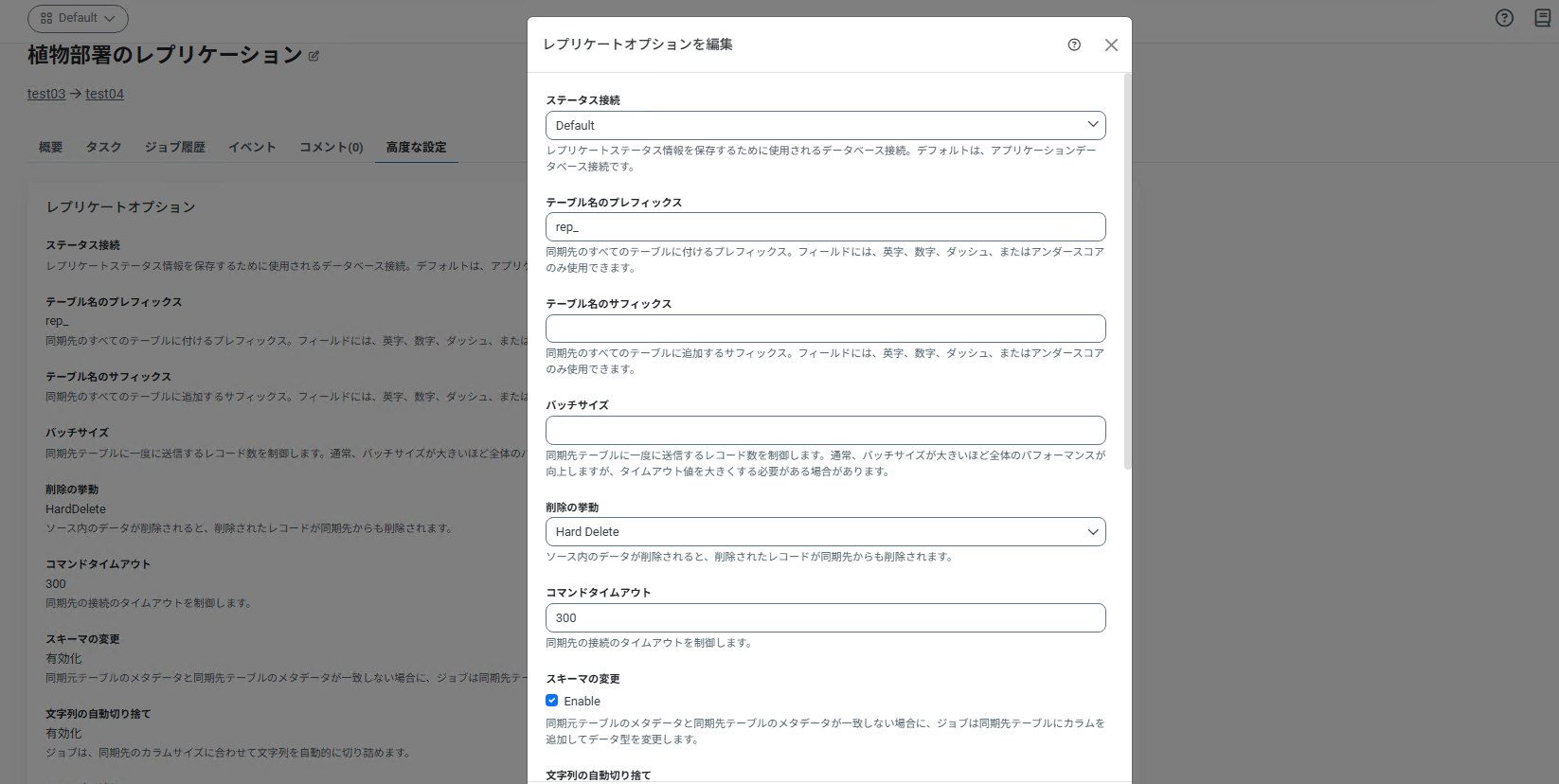
4.3.5 テーブル名のプレフィックスを追加設定
ジョブの高度な設定にて、テーブル名のプレフィックスを追加することが可能です。
本設定を利用し、「rep_product_master」テーブル名でレプリケーションを実施します。
テーブル名のプレフィックス設定
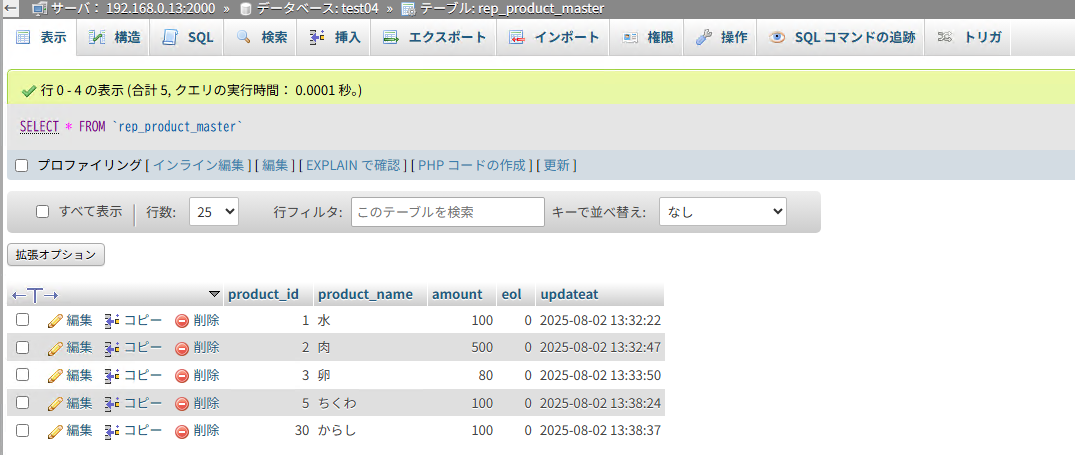
4.3.6 レプリケーション結果
手動でレプリケーションを実行すると、該当テーブルが更新されます。
レプリケーション結果
4.4 特定条件のデータをレプリケーション
4.4.1 シナリオ概要
部署Dは、新設された部署Eからの要望により、毎月特定データの提供が必要となりました。
このシナリオをもとに、設定手順および結果を掲載いたします。
注釈
※既に解説済みの操作については省略し、カスタムクエリの内容のみ記載します。
重要
本操作はあくまで参考例です。運用やBIツール、サービスの要件に応じてご利用ください
4.4.2 部署Eの要望
基本設定は前回と同様ですが、以下の変更点を考慮し設定を行います。
1. test04内のrep_product_masterとcontract01を結合したテーブル(contract_detail)を毎月レプリケーション
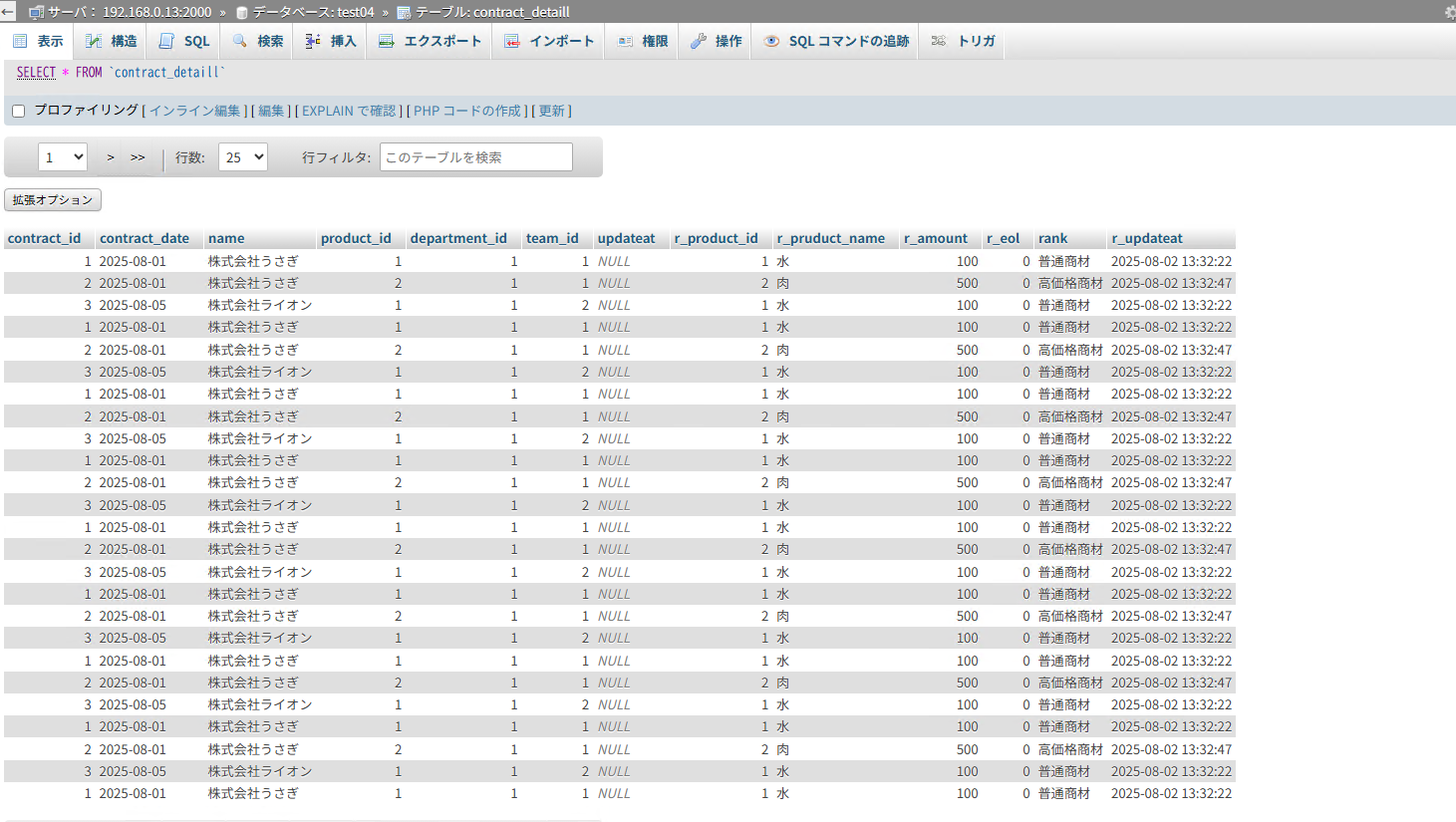
2. rankカラムを追加し、amountの値に応じて「高価格商材」「普通商材」「低価格商材」と分類
3. contract_detailは常に最新のテーブル情報を参照し更新
4.4.3 接続の設定
ジョブには、データソースおよび同期先の両方にtest04を指定する必要があります
この場合、データソース用と同期先用でtest04への接続設定を2つ用意してください。
注釈
接続方法は、前ページの解説と重複するため省略いたします。
4.4.4 カスタムクエリ
SQLクエリと同様に、カスタムクエリで要件を満たすクエリを作成し、レプリケーションのスケジュールを毎月に設定します。
REPLICATE [contract_detail]
SELECT c.*,
r.product_id AS r_product_id,
r.product_name AS r_product_name,
r.amount AS r_amount,
r.eol AS r_eol,
CASE
WHEN r.amount >= 250 THEN '高価格商材'
WHEN r.amount >= 100 THEN '普通商材'
ELSE '低価格商材'
END AS `rank`,
r.updateat AS r_updateat
FROM [test04].[contract01] AS c
left join [test04].[rep_product_master] AS r
on c.[product_id] = r.[product_id]
4.4.6 レプリケーション結果
手動でレプリケーションを実行すると、contract_detailテーブルが更新されます。
レプリケーション結果