操作ガイド
[更新: 2026年7月15日]
提供モデルとAPIドキュメント
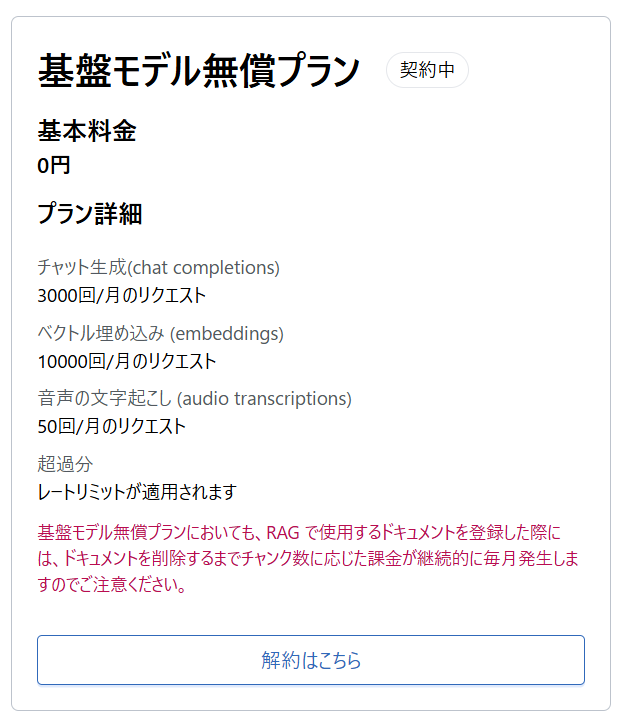
さくらのAI Engine が提供しているモデル
さくらのAI Engine が対応しているモデルは以下の通りです。
チャット生成モデル
ベクトル埋め込みモデル
音声の文字起こしモデル
実際に利用できるモデルは、コントロールパネルの左メニューから 利用可能なモデル を選択することで確認できます。
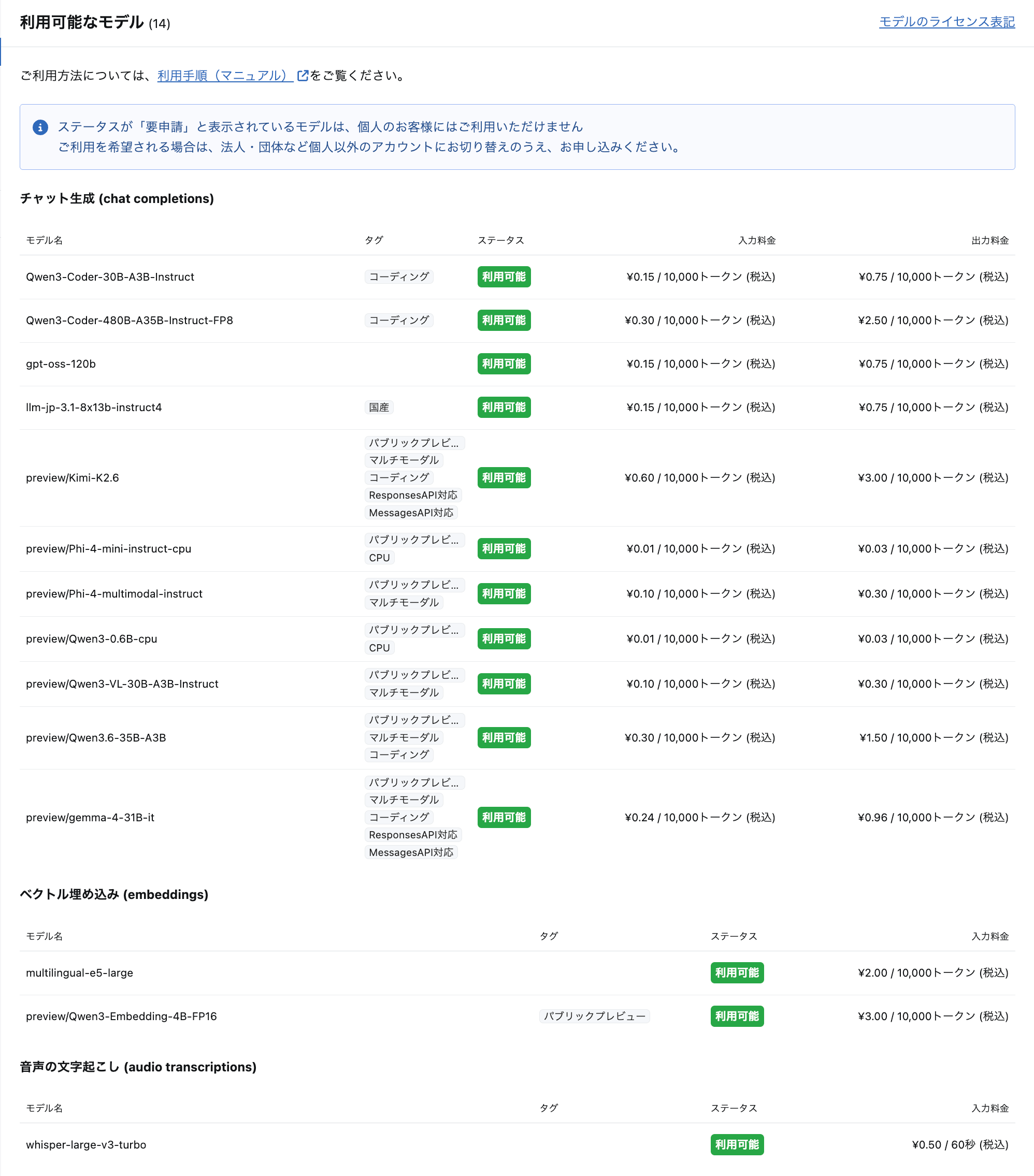
音声の読み上げモデル
実際に利用できるモデルは、コントロールパネルの左メニューから 利用可能な音声モデル を選択することで確認できます。
API ドキュメント
APIのドキュメントは以下の通りです。
チャット生成・音声文字起こし・音声合成、およびドキュメント・RAG APIでは、「アカウントトークンの発行」で発行したトークンを利用します。
ドキュメント・RAG API の使い方
さくらのAI Engine では、ホスティングしているLLMモデル用APIとは別に、RAGのためのAPIとベクトルストアを提供しています。
ドキュメント・RAG API の概要
Retrieval-Augmented Generation(RAG) とは、大規模言語モデル(LLM)が外部の知識ベースやドキュメントを検索(Retrieval)し、その検索結果を入力として取り込みながら応答を生成(Generation)する手法です。これによりLLMは本来知りえない企業内部のドキュメントや最新のニュースなどを回答することができます。
RAGの仕組みや処理フローは さくらのナレッジの記事 を参考にしてください。
RAGの構築においては、あらかじめ与えられ外部の知識をベクトル化して、専用ベクトルストアに格納する処理や、検索時に投入される質問をベクトル化して、ベクトルストアに検索を行う処理などの実装が必要となりますが、さくらのAI Engine ではそれらを実装することなくAPI呼び出しだけでRAGを構築できます。
さくらのAI Engine では、事前に登録したドキュメントをベクトル化してベクトルストアに格納しておき、質問に対してベクトルストアから検索し、指定したLLMモデルで自然な言語に変換するまでを一つのAPIコールで実行できます。
ドキュメントをアップロードするAPI
ドキュメントをアップロードするAPI( documents_upload )を利用して、ベクトルストアにドキュメントを追加できます。アップロードされたドキュメントは、指定した埋め込みモデルでベクトル化され、ベクトルストアに格納されます。
また、ドキュメントの一覧取得、詳細取得、名前やタグの更新、削除、チャンク単位の取得など、ドキュメント管理のためのAPIも用意されています。 各エンドポイントの詳細については、RAG API 仕様 をご参照ください。
ドキュメントアップロード時に利用可能なモデル
ドキュメントのアップロード時に利用できる埋め込みモデルは以下から選択できます。
埋め込みモデルはAPIリクエスト時に model パラメータで指定できます。
multilingual-e5-large(デフォルト)preview/Qwen3-Embedding-4B-FP16
ドキュメントアップロード時のチャンクサイズ
さくらのAI Engine にアップロードされたドキュメントは、指定したトークン長で分割してベクトル化し、格納されます。この分割単位をチャンクと呼び、その長さをチャンクサイズと呼びます。
検索はチャンク単位で行われ、検索結果として複数のチャンクが返される場合があります。
チャンクサイズはAPIリクエスト時に chunk_size パラメータで指定できます。
ドキュメントのアップロード時に各埋め込みモデルで指定できるチャンクサイズは以下の通りです。
モデル名 |
最小チャンクサイズ(トークン) |
最大チャンクサイズ(トークン) |
デフォルト値(トークン) |
|---|---|---|---|
|
256 |
512 |
512 |
|
256 |
32000 |
512 |
ドキュメントを参照するAPI
ドキュメントを参照するAPIとして、次の2種類のAPIを用意しています。
documents_query:ベクトルストアに対する自然言語の検索を実行します。回答はベクトルストアに保存されているドキュメントまたはその一部であるチャンクがそのまま出力されます。documents_chat:ベクトルストアに対する自然言語の検索を実行し、検索結果を利用して回答を生成します。回答は指定したLLMモデルにより自然な言語で生成されます。
通常RAGにおけるチャット生成では documents_chat を使って、1.投入された質問をベクトル化 2.ベクトルストアへの検索 3.検索結果を指定したLLMモデルで自然な言語に変換という3つのステップで行われますが、さくらのAI Engine はこれを一つのAPIコールで処理します。
RAGのAPIの利用においては、埋め込みモデルおよびチャットモデルの利用料金が発生します。
ベクトル検索に利用できる距離メトリクス
ベクトル検索における距離メトリクスとして、以下の2種類が利用可能です。
距離メトリクスはAPIリクエスト時に distance_type パラメータで指定できます。
cosine: Cosine距離l2: L2距離(ユークリッド距離)
RAGのクイックスタート
ここでは例としてPDFを検索対象にし、RAGを試します。 取り込んだPDFに対する単純な全文検索ではなく、LLMを活用してベクトル検索と自然な回答を生成します。
文章の取り込みは一般的なドキュメントフォーマット (txt,pdf,html,docx,xlsx,mdなど) に対応しています。
1. ドキュメントのベクトル化とベクトルストアへの保存
一般的に埋め込みと呼ばれる作業です。適当なテスト用PDFを用意して以下のコマンドを実行します。 <Token> は利用手順で取得したアカウントトークンに置き換えてください。 <uuid:シークレット> 形式のまま置き換えて実行します。
ドキュメントの保管には料金が発生します。基盤モデル無償プランの場合においても、ドキュメントの保管には料金が発生しますのでご注意ください。 また、ドキュメントのベクトル化の際にはembeddingsモデルの利用料金が発生します。
curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/documents/upload/ \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <Token>' \
--header 'Content-Type: multipart/form-data' \
--form "file=@document.pdf" \
--form "name=テストドキュメント" \
--form "tags=タグ1" \
--form "tags=タグ2" \
--form "model=multilingual-e5-large" \
--form "chunk_size=512"
レスポンス例:
{"id":f9ccb16f-b231-45d6-a7db-7cdcd077638a,"status":"pending","content":"","name":"テストドキュメント","tags":["タグ1","タグ2"],"model":"multilingual-e5-large","chunk_size":512}
しばらく待ってコンソール左メニューでドキュメントを選択すると、ドキュメントの取り込みが完了しています。
ドキュメントのベクトル化においては、アップロードされたファイル(PDF・テキストファイルなど)から自動的に文章を抽出し、検索や回答に利用します。 ただし、ファイル形式や状態によっては、正しく文章が取り込めない場合があります。
特に以下のような場合には、正確に解析できないことがあります。
画像として保存されたPDF(スキャンデータなど)
特殊なフォントやレイアウト(縦書き、段組み、数式や図表を多用したもの)
暗号化やパスワード保護されたファイル
非対応のファイル形式や破損したファイル
万一、正しく取り込めない場合は、以下をお試しください。
ファイル形式を変えて再度アップロードする
アップロードするファイルの状態を確認する(破損していないか、正しい形式かなど)
事前にテキストファイルに変換してからアップロードする
本サービスは、すべてのファイルの内容を完全に取り込めることを保証するものではありません。
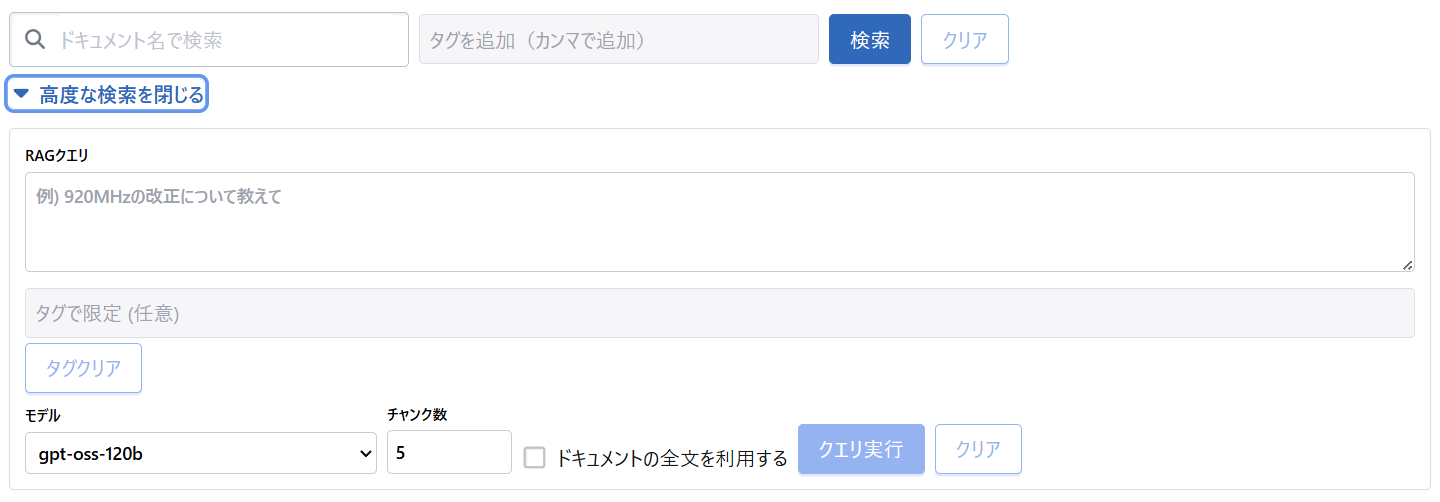
2. コントロールパネルからの検索の実行
質問したい内容を入力して クエリ実行 すると、結果が出力されます。
ここでは. documents_chat を使って、質問に対する自然な回答を生成します。
3. API経由のでのRAG実行
以下のコマンドを実行します。
curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/documents/chat/ \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <Token>' \
--header 'Content-Type: application/json' \
--data '{
"model": "multilingual-e5-large",
"chat_model": "gpt-oss-120b",
"query": "質問文",
"top_k": 3,
"threshold": 0.3,
"distance_type": "cosine",
}'
音声の文字起こし用APIの使い方
さくらのAI Engine では、Whisperというモデルをホスティングしており、音声データの文字起こしが可能です。mp3やwavをはじめ、m4aやmp4など幅広い音声・動画フォーマットに対応しているため、事前の形式変換なしに、会議やインタビューなどの録音データをそのまま議事録・書き起こし作成に活用できます。
音声の文字起こしのクイックスタート
以下は、MP3を検索対象として音声を文字起こすサンプルです。
1. 音声ファイルの文字起こしリクエスト
API同期型で動作するため、音声ファイルは30分、もしくは30MBの制限があります。
次のコマンドを実行します。 <Token> は利用手順で取得したアカウントトークンに置き換えてください。 <uuid:シークレット> 形式のまま置き換えて実行します。
curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/audio/transcriptions \
--header 'Accept: application/json' \
--header 'Authorization: Bearer <Token>' \
--header 'Content-Type: multipart/form-data' \
--form 'file=@sample.mp3' \
--form 'model=whisper-large-v3-turbo'
以下の様なレスポンスが戻ります。
{"text":"こんにちは。皆さん聞こえますか","model":"whisper-large-v3-turbo"}
対応拡張子
aac, m4a, mp3, mp4, ogg, wav などの一般的な音声・動画フォーマットに対応しています(記載は一例です)。
ただし、ファイルの状態によっては正しく文字起こしできない場合があります。 正しく処理できない場合は、以下をお試しください。
音声ファイルの形式を変更して再度アップロードする
アップロードする音声ファイルの状態を確認する(破損していないか、正しい形式かなど)
モノラル音声に変換してからアップロードする
また、本サービスは、すべての音声ファイルの内容を完全に文字起こしできることを保証するものではありません。 記載している対応形式は一例であり、サポートされるファイル形式は今後変更される場合があります。
音声合成用APIの使い方
さくらのAI Engine では、音声合成モデルをホスティングしており、テキストを音声に変換できます。
注釈
音声合成APIは、各音声合成モデルの利用規約に同意する必要があります。 各音声合成モデルの利用規約は、コントロールパネルからご確認ください。
音声合成のクイックスタート
以下は、テキストを音声に変換するサンプルです。
1. 音声合成リクエスト
API同期型で動作するため、文字数には1000文字程度の制限があります。
次のコマンドを実行します。 <Token> は利用手順で取得したアカウントトークンに置き換えてください。 <uuid:シークレット> 形式のまま置き換えて実行します。
curl --request POST \
--url https://api.ai.sakura.ad.jp/v1/audio/speech \
--header 'accept: audio/wav' \
--header 'Authorization: Bearer <Token>' \
--header 'Content-Type: application/json' \
--data '{
"model": "zundamon",
"input": "こんにちは、これは音声合成のサンプルです。",
"voice": "normal",
"response_format": "wav"
}' --output ./audio-speech-output.wav
サンプルリクエストでは、生成された音声ファイルは audio-speech-output.wav という名前で保存されます。
解約および解約時のRAGデータの取り扱い
RAGにアップロードしたドキュメント以外に、データは保管されていません。解約の際はすべてのドキュメントの削除をお願いします。 すべてのドキュメントを削除しないと解約できませんのでご注意ください。
解約手順
1. ドキュメント削除
コントロールパネルのドキュメント詳細画面から 削除する をクリックします。
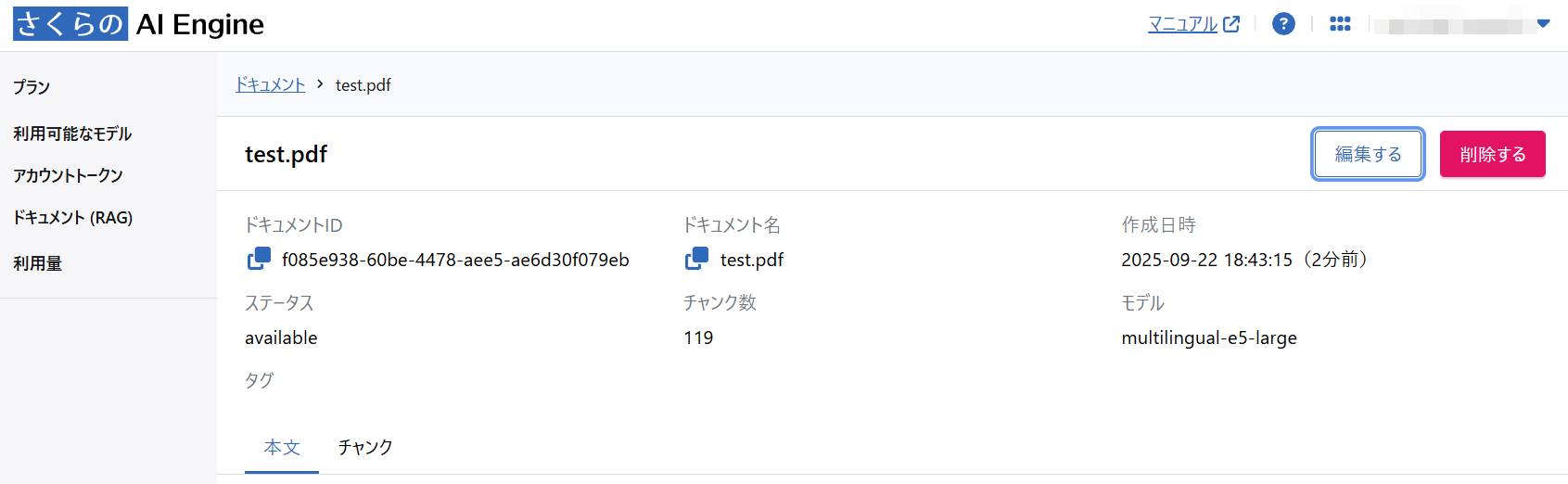
削除は、API経由でも実行できます。詳しくはAPIドキュメントをご覧ください。
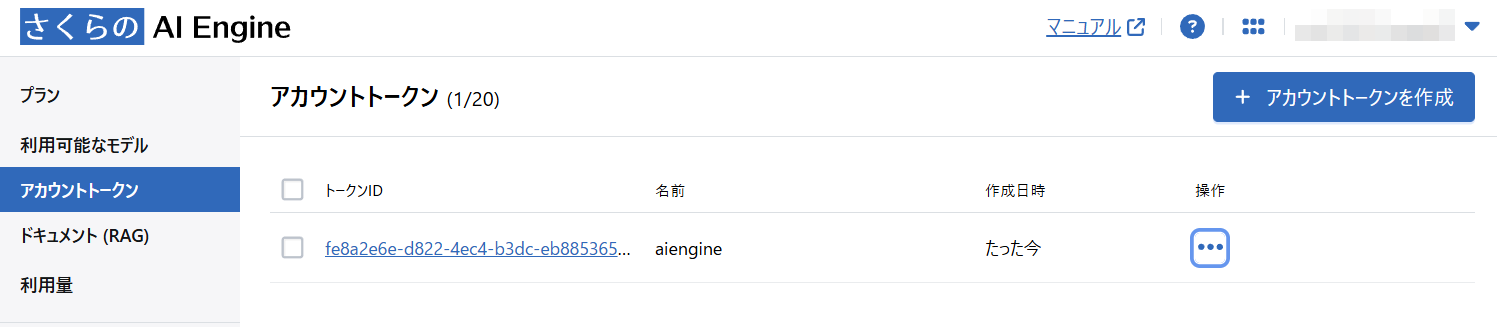
2. アカウントトークンの削除
コントロールパネルの左メニューからアカウントトークンを選択して、トークンを削除します。
3. 解約の操作
プラン選択画面にて 解約はこちら をクリックしてから、プラン解約画面にて プランを解約する をクリックします。