オートスケール
[更新: 2026年2月13日]
概要
オートスケール機能は、サーバに負荷が発生した際に対象サーバのスペックアップを行う「スケールアップ」と、台数を増やす「スケールアウト」の両方をご利用いただけます。サーバの負荷が解消されると、自動的にスケールダウンやスケールインが行われます。
さらに、水平スケールでは対象サーバに対してヘルスチェックを行い、異常(NG)と判定されたサーバを自動的に作り直して台数を維持する 台数維持機能 を利用できます。これにより、負荷変動に応じたスケーリングに加えて、障害発生時にも安定した台数を確保することが可能です。
ルータ+スイッチについても、スケールアップやスケールダウンが可能です。
オートスケールが動作するトリガーには アクティビティグラフ の「CPU時間(CPU TIME)」、または「ルータ+スイッチのアクティビティ」を10分間隔で監視して利用しています。
また、APIやEventBusを用いたスケール動作のトリガーにも対応しています。
※ 本機能には GitHub にて開発・公開しているオープンソース sacloud/autoscaler を使用しています。
ご利用にあたっての注意
料金について
さくらのクラウドの料金は1時間未満の端数は1時間として切り上げされます。 そのためオートスケールを実行するタイミングによっては、サーバ料金等が高くなる場合がありますのでご注意ください。
例:オートスケールの実行が3回行われて合計30分サーバを利用した場合
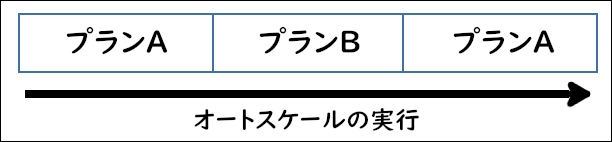
「プランAを10分 → プランBを10分 → プランAを10分」
プランAの料金:2時間
プランBの料金:1時間
となり、30分のご利用で3時間分の料金が発生します。
水平スケール時の動作について
サイズの大きなディスクをご利用されている場合、タイムアウトが発生する可能性がございますのでご注意ください。
追加・管理
コントロールパネル左側の「オートスケール」から新規追加や作成済みオートスケールの管理が可能です。
新規追加
事前準備(垂直スケール)
コントロールパネルからオートスケールの設定を行う前に、APIキーやオートスケールの対象となるサーバとエンハンスドロードバランサの準備が必要です。
本内容では例として、以下の構成でサーバとエンハンスドロードバランサの作成・設定を行っています。
東京第2ゾーンと石狩第2ゾーンにサーバを作成する
サーバには「nginx」をインストールしてWebサイトを公開する
エンハンスドロードバランサを作成して実サーバを追加する
オートスケールをスケールアップ(垂直スケール)で設定する
オートスケール機能で使用するAPIキーを作成します。
※作成方法は「 APIキー 」をご確認ください。
APIキーの種類 |
リソース操作APIキー |
|---|---|
アクセスレベル |
作成・削除 |
東京第2ゾーンと石狩第2ゾーンにオートスケールの対象となるサーバを作成します。
※本構成例では作成したサーバに「nginx」をインストールしてWebサイトを公開しています。
スケールアップ(垂直スケール)の場合
ゾーン |
東京第2ゾーン(tk1b) |
石狩第2ゾーン(is1b) |
|---|---|---|
名前 |
vscale-group-01 |
vscale-group-02 |
NIC |
共有セグメント |
共有セグメント |
エンハンスドロードバランサを作成して、実サーバ(オートスケールの対象となるサーバ)を追加します。
※作成方法は「 エンハンスドロードバランサ 」をご確認ください。
名前 |
autoscale-lb |
|---|
待ち受けポートを追加します。
オートスケールの作成
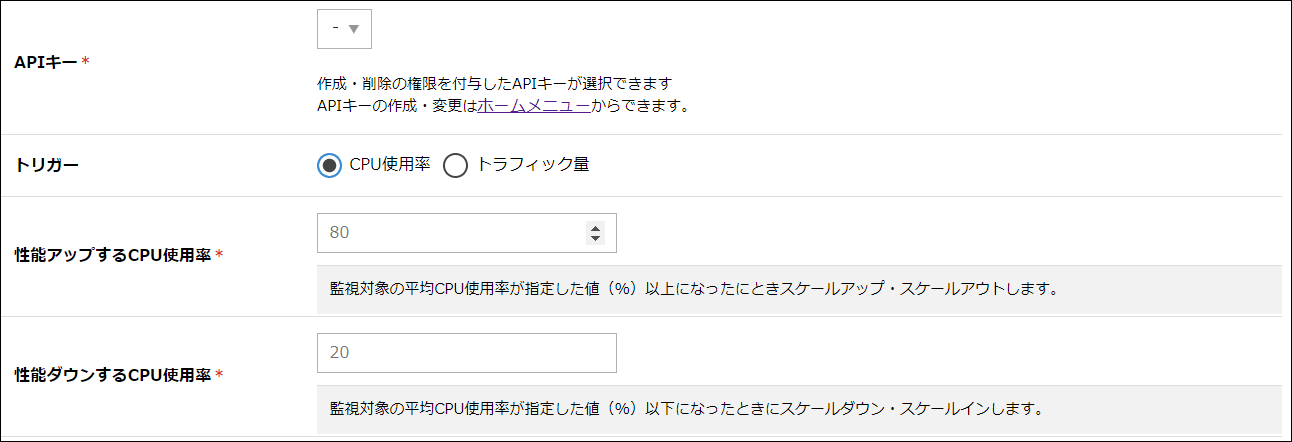
APIキー |
事前に作成したAPIキーを選択します。 |
|---|---|
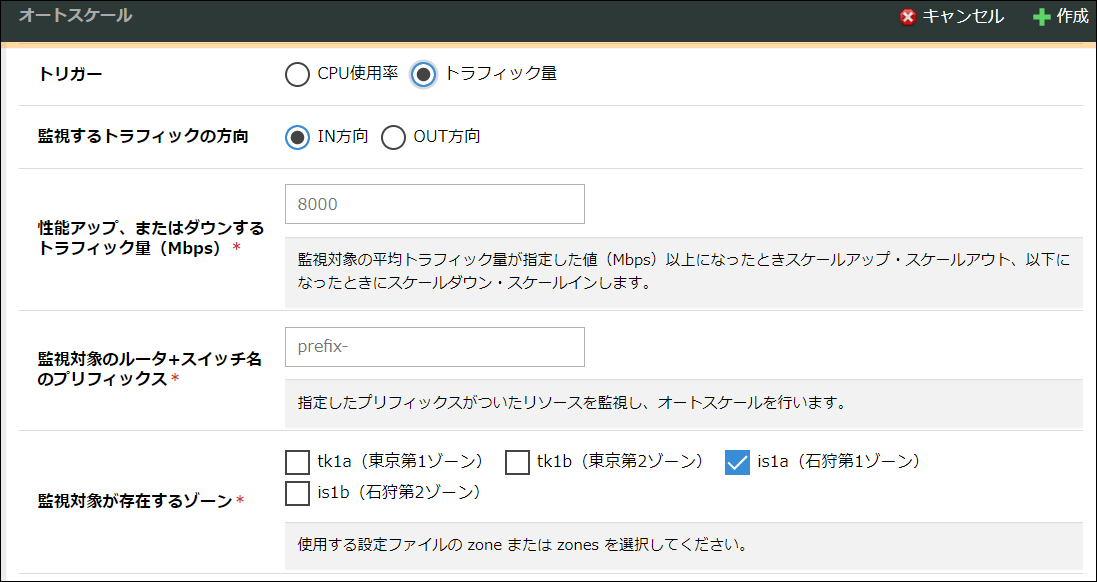
トリガー |
オートスケールが動作するトリガーを選択します。 |
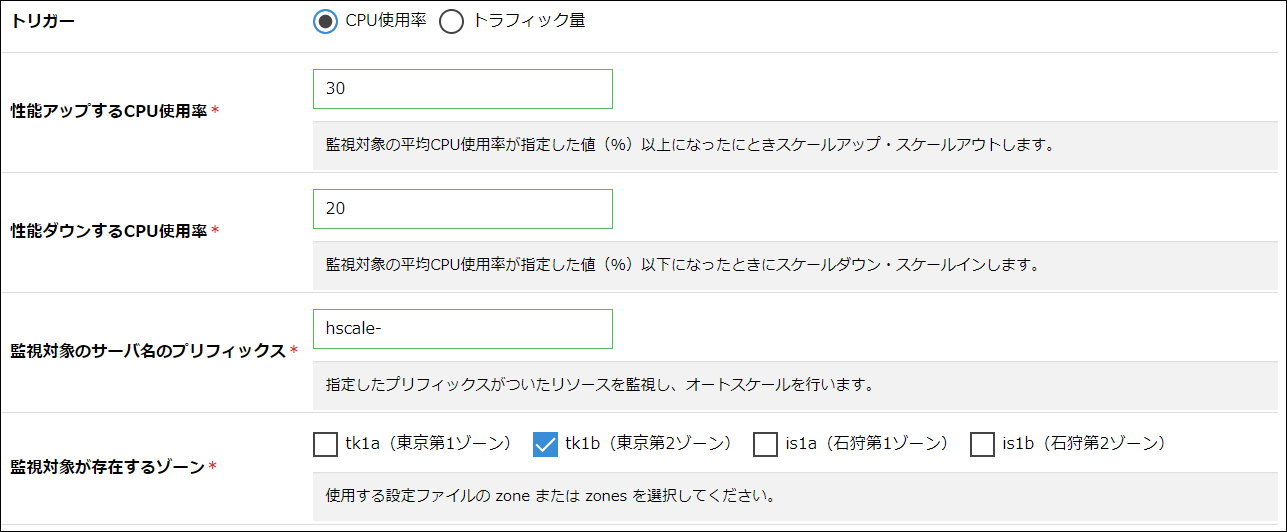
性能アップするCPU使用率 |
任意の値を入力します。 |
性能ダウンするCPU使用率 |
任意の値を入力します。 |
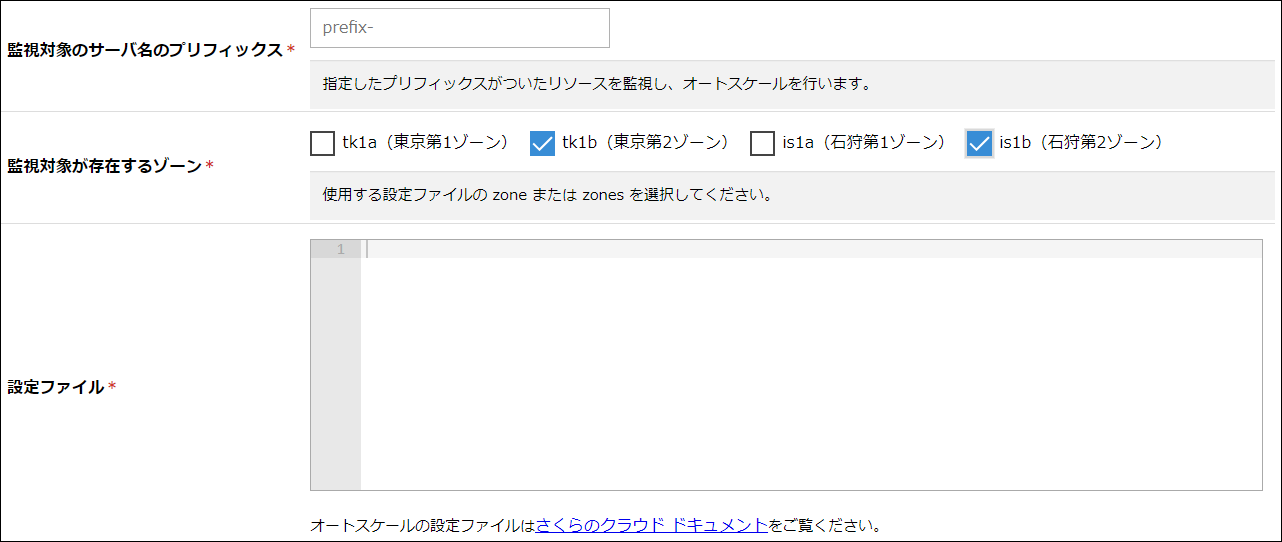
監視対象のサーバ名のプリフィックス |
オートスケールの監視対象となるサーバ名のプリフィックス(接頭辞)を入力します。 |
|---|---|
監視対象が存在するゾーン |
オートスケールの監視対象のサーバが存在するゾーンを選択します。 |
設定ファイル |
オートスケールの設定ファイルを入力します。設定例は以下をご参照ください。 |
例:スケールアップ(垂直スケール)の設定ファイル
resources:
- type: Server
selector:
names: ["vscale-group"] #サーバ名のprefix
zones: ["tk1b","is1b"] #オートスケール対象のサーバが存在するゾーン
parent:
type: ELB
selector:
names: ["autoscale-lb"] #エンハンスドLBの名前
shutdown_force: false
setup_grace_period: 90 #スケール後のバランサに戻す猶予時間
plans:
- name: smallest
core: 1
memory: 1
- name: medium
core: 3
memory: 4
- name: largest
core: 8
memory: 16
# オートスケーラーの動作設定
autoscaler:
cooldown: 300
オートスケールの設定ファイルの詳細は sacloud/autoscalerのマニュアル をご覧ください。
なお、本機能では以下の設定は利用できません。
カスタムハンドラー設定
クールダウン期間(cooldown)以外のオートスケーラーの動作設定
さくらのクラウドAPI関連の設定
startup_scripts、ssh_keys、cloud_configでの外部ファイルの参照
名前 / 説明 / タグ / アイコン |
コントロールパネル上で表示するわかりやすい名前や説明の設定、タグ・ アイコン 機能による分類が可能です。 |
|---|

各項目を入力して「追加」をクリックします。
オートスケールの動作確認
作成したサーバに別のサーバから「ApacheBench」コマンドでアクセス負荷を発生させることで、正常にオートスケールが行われるかを確認します。
コマンドの一例として以下をご参考ください。
ab -k -H 'Accept-Encoding: deflate, gzip, br' -c 3 -t 1200 http://example.com/example.html
事前準備(水平スケール)
コントロールパネルからオートスケールの設定を行う前に、APIキーやオートスケールの対象となるサーバとロードバランサの準備が必要です。
本内容では例として、プライベートネットワーク内でロードバランサアプライアンスを使ってオートスケールを行います。
この例ではCPU使用率の監視対象となるサーバを1台、オートスケールは0台から最大7台まで増えるように設定しています。
なお、CPU使用率の監視対象となるサーバはオートスケール対象外です。
以下の構成を東京第2ゾーンで作成しています。
スイッチ(ルータは必要ありません)
VPNルータ(NATのために利用します)
踏み台サーバ(グローバルネットワーク、スイッチ両方のネットワークに接続して、プライベートネットワーク内のサーバにアクセスするために使います)
プライベートネットワークは 192.168.10.0/24 を使います
VPNルータのプライベート側のIPアドレスは 192.168.0.254 とします
オートスケール機能で使用するAPIキーを作成します。
※作成方法は「 APIキー 」をご確認ください。
APIキーの種類 |
リソース操作APIキー |
|---|---|
アクセスレベル |
作成・削除 |
ロードバランサアプライアンスの作成
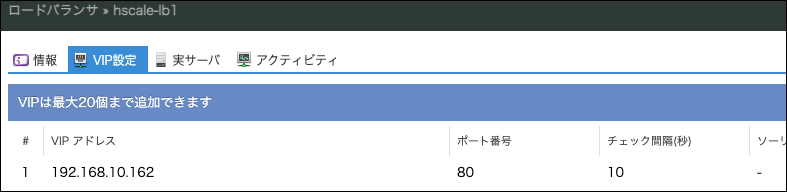
hscale-lb1 という名前で作成し、IPアドレスに 192.168.10.161 を指定します。
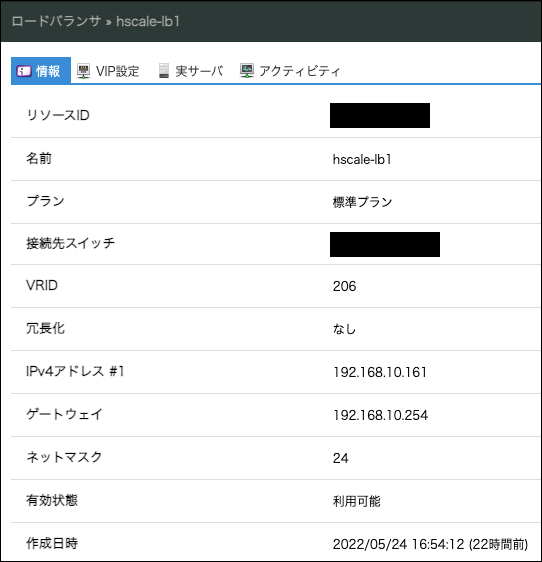
VIPとして 192.168.10.162 を登録します。
オートスケール対象外サーバの作成
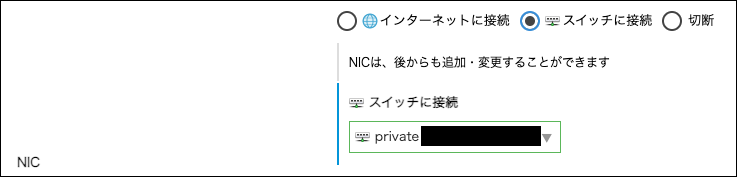
hscale-base1 という名前でサーバを作成します。この例ではOSに RockyLinux をインストールしています。
NICはスイッチに接続して、IPアドレスに 192.168.10.171 を指定します。
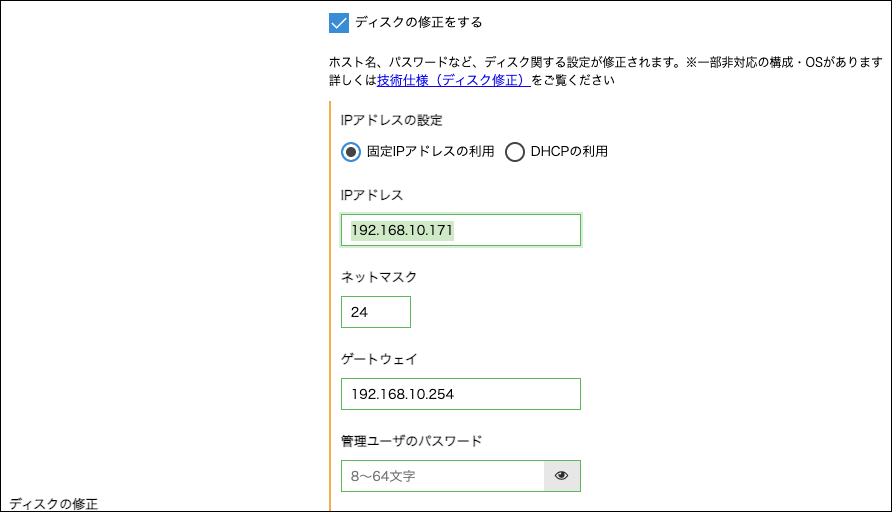
サーバにはnginxを入れて、ロードバランサアプライアンスの実サーバとして動作するようネットワーク設定をします。
192.168.10.162 はロードバランサのVIPです。
sudo yum install -y nginx
sudo systemctl enable nginx
sudo systemctl start nginx
echo "server name: $(hostname)" | sudo tee /usr/share/nginx/html/index.html
echo "OK" | sudo tee /usr/share/nginx/html/live
sudo firewall-cmd --permanent --add-service http
sudo firewall-cmd --reload
cat <<EOF | sudo tee -a /etc/sysctl.conf
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
EOF
sudo sysctl -p
sudo nmcli connection add type dummy ifname dummy0 ipv4.method manual ipv4.addresses 192.168.10.162/32 ipv6.method ignore
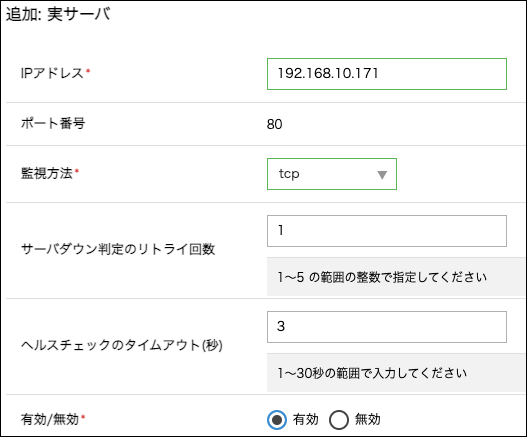
ロードバランサの実サーバとして登録
監視方法は「tcp」にして登録しています。
踏み台サーバから動作確認を行います。
$ curl 192.168.10.162
server name: hscale-base1
$ curl 192.168.10.162
server name: hscale-base1
オートスケールの設定
例:スケールアウト(水平スケール)の設定ファイル
resources:
- type: ServerGroup
name: "hscale-auto" # hscale-auto-001 というサーバが作成されます
zone: "tk1b" #ゾーンはtk1b
parent:
type: LoadBalancer
selector: "hscale-lb1" #ロードバランサアプライアンスの名前
min_size: 0 #負荷がないときは0台。baseだけになります。
max_size: 7
shutdown_force: false
plans:
- name: smallest
size: 0
- name: medium
size: 4
- name: largest
size: 7
# 台数維持機能の有効化
auto_healing:
enabled: true
template:
description: "hscale-servergroup"
interface_driver: "virtio"
plan: #サーバのプラン 1core 1GBのサーバ
core: 1
memory: 1
dedicated_cpu: false
network_interfaces:
- upstream:
id: 113301XXXXXX #スイッチのID
assign_cidr_block: "192.168.10.128/27" # 192.168.10.128 - 192.168.10.159 から割り当てられる
assign_netmask_len: 24
default_route: "192.168.10.254" #VPNルータ
expose:
ports: [80]
vips: ["192.168.10.162"] #ロードバランサのVIP
health_check:
protocol: "tcp"
disks:
- os_type: "rockylinux"
plan: "ssd"
connection: "virtio"
size: 20
edit_parameter:
disabled: false
password: ""
disable_pw_auth: true
enable_dhcp: false
change_partition_uuid: true
ssh_keys: #SSH鍵
- "ssh-rsa xxx"
- "ssh-rsa xxx"
startup_scripts: #nginxをインストールし、ロードバランサで利用できるネットワーク設定をする
- |
#!/bin/bash
yum install -y nginx
systemctl enable nginx
echo -e "keepalive_requests 10;\ngzip_proxied any;\ngzip on;\ngzip_http_version 1.0;\ngzip_comp_level 9;\ngzip_types text/html;" > /etc/nginx/conf.d/gzip.conf
systemctl start nginx
echo "server name: {{ .Name }}" > /usr/share/nginx/html/index.html
echo "OK" > /usr/share/nginx/html/live
firewall-cmd --permanent --add-service http
firewall-cmd --reload
nmcli connection add type dummy ifname dummy0 ipv4.method manual ipv4.addresses 192.168.10.162/32 ipv6.method ignore
cat <<EOF | tee -a /etc/sysctl.conf
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
EOF
sysctl -p
# オートスケーラーの動作設定
autoscaler:
cooldown: 300
対象のゾーンは tk1b で、平均CPU使用率が30%を超えるとスケールアウトするようにします。
オートスケールの動作確認
hscale-base1にて「stress」コマンドを実行し、負荷をかけるとオートスケールが実行されます。
$ yum install -y stress
$ stress -c 1
stress: info: [80781] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
今回はCPU使用率を確認する間隔である10分ごとに1台ずつ増え、3台までサーバが増えています。
May 25 15:09:23 prod1 systemd[1]: Started SakuraCloud AutoScaler Input for 113400xxxxxx.
May 25 15:09:24 prod1 cpu_threshold_scaling.sh[77142]: 2022/05/25 15:09:24 hscale-base zone:tk1b cores:1 cpu:1.020000 time:2022-05-25 15:05:00 +0900 JST
May 25 15:09:24 prod1 cpu_threshold_scaling.sh[77142]: 2022/05/25 15:09:24 hscale-base avg:102.000000
May 25 15:09:24 prod1 cpu_threshold_scaling.sh[77142]: Do Up
May 25 15:09:24 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:24+09:00 level=info request=Up message="request received"
May 25 15:09:24 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:24+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_ACCEPTED
May 25 15:09:24 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:24+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_RUNNING
May 25 15:09:24 prod1 cpu_threshold_scaling.sh[77142]: status: JOB_ACCEPTED, job-id: hscale-auto
May 25 15:09:24 prod1 systemd[1]: autoscaler_113400948155_input.service: Succeeded.
May 25 15:09:24 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:24+09:00 level=info request=Up source=default resource=hscale-auto status=ACCEPTED
May 25 15:09:24 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:24+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING
May 25 15:09:24 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:24+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=creating...
May 25 15:09:26 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:26+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="created: {ID:113400xxxxxx, Name:hscale-auto-001}"
May 25 15:09:26 prod1 autoscaler[76942]: timestamp=2022-05-25T15:09:26+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="creating disk[0]..."
May 25 15:10:36 prod1 autoscaler[76942]: timestamp=2022-05-25T15:10:36+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="created disk[0]: {ID:113400xxxxxx, Name:hscale-auto-001-disk001, ServerID:113400xxxxxx}"
May 25 15:10:36 prod1 autoscaler[76942]: timestamp=2022-05-25T15:10:36+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=starting...
May 25 15:11:09 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:09+09:00 level=info request=Up source=default resource=hscale-auto status=DONE log=started
May 25 15:11:09 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:09+09:00 level=info request=Up source=default resource=hscale-auto status=ACCEPTED
May 25 15:11:09 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:09+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING
May 25 15:11:10 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:10+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="added: Server{VIP:192.168.10.162, IP: 192.168.10.129, Port:80}"
May 25 15:11:10 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:10+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=updating...
May 25 15:11:11 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:11+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=updated
May 25 15:11:11 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:11+09:00 level=info request=Up source=default resource=hscale-auto status=DONE
May 25 15:11:11 prod1 autoscaler[76942]: timestamp=2022-05-25T15:11:11+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_DONE
May 25 15:19:33 prod1 systemd[1]: Started SakuraCloud AutoScaler Input for 113400xxxxxx.
May 25 15:19:34 prod1 cpu_threshold_scaling.sh[77173]: 2022/05/25 15:19:34 hscale-base zone:tk1b cores:1 cpu:1.020000 time:2022-05-25 15:15:00 +0900 JST
May 25 15:19:34 prod1 cpu_threshold_scaling.sh[77173]: 2022/05/25 15:19:34 hscale-base avg:102.000000
May 25 15:19:34 prod1 cpu_threshold_scaling.sh[77173]: Do Up
May 25 15:19:34 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:34+09:00 level=info request=Up message="request received"
May 25 15:19:34 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:34+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_ACCEPTED
May 25 15:19:34 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:34+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_RUNNING
May 25 15:19:34 prod1 cpu_threshold_scaling.sh[77173]: status: JOB_ACCEPTED, job-id: hscale-auto
May 25 15:19:34 prod1 systemd[1]: autoscaler_113400948155_input.service: Succeeded.
May 25 15:19:35 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:35+09:00 level=info request=Up source=default resource=hscale-auto status=ACCEPTED
May 25 15:19:35 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:35+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING
May 25 15:19:35 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:35+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=creating...
May 25 15:19:37 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:37+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="created: {ID:113400xxxxxx, Name:hscale-auto-002}"
May 25 15:19:37 prod1 autoscaler[76942]: timestamp=2022-05-25T15:19:37+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="creating disk[0]..."
May 25 15:20:27 prod1 autoscaler[76942]: timestamp=2022-05-25T15:20:27+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="created disk[0]: {ID:113400xxxxxx, Name:hscale-auto-002-disk001, ServerID:113400xxxxxx}"
May 25 15:20:27 prod1 autoscaler[76942]: timestamp=2022-05-25T15:20:27+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=starting...
May 25 15:21:00 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:00+09:00 level=info request=Up source=default resource=hscale-auto status=DONE log=started
May 25 15:21:00 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:00+09:00 level=info request=Up source=default resource=hscale-auto status=ACCEPTED
May 25 15:21:00 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:00+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING
May 25 15:21:00 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:00+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="added: Server{VIP:192.168.10.162, IP: 192.168.10.130, Port:80}"
May 25 15:21:00 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:00+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=updating...
May 25 15:21:01 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:01+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=updated
May 25 15:21:01 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:01+09:00 level=info request=Up source=default resource=hscale-auto status=DONE
May 25 15:21:01 prod1 autoscaler[76942]: timestamp=2022-05-25T15:21:01+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_DONE
May 25 15:29:43 prod1 systemd[1]: Started SakuraCloud AutoScaler Input for 113400xxxxxx.
May 25 15:29:44 prod1 cpu_threshold_scaling.sh[77206]: 2022/05/25 15:29:44 hscale-base zone:tk1b cores:1 cpu:1.020000 time:2022-05-25 15:25:00 +0900 JST
May 25 15:29:44 prod1 cpu_threshold_scaling.sh[77206]: 2022/05/25 15:29:44 hscale-base avg:102.000000
May 25 15:29:45 prod1 cpu_threshold_scaling.sh[77206]: 2022/05/25 15:29:45 hscale-auto-001 zone:tk1b cores:1 cpu:0.026667 time:2022-05-25 15:25:00 +0900 JST
May 25 15:29:45 prod1 cpu_threshold_scaling.sh[77206]: 2022/05/25 15:29:45 hscale-auto-001 avg:2.666667
May 25 15:29:45 prod1 cpu_threshold_scaling.sh[77206]: Do Up
May 25 15:29:45 prod1 autoscaler[76942]: timestamp=2022-05-25T15:29:45+09:00 level=info request=Up message="request received"
May 25 15:29:45 prod1 autoscaler[76942]: timestamp=2022-05-25T15:29:45+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_ACCEPTED
May 25 15:29:45 prod1 autoscaler[76942]: timestamp=2022-05-25T15:29:45+09:00 level=info request=Up source=default resource=hscale-auto status=JOB_RUNNING
May 25 15:29:45 prod1 cpu_threshold_scaling.sh[77206]: status: JOB_ACCEPTED, job-id: hscale-auto
May 25 15:29:45 prod1 systemd[1]: autoscaler_113400948155_input.service: Succeeded.
May 25 15:29:46 prod1 autoscaler[76942]: timestamp=2022-05-25T15:29:46+09:00 level=info request=Up source=default resource=hscale-auto status=ACCEPTED
May 25 15:29:46 prod1 autoscaler[76942]: timestamp=2022-05-25T15:29:46+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING
May 25 15:29:46 prod1 autoscaler[76942]: timestamp=2022-05-25T15:29:46+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log=creating...
May 25 15:29:48 prod1 autoscaler[76942]: timestamp=2022-05-25T15:29:48+09:00 level=info request=Up source=default resource=hscale-auto status=RUNNING log="created: {ID:113400xxxxxx, Name:hscale-auto-003}"
ロードバランサからのアクセスもそれぞれのサーバに振られています。
$ curl 192.168.10.162
server name: hscale-auto-004
$ curl 192.168.10.162
server name: hscale-auto-003
$ curl 192.168.10.162
server name: hscale-auto-002
$ curl 192.168.10.162
server name: hscale-auto-001
$ curl 192.168.10.162
server name: hscale-base
$ curl 192.168.10.162
server name: hscale-auto-004
$ curl 192.168.10.162
server name: hscale-auto-003
$ curl 192.168.10.162
server name: hscale-auto-002
$ curl 192.168.10.162
server name: hscale-auto-001
$ curl 192.168.10.162
server name: hscale-base
$ curl 192.168.10.162
server name: hscale-auto-004
$ curl 192.168.10.162
server name: hscale-auto-003
$ curl 192.168.10.162
server name: hscale-auto-002
$ curl 192.168.10.162
server name: hscale-auto-001
「stress」コマンドを停止すると、段階的に hscale-auto-* のサーバは削除されていきます。
水平スケールでの台数維持機能
台数維持機能の概要
水平スケール対象のサーバに対し、定期的にヘルスチェックを実施します。ヘルスチェックで NG と判定されたサーバは自動的に削除され、新しいサーバに置き換えられます。
これにより、一定の台数が常に維持され、障害時でも安定したサービス提供が可能となります。特定のサーバ障害が発生しても、手動復旧に頼らず自動的に置き換えたい場合に有効な機能です。
なお、動作の詳細については以下のドキュメントをご参照ください: https://docs.usacloud.jp/autoscaler/tips/auto_healing/
設定方法
台数維持機能は、オートスケールの 設定ファイル に記載することで有効化できます。
resources:
- type: ServerGroup
# (中略)
# 台数維持機能の有効化
auto_healing:
enabled: true
チェック間隔は固定で 10 分です。
判定基準は、基本的にサーバのステータスが「起動」であるかどうかです。
上流にロードバランサ、またはエンハンスドロードバランサを設置している場合は、それらのヘルスチェック結果も参照されます。
注意事項
短時間のレスポンス遅延などで誤検知が発生する可能性があります。 ロードバランサ、またはエンハンスドロードバランサ連携を利用する構成では、アプリケーションの特性に応じてヘルスチェック設定を適切に行なってください。
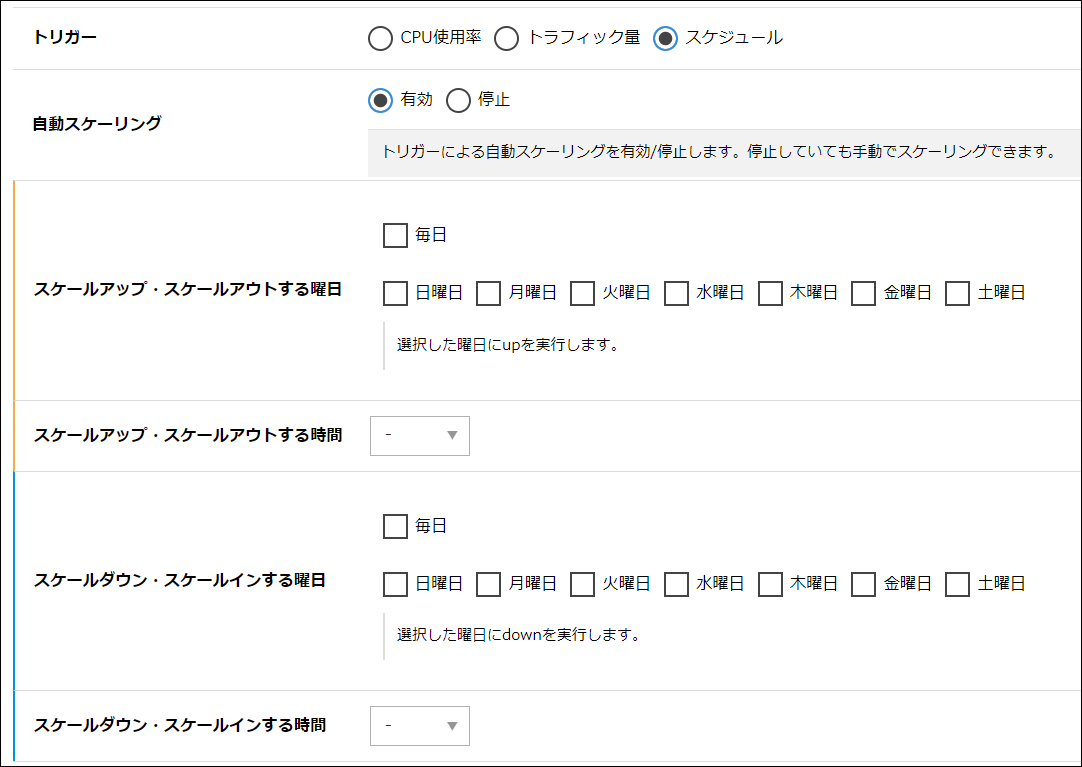
オートスケールのスケジュール機能
オートスケールの実行を任意の時間帯で動作するように登録が可能です。
サーバ等の負荷が高くなる時間帯にあらかじめ「スケールアップ・スケールアウト」しておき、負荷が下がる時間帯には「スケールダウン・スケールイン」するといった運用の際にご利用ください。
モニタリングスイートのアラートとの連携
オートスケールでは、CPU-TIME やトラフィック量といった基本的なメトリクスに加えて、モニタリングスイートで発生したアラートを起点としてスケール動作を起動できます。
これにより、モニタリングスイートで設定したアラートルールに基づいて、スケール動作の起動を自動化することが可能になります。
モニタリングスイートのアラートと連携することで、以下のような柔軟なスケール制御が行えます。
各種のホストメトリクス(CPU 使用率、メモリ使用量、ディスク I/O、ネットワーク帯域など)に基づくスケール
アプリケーション固有のサービスメトリクス(例:キューの滞留数、レスポンスタイム、エラー率 など)をトリガーとしたスケール
カスタムメトリクス(外形監視や独自エクスポータから取得した値)に応じたスケール
この仕組みにより、システム負荷やアプリケーション状態に応じたより細かなスケール戦略が実現でき、リソースの最適化やサービス品質の向上に寄与します。
必要な作業
モニタリングスイートのアラートを利用してスケール動作を行うには、以下の設定が必要です。
1.オートスケールの作成
2.EventBus の設定
・「実行設定」の作成(オートスケールのスケール動作の起動)
・「トリガー」の作成(モニタリングスイートのアラート通知の受け取り〜処理の起動)
3.モニタリングスイートでの設定
・「アラートプロジェクト」の作成
・「アラートルール」の作成(しきい値の設定)
・「通知先」の設定(EventBusへ通知)
・「通知ルーティング」の設定(アラートルールと通知先のマッピング)
各項目の具体的な設定方法は、後述の「設定例」にて実際の画面構成・パラメータを交えて説明します。
設定例
以下では、モニタリングスイートのアラート通知をトリガーとして、オートスケールでサーバのスケールアウトを実行する設定例を示します。
注意
EventBus の実行設定/トリガーは、1つの組み合わせにつき1種類のスケール動作(スケールアップ/アウトまたはスケールダウン/イン)を実行します。
そのため、スケールアップ/アウトとスケールダウン/インの両方をアラートで制御したい場合は、実行設定とトリガーをそれぞれ別途作成し、アラートからの通知を振り分けることで2系統(スケールアウト用/スケールイン用)として構成する必要があります。
事前準備
オートスケールとEventBus向けにAPIキーが必要になるため、あらかじめ作成してください。
APIキーの作成方法は APIキー をご覧ください。
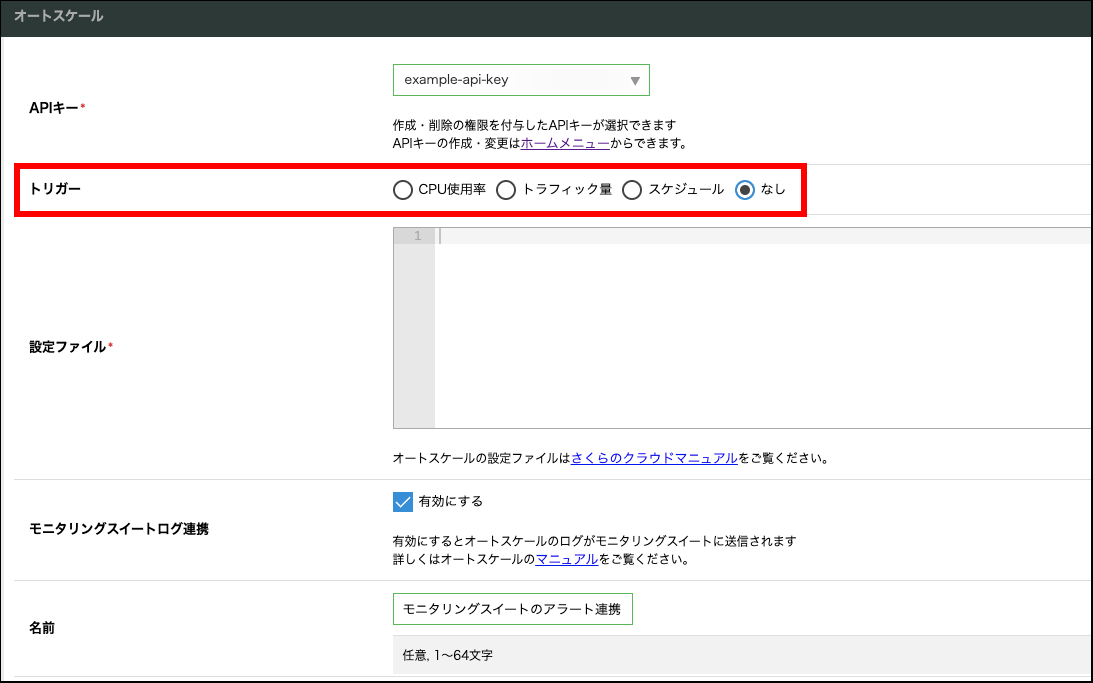
オートスケールの作成
オートスケールを作成します。この時にトリガーを「なし」にすることで、モニタリングスイートのアラート以外を契機としたスケール動作の実行を避けることができます。
EventBusの設定
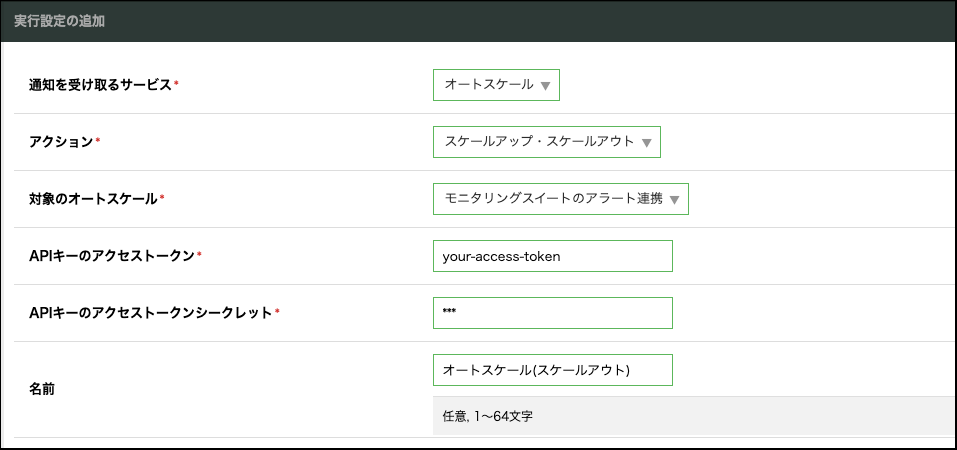
実行設定の作成
EventBusでスケール動作を実行するための「実行設定」を作成します。各項目は以下のように登録します。
通知を受け取るサービス |
オートスケール |
アクション |
スケールアップ・スケールアウト |
対象のオートスケール |
前項で作成したオートスケールを選択 |
APIキーのアクセストークン |
作成しておいたAPIキーのアクセストークン |
APIキーのアクセストークンシークレット |
作成しておいたAPIキーのアクセストークンシークレット |
トリガーの作成
次にトリガーを作成します。各項目は以下のように登録します。
実行設定 |
前項で作成した実行設定を選択 |
ソース |
//eventbus.sakura.ad.jp/monitoringsuite/alert |
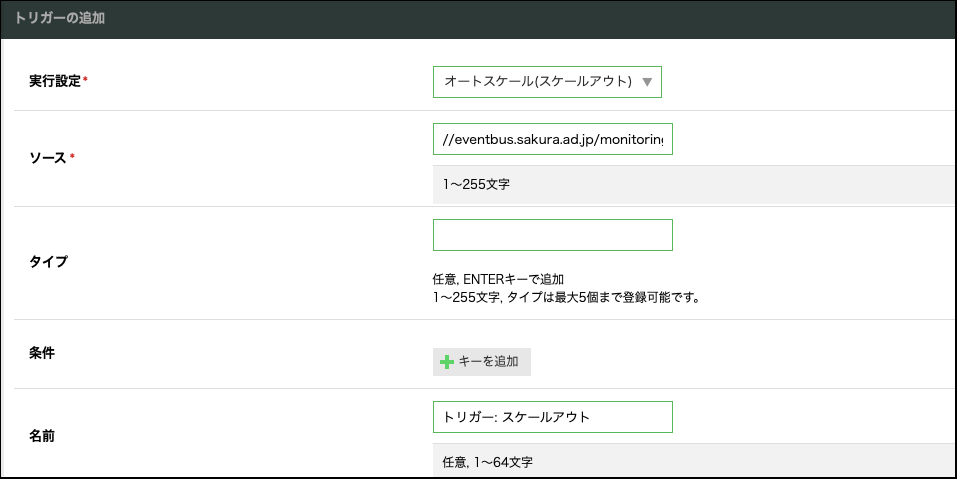
ヒント
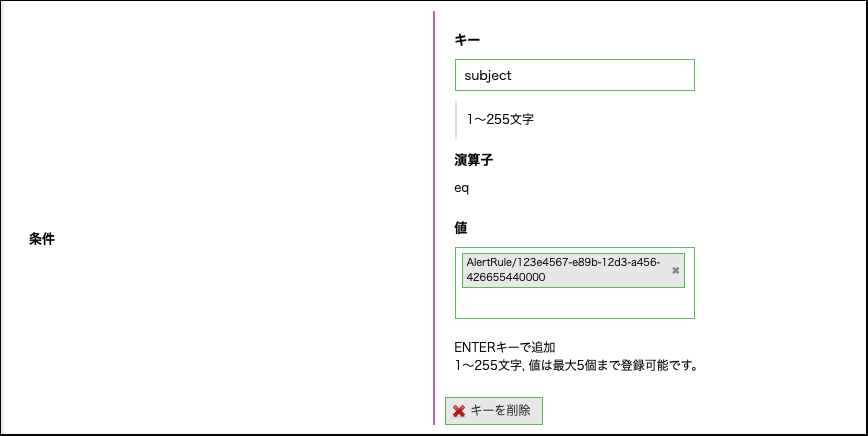
特定のアラートルールからの通知にのみ反応させたい場合は、「条件」欄にキーを追加し以下の設定を行います。
キー |
subject |
値 |
AlertRule/{アラートルールのID} |
モニタリングスイートのアラート設定
アラートプロジェクトの作成
モニタリングスイートのマニュアル を参考にアラートプロジェクトを作成します。
アラートルールの作成
モニタリングスイートのマニュアル を参考にアラートルールを作成します。
通知先の設定と通知ルーティングの追加
モニタリングスイートのマニュアル を参考にアラートプロジェクトの通知先を設定し、通知ルーティングを作成します。
まず、通知先の設定でEventBusに対して通知するように設定してください。

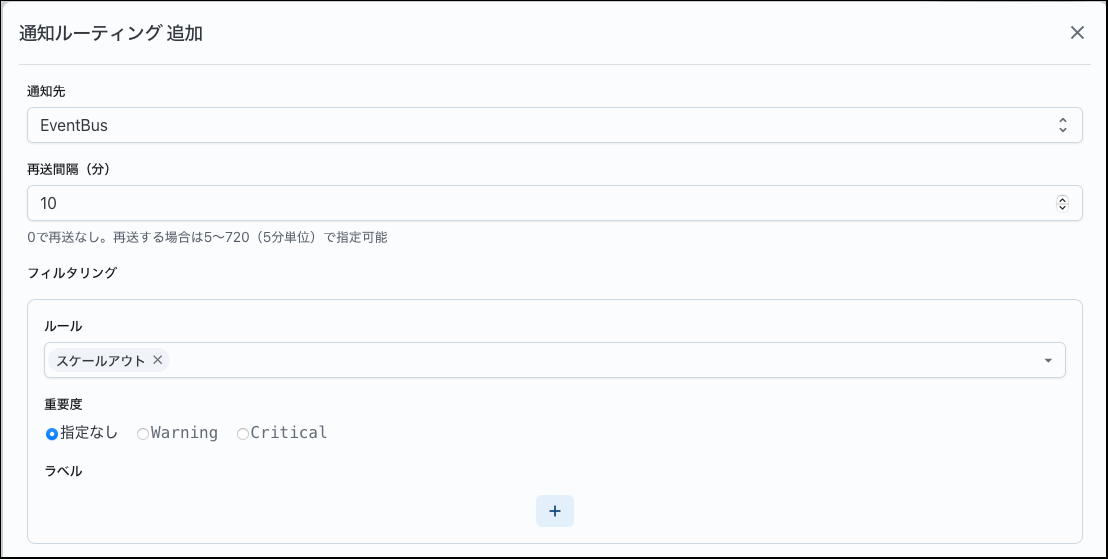
次に通知ルーティングを追加します。各項目は以下のように設定します。
通知先 |
EventBus |
再送間隔 |
任意 |
フィルタリング |
作成したアラートルールを指定 |
ここまでの設定により、モニタリングスイートのアラートを利用したスケール動作が実施可能になります。
実際の運用環境ではアラート条件やオートスケール側でのクールダウン時間などを調整し、安定したスケール動作となるよう適宜チューニングすることを推奨します。
オートスケールの停止方法
選択したトリガーによるオートスケールの実行を停止することが可能です。
自動スケーリングを一時的に停止したい場合や、APIのみ利用してオートスケールを実行したい場合には「停止」を選択します。
オートスケール作成時の設定場所

オートスケール作成後の設定場所

モニタリングスイート連携
注意
オートスケール機能のバックエンドは複数台構成で運用されており、メンテナンス等により予告なくサーバの切り替えが発生する場合があります。
この切り替えの影響により、コントロールパネル上での表示に限らず、コントロールパネルからのログダウンロードや API 経由での参照を含め、直近のログが参照できなくなる場合があります。
ログを継続的に保存・参照したい場合は、モニタリングスイート連携を有効化し、モニタリングスイート側へログを保存する構成をご利用ください。
モニタリングスイートとの連携により、オートスケールのログ取得が可能です。ログはモニタリングスイートのコントロールパネル・ダッシュボードで表示されます。実際に利用する場合は、オートスケールでの設定に加え、モニタリングスイート側での設定も必要です。
詳しくは モニタリングスイート の設定をご確認ください。
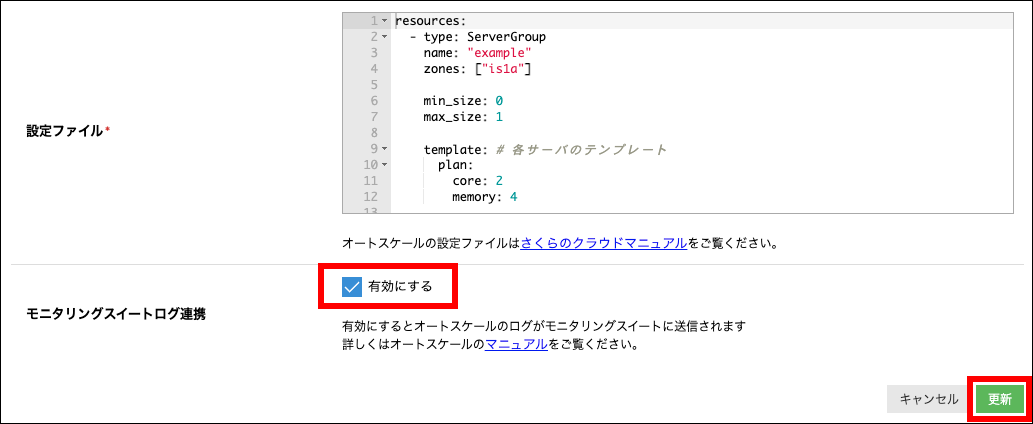
モニタリングスイートログ連携設定
モニタリングスイートへのログの連携を有効化にするには、「オートスケールの設定の変更」をクリックし、「有効にする」にチェックを入れて「更新」ボタンをクリックします。
APIによるオートスケールの実行
さくらのクラウドのAPIを利用することで、任意のタイミングでオートスケールの「スケールアップ・スケールアウト」や「スケールダウン・スケールイン」の実行が可能です。
【関連リンク】
さくらのクラウド API
さくらのクラウド API ドキュメント
APIを呼び出すシェルスクリプト
以下はAPIを呼び出すシェルスクリプトの例です。
「manual_scale.sh」という名前でファイルを作成します。
※SACLOUD_ACCESS_TOKEN / SACLOUD_ACCESS_TOKEN_SECRET / RESOURCE_ID はお客様のご利用する値に置き換えてください。
#!/bin/bash
set -e
SACLOUD_ACCESS_TOKEN="xx"
SACLOUD_ACCESS_TOKEN_SECRET="xxx"
RESOURCE_ID=1234567890
SCALE_MODE="$1"
if [ -z $SCALE_MODE ]; then
echo "usage: $0 up/down"
exit 1
fi
if [ $SCALE_MODE = "up" ]; then
curl -o /dev/null --fail -sS -XPUT -H "Content-Type: application/json" -d '{}' \
--user "${SACLOUD_ACCESS_TOKEN}:${SACLOUD_ACCESS_TOKEN_SECRET}" \
https://secure.sakura.ad.jp/cloud/zone/is1a/api/cloud/1.1/commonserviceitem/${RESOURCE_ID}/autoscale/up
elif [ $SCALE_MODE = "down" ]; then
curl -o /dev/null --fail -sS -XPUT -H "Content-Type: application/json" -d '{}' \
--user "${SACLOUD_ACCESS_TOKEN}:${SACLOUD_ACCESS_TOKEN_SECRET}" \
https://secure.sakura.ad.jp/cloud/zone/is1a/api/cloud/1.1/commonserviceitem/${RESOURCE_ID}/autoscale/down
fi
exit 0
作成したファイルを保存して、実行権限を付与します。
$ chmod +x manual_scale.sh
シェルスクリプトの実行方法
「up」または「down」の引数を付けて実行します。
$ sh ./manual_scale.sh up
オートスケールが正常に実行されているか、コントロールパネルのログからご確認ください。
APIの活用例
サーバへの負荷が増える時間帯にスケールアップ、またはスケールアウトし、負荷が落ち着く頃に元に戻すといった使い方も可能です。
以下の例では21時10分にスケールアップ(アウト)を実行し、翌日の1時40分にスケールダウン(イン)を実行しています。
APIを定期的に呼び出すことで、負荷の大きくなる時間のみサーバの処理能力を上昇してご利用いただけます。
前述のシェルスクリプト「manual_scale.sh」を定期実行するためのサーバを用意し、crontab に以下のように設定します。
crontab の編集
$ crontab -e
crontab に設定する内容の例
10 21 * * * /home/example/scripts/manual_scale.sh up
40 1 * * * /home/example/scripts/manual_scale.sh down
特定のオートスケール状態への変更
APIを利用することで、オートスケールの設定に記した特定の状態(plans)を指定して、オートスケールの操作を行えます。
状態(plans)の設定例
resources:
- type: Server
selector:
names: ["vscale-group"]
zones: ["tk1b"]
plans:
- name: smallest
core: 1
memory: 1
- name: medium
core: 3
memory: 4
- name: largest
core: 8
memory: 16
largest を指定してオートスケールを実行にするには、以下のようにリクエストの JSON に「DesiredStateName」を指定します。
SACLOUD_ACCESS_TOKEN="xx"
SACLOUD_ACCESS_TOKEN_SECRET="xxx"
RESOURCE_ID=1234567890
echo '{"DesiredStateName":"largest"}' | curl -o /dev/null --fail -sS \
-XPUT -H 'Content-Type: application/json' -d @- \
--user "${SACLOUD_ACCESS_TOKEN}:${SACLOUD_ACCESS_TOKEN_SECRET}" \
https://secure.sakura.ad.jp/cloud/zone/is1a/api/cloud/1.1/commonserviceitem/${RESOURCE_ID}/autoscale/up
オートスケールが動作するトリガーについて
動作のトリガーには アクティビティグラフ の情報を利用しています。
サーバの負荷 |
CPU時間(CPU TIME) |
|---|---|
ルータ+スイッチのトラフィック量 |
ルータ+スイッチのアクティビティ |
監視間隔 |
10分毎 |
|---|
注意
ルータ+スイッチのスケールアップにおいて任意のプランを設定していない場合、トラフィック量に合わせて1段階ずつ上位プランへスケールアップを繰り返し実行します。
また、トラフィック量が0の場合はスケールダウンが行われません。
オートスケール設定の定期的な検証/不正時の動作停止について
オートスケールでは登録/更新時にオートスケール設定を検証していますが、登録/更新後に設定が不正な状態になる場合がございます。
例:
サーバの垂直スケール対象として設定したサーバの名前を変更した
コピー元ディスクとして指定した条件で検索すると複数のディスクがヒットするようになった
オートスケールは検証で正常性が確認できなくなると動作を継続できない状態となり動作を停止します。
このため、オートスケールは定期的に設定を検証し、正常な動作ができる状態であるか確認しています。
設定が不正な状態となっていることを検知すると緊急連絡用メールアドレスに設定されたメールアドレス(未設定の場合は会員IDの登録メールアドレス)宛に、以下のような文面でメール通知されます。
From: さくらのクラウド オートスケール <noreply@sakura.ad.jp>
Subject: 【さくらインターネット】オートスケール停止のお知らせ
※ このメッセージは自動送信されています。
さくらのクラウド オートスケール サービスです。
下記のご契約につきまして不正な状態になっていることを検知したためサービスを停止いたしました。
クラウドアカウント名:example
リソース名:example
リソースID:123456789012
お客様にてログ/ステータスのご確認をお願いいたします。
さくらのクラウドマニュアル - オートスケール
https://manual.sakura.ad.jp/cloud/autoscale/index.html
※本メールは自動送信用メールアドレスから送信しているため、そのまま返信しても弊社よりご連絡できません。