CData Sync CData Syncを利用したデータベースの引っ越し(移行)
[更新: 2025年10月8日]
本記事は、弊社で検証したデータの一部を公開しています。ご参考としてご活用ください。
1. はじめに
本記事は、CData Syncを用いたデータ抽出および加工、転送(ETL)の基本設定手順を解説します。
実際の検証データをもとに、設定例や操作手順をまとめています。
注釈
個別の要件定義や設計、開発・設定のサポートは、CData Syncのサービスには含まれませんのでご注意ください。
1.2 概要
本TIPSは、MySQLからMicrosoft SQL Serverへの方法を解説するページです。詳細は下記をご確認ください。
2. 前提条件(環境・制約)
2.1 CData Sync 対象サービス / バージョン
項目 |
内容 |
|---|---|
対象サービス |
CData Sync Enterprise 相当(検証ライセンス) |
バージョン |
0.1 |
検証環境 |
さくらのクラウド |
最終検証日 |
2025年9月8日 |
注釈
本TIPSの検証条件は上表の通りです。環境差により結果が異なる場合があります。
2.2 検証環境(OS・ミドルウェア・クラウド構成)
基になるデータは、社内のオンプレ環境からさくらのクラウドのVM環境に作成したMicrosoft SQL Serverへのデータ移行です。
単純なローカルネットワークに3台が配置されているイメージです。そのため構成図は省略いたします。
項目 |
内容 |
|---|---|
仮想サーバー |
5core16GB |
ディスク |
100GB |
ローカルネットワーク |
1Gbps |
OS |
Windows Server 2022 Datacenter Edition |
データベース |
Microsoft SQL Server 2022 |
項目 |
内容 |
|---|---|
仮想サーバー |
4core16GB |
ディスク |
250GB |
ローカルネットワーク |
1Gbps |
OS |
Windows Server 2022 Datacenter Edition |
CData Sync |
CData Sync Enterprise 相当(検証ライセンス) |
注釈
オンプレ環境は、非公開のため省略いたします。
2.3 必要な権限・ライセンス・前提知識
本検証環境は、事前に下記の準備が必要です。
各データベースへのアクセス権
CData Sync Standard以上のライセンス
サーバー、ネットワーク、SQLに関する基礎知識
2.4 注意事項(免責、サポート範囲外など)
TIPSは、検証データを基に参考手順、参考設定方法を掲載する目的で作成されます。参考までにご利用ください。
本ページの記載は、あくまで参考となります。本ページに関するサポート、お問い合わせはお控えください。
本ページに掲載する情報のご利用による損害が直接的又は間接的かを問わず、一切の責任を負いません。
3. 手順
3.1 xxxx
3.1.1 シナリオ概要
本TIPSは、下記のシナリオを想定、記載いたします。
1. MySQLからデータベースの一部テーブルのレプリケーション(複製)、データの移行を実施する。
2. サーバーとデータベースの設定は、基本デフォルトとする。
3. 最後にどの程度処理に時間を要するか計測が必要。
1. 接続1:MySQLと接続2:MS SQL Serverを接続に作成、ジョブを作成しテーブルのレプリケーションを実施する。
2. MySQLのスキーマは、基の環境参照し変更なし。MS SQL Serverの設定は、初期状態から変更なし。
3. レプリケーションの時間計測を実施する。
3.1.2 接続の設定
CData Syncは、既にライセンスをアクティベーション済みです。各データベースへの接続設定を実施します。
接続 > コネクタを選択 > 新しい接続 をクリック、設定を開始します。
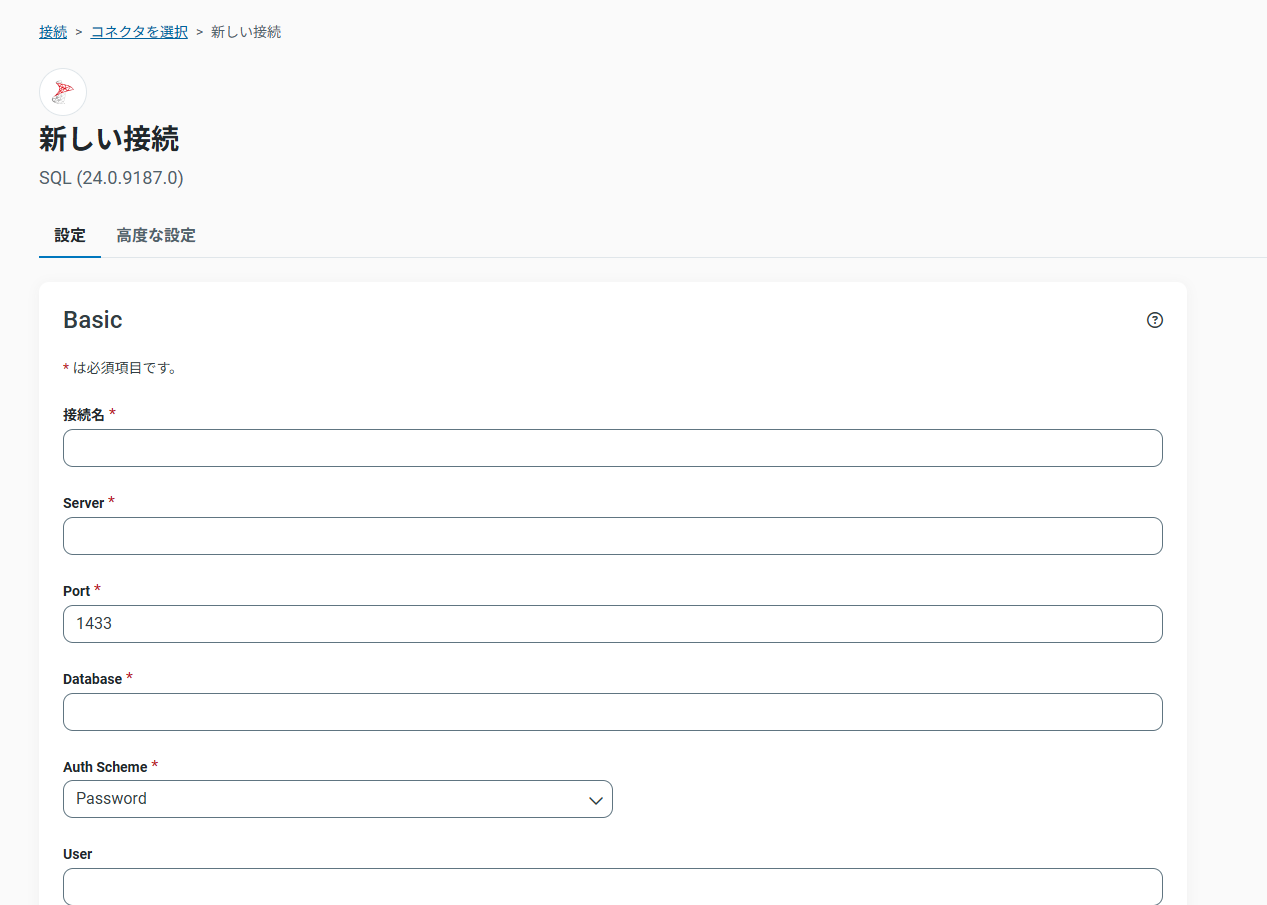
MS SQL Serverの接続
コネクタは、SQL Serverを選択、データベース情報とアクセス権を設定します。
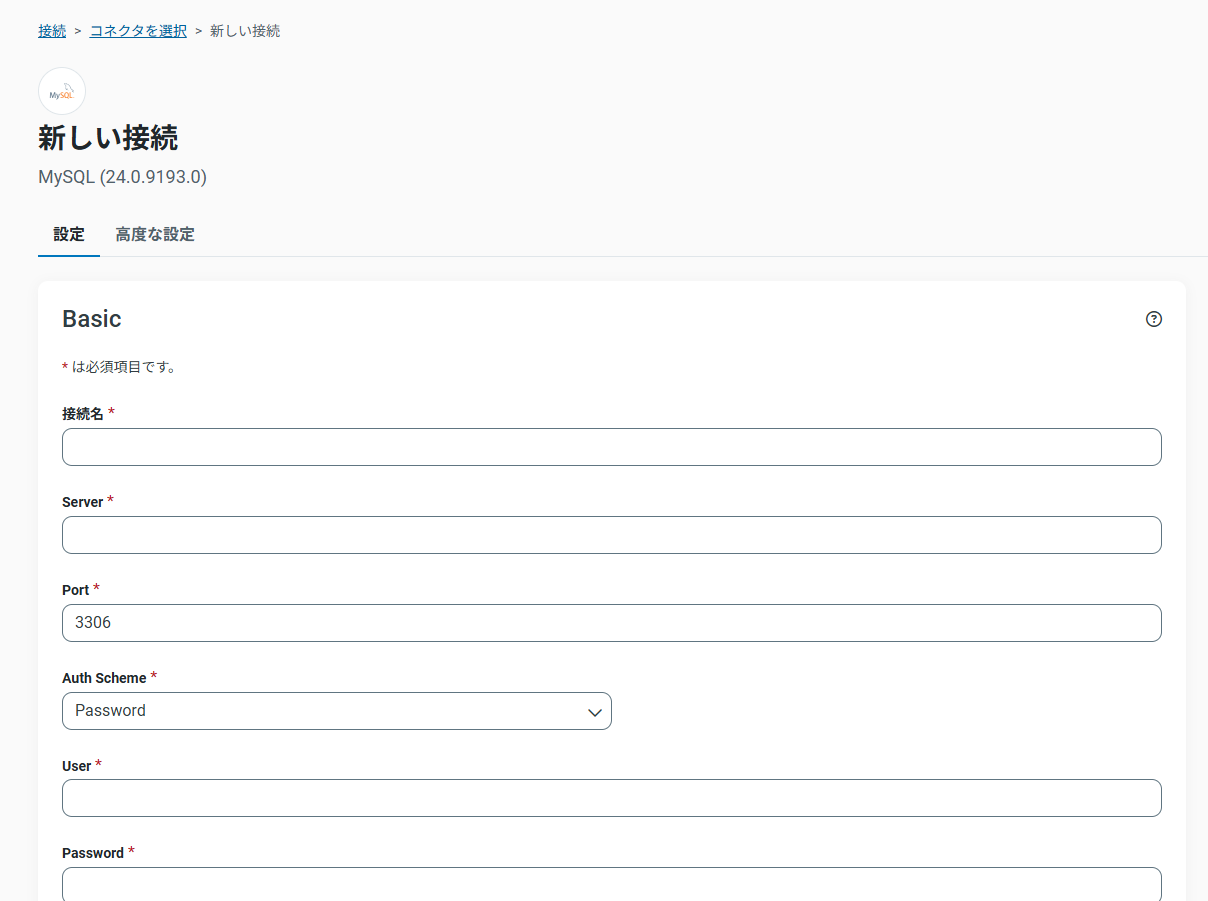
MySQLの接続
コネクタは、MySQLを選択、データベース情報とアクセス権を設定します。
3.1.3 ジョブの設定
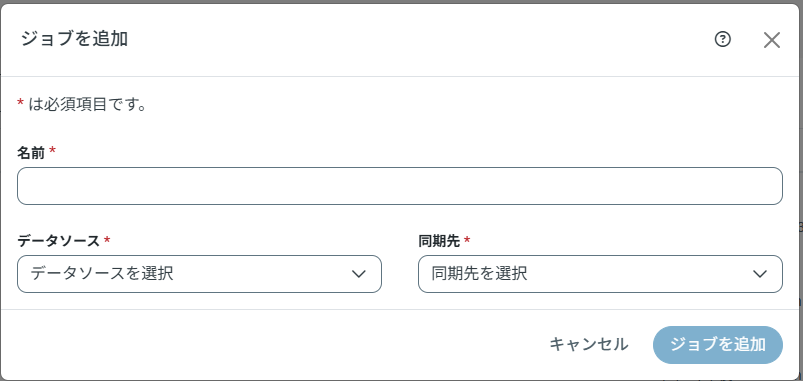
ジョブを設定します。追加した接続を利用、ジョブの名前を入力、作成します。
ジョブの設定
3.1.4 カスタムクエリの設定
今回のテーブルデータは、761012行~848250行のデータを移行します。
そのため CACHE を利用します。
CACHE [<テーブル名>] SELECT * FROM [<テーブル名>] WHERE <条件>
注釈
CACHEは、CData Syncがデータ連携時に一時的にローカル環境内にデータを保持する仕組みを指します。これにより負荷軽減、処理速度の向上を目指します。
重要
クエリのwhereについて、詳細は省略しますが、特定のテーブルを3回に分けて実行を意図し、3分割できるように作成しています。
4. 検証(確認方法)
カスタムクエリの設定後、スケジュールなどの設定を行います(毎月1回、AM3:00実行です)。
その後、定期的に実行しました。
name rows reserved data index_size unused
hogehoge 848250 228040 KB 227904 KB 8 KB 128 KB
ジョブの履歴(2025年8月分)
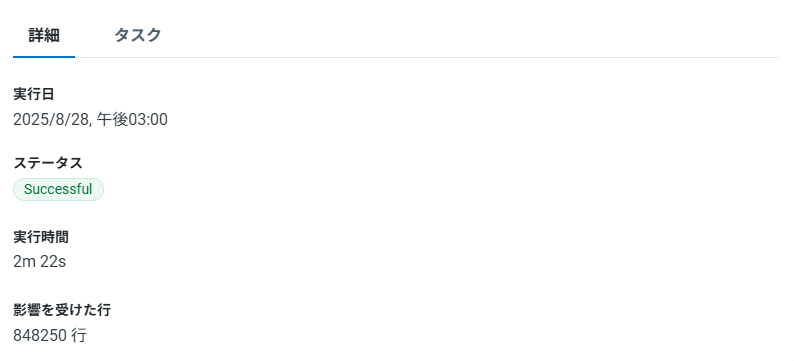
ジョブの履歴(過去5回)
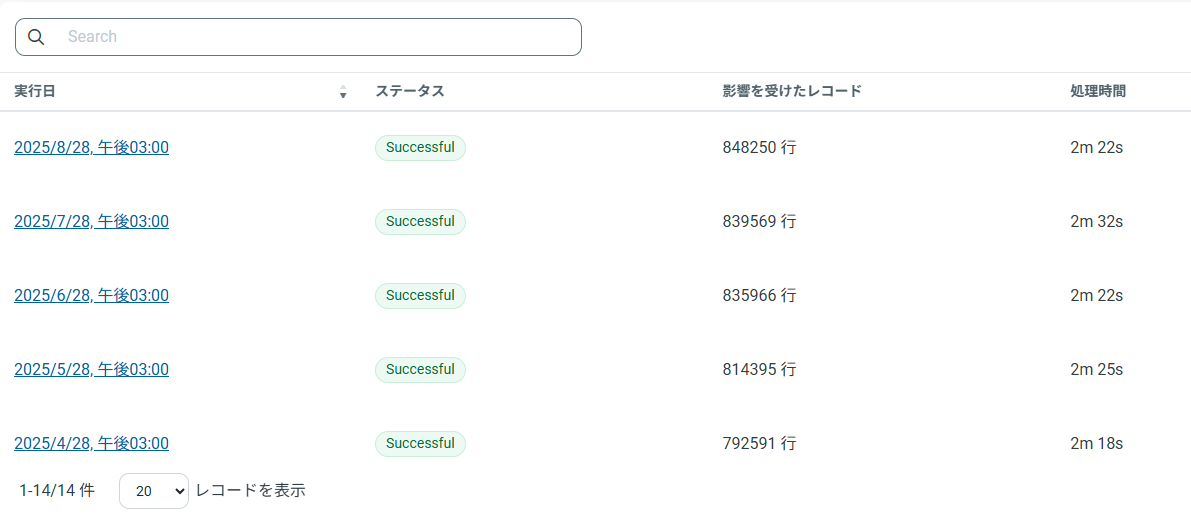
本スケジュールは月1のため中~小規模のデータまでになりますが、結果は、下記の様になりました。
約 228MB/84.8万行のテーブルを2分22秒で処理
行数ベース換算は、約5,960 行/秒
データ量ベース換算は、約1.6MB/秒
毎月約1~2万行増加、レプリケーションを実行しますが、処理時間に大きな変化は見受けられない。
3分割しているため8月の実態は、総行数:1,697,987行(848250行+425063行+424674行)、総実行時間:5m49s(2m 22s+1m 27s+2m)
注釈
アプリケーションログレベル:Allです。
重要
参考結果は、あくまで検証環境上のデータです。サーバーとネットワークリソース、データベース、共用環境に於けるリソース状況に左右されます。
4. 補足、何故データ移行でCData Syncを利用する?
DB標準のレプリケーション機能を利用することで、同様の結果を得ることも可能ですが、ドライバなどの実装、可視化/スケジューリング、監査証跡/ジョブ履歴などの運用とメンテナンスの側面までを想定すると、CData SyncなどのETLツールで管理するメリットがあります。
また、クラウド型のSaaSからCSVなどのテキスト形式も扱えるため、少人数で様々なデータを移行したい、中規模なデータからローカル環境に蓄積とBIツールを導入しデータウェアハウスを作りたいなどの要望でご利用ください。