NoSQL
[更新: 2025年12月15日]
概要
「NoSQL」は、Apache Cassandra 互換のマネージドデータベースサービスで、パフォーマンスを犠牲にすることなくスケーラビリティと高可用性を実現します。
GUIおよびコマンドラインの両方を使用して、NoSQLサービスをいつでも利用できます。
仕様
機能説明
ユーザは、NoSQLで管理するデータベースを作成、参照、変更、削除できます。
ユーザは、作成したデータベースを自由に起動および停止できます。
ユーザは、画面、API、CLIを使用して、新規にCassandraインスタンスを作成できます。
システム管理者が指定する独立した閉じたネットワーク内で、プライベートネットワークとして利用できます。
ネットワークレベルおよびユーザ権限レベルでアクセス制御が可能です。
注意事項
ご利用いただく前に、以下の点にご注意ください。
提供ゾーンは東京第2ゾーンのみです。接続するスイッチは、同じゾーン内に作成する必要があります。
バックアップに使用する NFSアプライアンス の費用は、別途発生します。
想定される利用シーン
例1: 高トラフィックWebサービス
SNSや動画配信の大量アクセスに対応できるスケーラブルで耐障害性の高いデータストアとして利用します。
例2: IoTの時系列データ管理
センサーデータをリアルタイムで蓄積・分析し、渋滞予測や最適化に活用します。
料金
NoSQLサービスの利用料金については、 料金表 をご参照ください。
提供プラン
プラン名 |
スペック |
ディスクサイズ |
ストレージ |
ノード数 |
ノード追加上限数 |
|---|---|---|---|---|---|
40GBプラン |
2コア4GBメモリ |
40 GB |
SSD |
1 |
追加不可 |
100GBプラン |
3コア8GBメモリ |
100 GB |
SSD |
3 |
2台 × 3回 |
250GBプラン |
6コア16GBメモリ |
250 GB |
SSD |
3 |
2台 × 3回 |
バックアップについて
NoSQLのバックアップは、管理画面から設定および実行することができます。
バックアップ方法には「自動バックアップ」と「随時バックアップ」の2種類があり、それぞれについて解説します。
前提条件
バックアップ先は、さくらのクラウド上でユーザ自身が作成したNFSサーバに限定されるため、事前にNFSサーバを作成しておく必要があります。
さくらのクラウドマニュアル: NFSアプライアンス
自動バックアップ
データベース作成後、または自動バックアップの設定変更後、指定されたタイミングで自動的にバックアップが取得されます。
設定手順
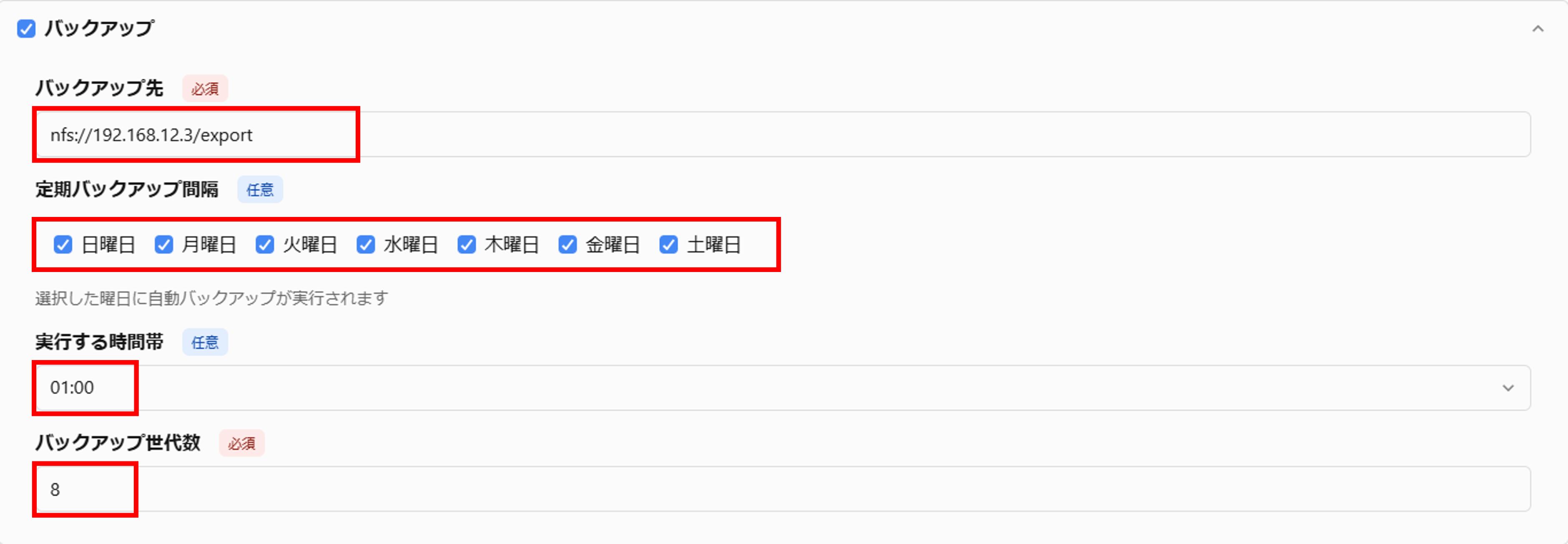
データベースの初回作成時または設定変更時に、「バックアップ先」「定期バックアップ間隔」「実行する時間帯」「バックアップ世代数」に適切な値を入力し、設定を保存します。 設定を保存すると、自動バックアップの設定が有効になり、運用が開始されます。
随時バックアップ
データベース作成後は、いつでも自由にバックアップを取得できます。
自動バックアップを設定中に随時バックアップを実行しても自動バックアップには影響しません。
バックアップ機能の詳細については バックアップ の項目をご参照ください。
設定手順
データベース初回作成時、もしくは設定変更時、「バックアップ先」および「バックアップ世代数」に適切な値を入力して設定を保存します。
尚、「バックアップ先」が設定済みであれば、随時バックアップも実行することができます。
世代管理
リソースごとに、「バックアップ世代数」に設定した上限までバックアップを保管できます(最大8世代まで)。
「バックアップ世代数」を超えて新たにバックアップを取得した場合、最も古いバックアップから順に自動で削除されます。
随時バックアップ(手動で取得したバックアップ)は自動で削除されることはありません。不要になった場合は手動で削除してください。
リペアについて
リペアとは、複数のサーバ間で発生したデータのずれを検出・修復し、データの整合性(一貫性)を維持するためのメンテナンス作業です。
Cassandraは高可用性を実現しており、ノード障害が発生してもシステムの稼働を継続します。
しかし、障害が発生しているノードへの書き込みは完全には保証されないため、データの不整合が発生する可能性があります。
そのため、将来的なデータ欠損を防ぎ、データの整合性を保つため、定期的にリペア処理を実施することが推奨されます。
リペアの種類
リペアには「増分リペア」と「完全リペア」の2種類があり、それぞれについて解説します。
増分リペア
増分リペアは、前回のリペア実行以降に更新されたデータのみを対象に修復を行う方法です。
このため、修復対象が限定され、処理にかかる時間やシステムへの負荷を抑えつつ効率的にデータ整合性を維持できます。
ただし、一度修復済みとマークされたデータは再度修復されないため、ディスク障害やオペレータのミス、Cassandraのバグなどによるデータ損失には対応できません。
完全リペア
完全リペアは、クラスタ内のすべてのデータを対象に修復を行います。
これにより、増分リペアでは見逃される可能性のある不整合も検出・修復でき、ディスク障害や人為的ミス、ソフトウェアのバグに起因するデータ損失のリスクを軽減します。
ただし、全データを対象とするため、増分リペアに比べて処理時間やI/O負荷が大きくなる点に注意が必要です。
リペアの実行コマンド
対象
実行コマンド
増分リペア
nodetool repair -pr
完全リペア
nodetool repair --full -pr
※-prオプションは各ノードのPrimary Rangeのみをリペアし、重複作業を避けて効率的に処理時間を短縮します。
リペア方法
NoSQLのリペアは、管理画面から設定および実行することができます。
リペア方法には「定期リペア」と「即時リペア」の2種類があり、それぞれについて解説します。
注釈
40GBプランではノード数が1のため、リペア機能をご利用いただけません。
定期リペア
データベース作成後、または定期リペアの設定変更後、指定されたタイミングで自動的にリペアが実行されます。
1.設定手順
データベースの初回作成時または設定変更時に、以下の設定項目に適切な値を入力し、設定を保存します。
設定を保存すると、定期リペアの設定が有効になり、運用が開始されます。
対象
設定項目
増分リペア
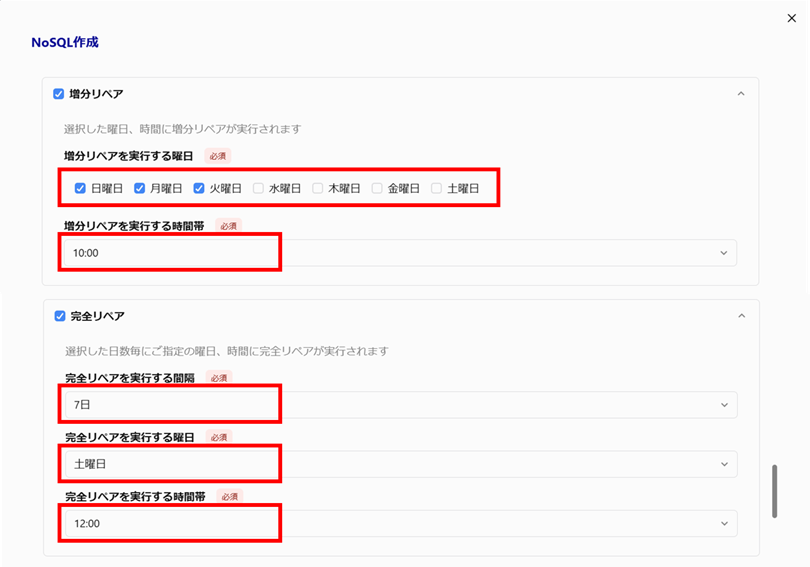
・増分リペアを実行する曜日
・増分リペアを実行する時間帯完全リペア
・完全リペアを実行する間隔
・完全リペアを実行する曜日
・完全リペアを実行する時間帯
※いずれか一方の設定(増分リペアまたは完全リペア)を入力して保存すれば、定期リペア機能は有効になります。両方を設定した場合は、それぞれのスケジュールに従ってリペアが実行されます。
2.リペアの実施間隔推奨値
項目
推奨値
増分リペア
1~3日に1回
完全リペア(増分リペアを実施している場合)
1~3週間に1回
完全リペア(増分リペアを実施しない場合)
7日に1回
※「完全リペア(増分リペアを実施しない場合)」は、Cassandra の GC 猶予期間内にリペアを実行する必要があるための最低限の基準です。
CassandraのGC 猶予期間(デフォルト 10日)は、削除済みデータの 削除マーカー(tombstone)が保持される期間です。
この期間を過ぎてリペアを行うと、削除データが他ノードで復元される可能性があります。
理論上は「10日以内」にリペアを行えば 問題ありませんが、障害やメンテナンス遅延に備え、本サービスでは、7日に1回を最低限の実施間隔として定めています。
即時リペア
データベース作成後は、起動中であれば任意のタイミングでリペアを実行できます。
停止中はリペアを実行できないため、実行する際はデータベースを起動してください。
即時リペアは突発的な不整合対応や定期リペアの補完として適宜実行いただけます。
実行方法の詳細については、即時リペアの実行 の手順をご確認ください。
ディスク暗号化機能について
本機能はストレージ側で提供されているディスク暗号化機能を、NoSQLで新規作成するディスクに適用できる機能です。
詳細は ディスク暗号化機能 マニュアルをご参照ください。
利用方法
データベースの初回作成時に表示されるフォームの「暗号化」のチェックボックスを有効にし、
「使用するKMSキー」を選択して作成します。

注釈
ディスクの暗号化を行う際には、事前に KMSキー の作成が必要となります。
詳細は KMS(Key Management Service) をご参照ください。
作成後はデータベースの詳細画面(情報タブ)でディスク暗号化の有効状態が確認できます。

バージョンアップについて
Cassandra バージョンの提供・サポートポリシー
提供バージョン対象
当社では、以下の基準に基づき、Cassandra の提供・サポートを行います。
提供対象
Cassandra 4系のみを対象とし、最新から3世代分のマイナーバージョンをサポートします。
マイナーバージョン: Apache Cassandra の正式リリースから 1〜2か月を目安に、当社で動作確認後に提供開始します。
パッチバージョン: リリースから 14日〜1か月を目安に、当社で動作確認後に提供開始します。
- ※バージョン表記について
Cassandraのバージョンは「メジャー.マイナー.パッチ」の形式で表記されます。
例: 4.1.9の場合
メジャーバージョン: 4
マイナーバージョン: 1
パッチバージョン: 9
提供対象外
以下のバージョンは提供・サポート対象外です。
当社で動作確認を行っていないバージョン
コミュニティでサポート終了(EoL)となったバージョン
※Cassandra 5 系については今後の対応を検討中です。
バージョンアップ方針
マイナーバージョンアップ
当社が動作確認済みのバージョンのみ選択可能です。
サポート対象外(EoL など)のバージョンは選択できません。
マイナーバージョンをスキップしたアップデート(例:4.1.7 → 4.5.6)はできません。
段階的なアップデートが必要です。
パッチバージョンアップ
任意のパッチバージョンを指定することはできません。
アップデート時には、利用可能な最新パッチバージョンのみ選択可能です。
メジャーバージョンアップ
メジャーバージョン(例:4.1.x → 5.0.0)へのアップグレードは現時点では対象外です。
注意事項
サポートが終了したバージョンは、アップデート候補として表示されず、選択できません。
当社から強制的なアップデートは行いませんが、脆弱性対応等の必要がある場合は個別にご案内します。
新規データベース作成時のバージョン
サポート対象の最新バージョンが自動適用されます。
旧バージョンをご希望の場合は、個別にご相談ください。
サポート
ご不明点やお困りの際は、 会員メニュー内のメールサポート より、サービス情報を「さくらのクラウド」としてお問い合わせください。
利用手順
利用開始ガイド
前提条件
以下の準備が完了していることが前提となります。
さくらのクラウド ご利用開始手順 が完了していること。
管理画面への遷移
クラウドコントロールパネルのホーム画面より「NoSQL」をクリックし、NoSQL管理画面に遷移します。

管理画面の利用方法
新規作成
本サービスの管理画面(NoSQL 一覧画面)右上の「DB作成」ボタンをクリックします。
NoSQL作成ダイアログが表示されるので、必要な情報を入力します。
入力が完了したら、画面下部の「作成」ボタンをクリックします。
確認メッセージが表示されるので、「作成」ボタンをクリックすると、作成処理が開始されます。
項目 |
設定値 |
|---|---|
データベースエンジン(必須) |
Cassandra |
データベースバージョン(必須) |
4 (固定)※今後、設定値が変更される場合があります。 |
プラン(必須) |
利用したいプランを選択します。 |
使用するKMSキー |
任意の設定値(別途作成) |
デフォルトユーザ名(必須) |
任意のユーザ名 |
パスワード(必須) |
任意のパスワード |
接続先スイッチ(必須) |
ユーザ環境とサービス環境間を接続するスイッチ |
ポート番号(必須) |
Cassandra で使用するポート番号 |
IPv4 アドレス(必須) |
Cassandra データベースの IP アドレス |
予備IP |
Cassandra データベースでデッドノードが発生した場合に |
ネットマスク(必須) |
任意の設定値 |
ゲートウェイ(必須) |
任意の設定値 |
送信元ネットワーク |
任意の設定値 |
バックアップ先 |
さくらのクラウド上に作成した NFS サーバをバックアップ先として利用可能です |
定期バックアップ間隔 |
任意の設定値(日曜日~土曜日) |
実行する時間帯 |
任意の設定値(15 分単位) |
バックアップ世代数 |
1 ~ 8 世代まで指定可能 |
増分リペアを実行する曜日 |
任意の設定値(日曜日~土曜日) |
増分リペアを実行する時間帯 |
任意の設定値(15 分単位) |
完全リペアを実行する間隔 |
任意の設定値(7日、14日、21日、28日) |
完全リペアを実行する曜日 |
任意の設定値(日曜日~土曜日) |
完全リペアを実行する時間帯 |
任意の設定値(15 分単位) |
名前(必須) |
任意の Cassandra データベース名 |
説明 |
任意の設定値 |
タグ |
任意の設定値 |
注釈
40GBプランの場合はノード数が1のため、予備IPおよびリペアの設定項目は表示されません。
一覧画面に作成したデータベースが表示されるので、有効状態が「利用可能」、かつ起動状態が「起動」になったら利用開始できます。
注釈
作成時の環境の状況にもよりますが、作成にはおよそ 10 ~ 15 分前後掛かります。
定期的に画面左上の更新ボタンをクリックして最新の状態をご確認ください。
有効状態
状態 |
説明 |
|---|---|
利用可能 |
データベースを利用できます。 |
利用不可 |
データベースは利用できません。 |
起動状態
状態 |
説明 |
|---|---|
準備中 |
システム処理中です。しばらくお待ちください。 |
起動 |
Cassandra サーバが起動中です。 |
停止 |
Cassandra サーバは停止中です。 |
エラー |
何らかの理由でシステム側でエラーとなっています。 |
詳細画面
一覧画面でデータベースの「名前」のリンクをクリック、もしくは明細をダブルクリックすることで、詳細画面に遷移し、選択したデータベースの詳細を確認することができます。
「情報」タブ
データベースの情報が確認できます。
右上の「編集」ボタンをクリックすることで各情報を編集することができます。
編集が終わったら「更新」ボタンをクリックします。
確認メッセージが表示されるので、「更新」ボタンをクリックすると、更新処理が開始されます。

「バックアップ」タブ
バックアップの一覧が確認できます。
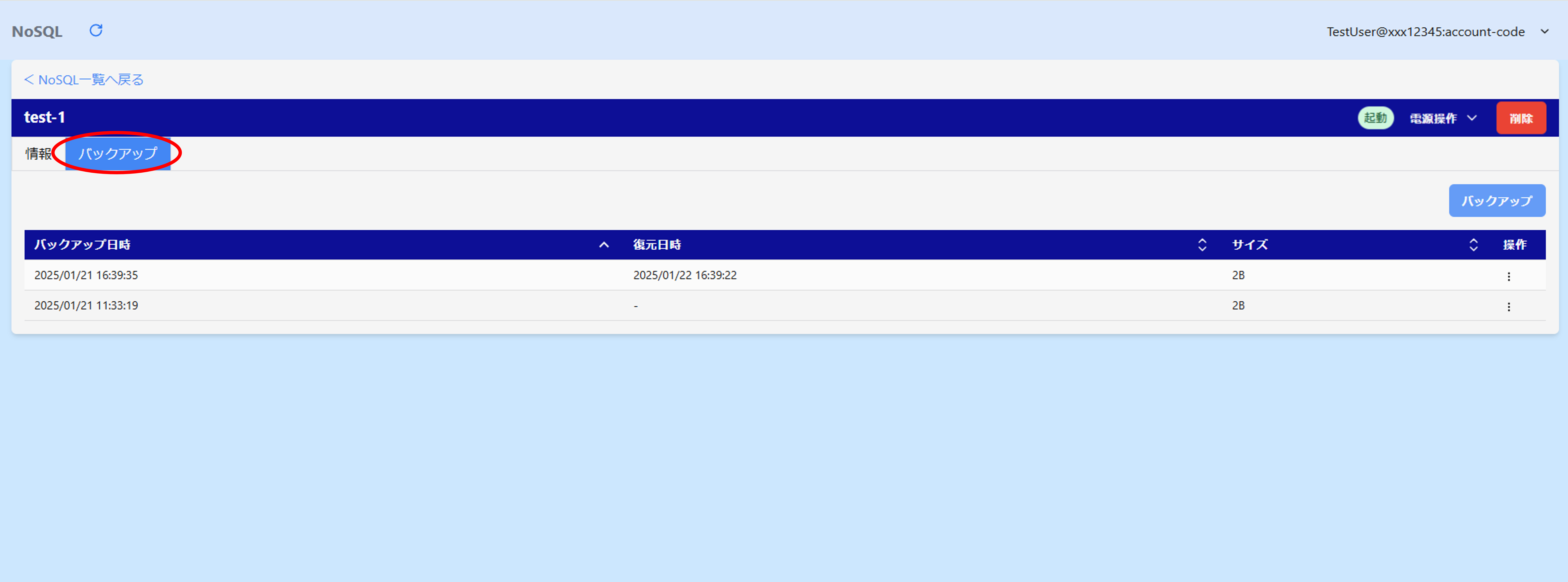
バックアップ機能の詳細については バックアップ の項目をご参照ください。
「パラメータ設定」タブ
設定可能なパラメータの一覧が確認できます。
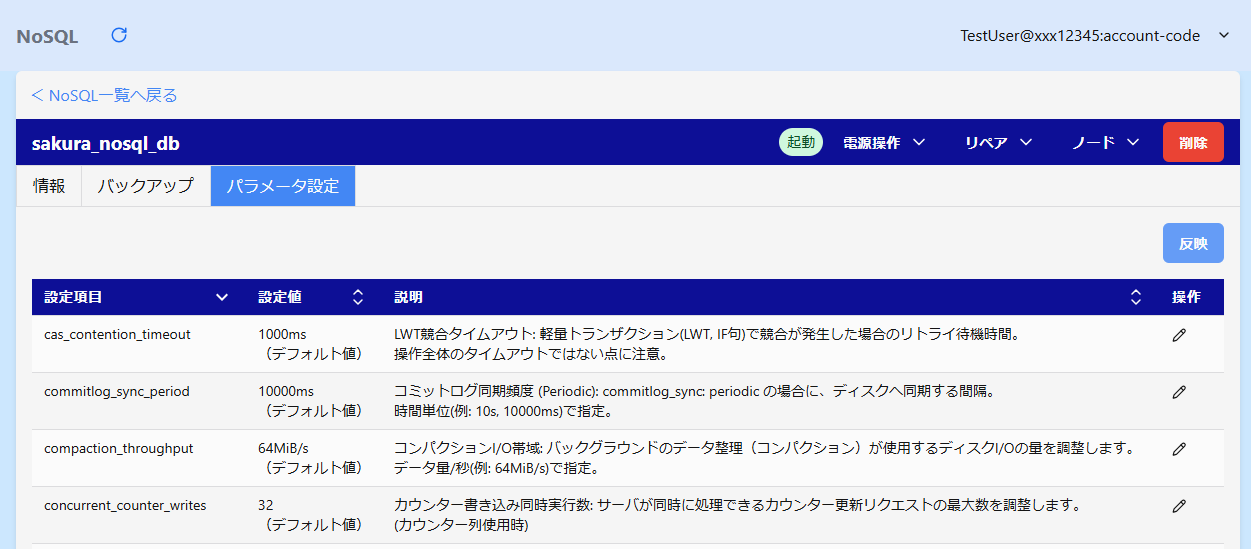
パラメータ設定機能の詳細については パラメータ設定 の項目をご参照ください。
「追加ノード」タブ
ノードを追加した場合、詳細画面に「追加ノード」タブが表示され、追加ノードの情報が確認できます。
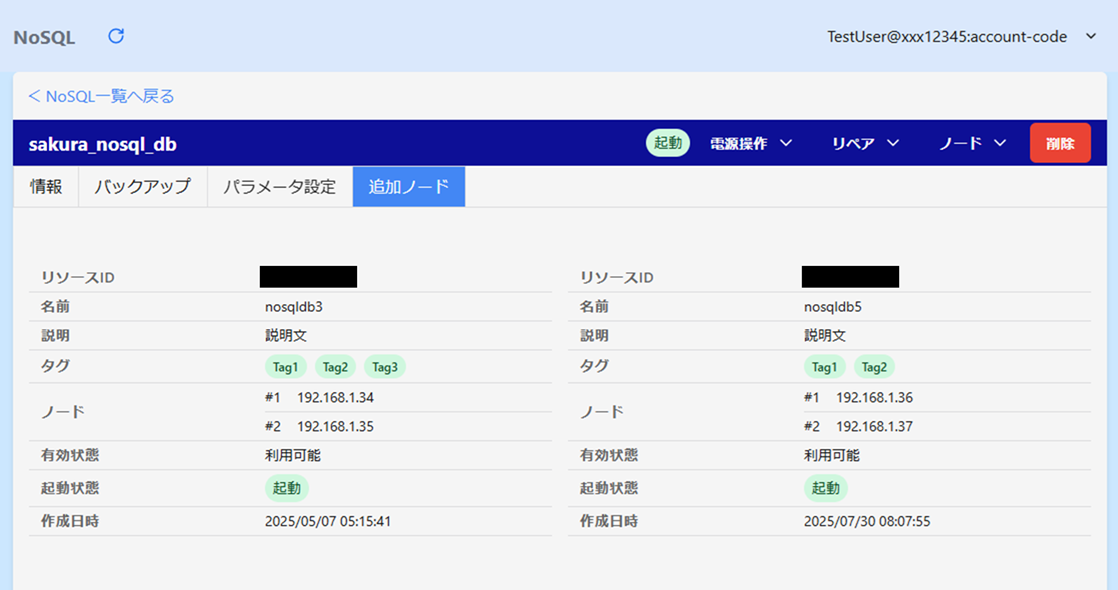
ノード追加機能の詳細については ノード追加 の項目をご参照ください。
電源操作
詳細画面の「電源操作」ボタンから、対象のデータベースに対して電源操作が行えます。
提供されている電源操作は以下の通りです。
操作 |
説明 |
|---|---|
起動 |
データベースを起動します |
停止 |
データベースを停止します |
再起動 |
一部のノードが停止している場合に、データベースを再起動します |
バックアップ
詳細画面の「バックアップ」タブにて、データベースのバックアップ操作が行えます。
提供されているバックアップ機能は以下の通りです。
操作 |
説明 |
|---|---|
バックアップ |
画面の右上の「バックアップ」ボタンより |
復元 |
バックアップ一覧の右端の操作メニューから「復元」をクリックすることで、 |
削除 |
バックアップ一覧の右端の操作メニューから「削除」をクリックすることで、 |
注釈
※データベース内に格納されているデータ量に応じて必要となる時間は変動します。
リペア
詳細画面の「リペア」ボタンから、リペアを実行できます。
即時リペアの実行
詳細画面の「リペア」ボタンをクリックし、「増分リペア」または「完全リペア」ボタンをクリックすることにより、リペアを実行できます。
パラメータ設定
詳細画面の「パラメータ設定」タブにて、パラメータの設定変更が行えます。
パラメータの編集
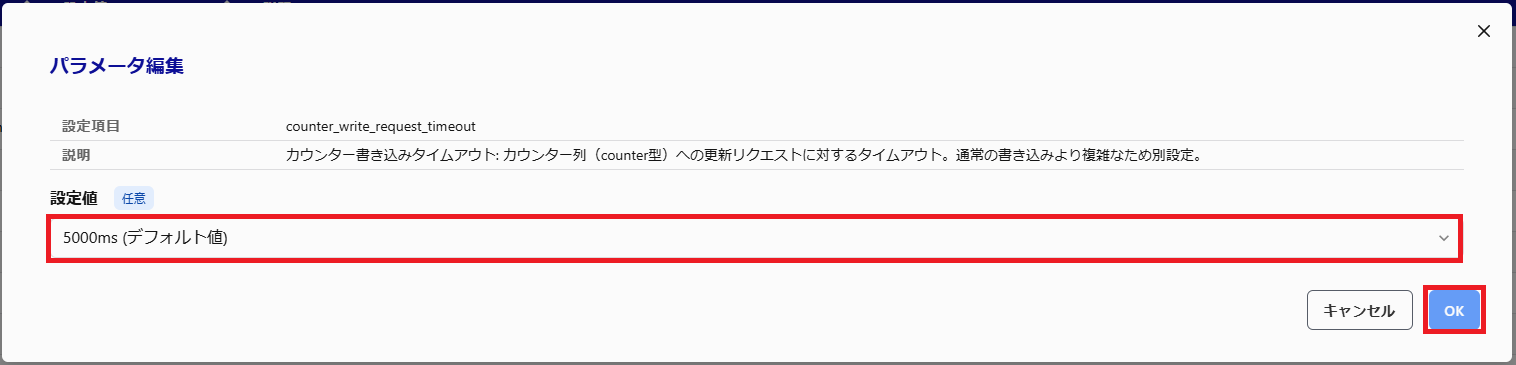
パラメータ一覧の右端の鉛筆アイコンをクリックします。
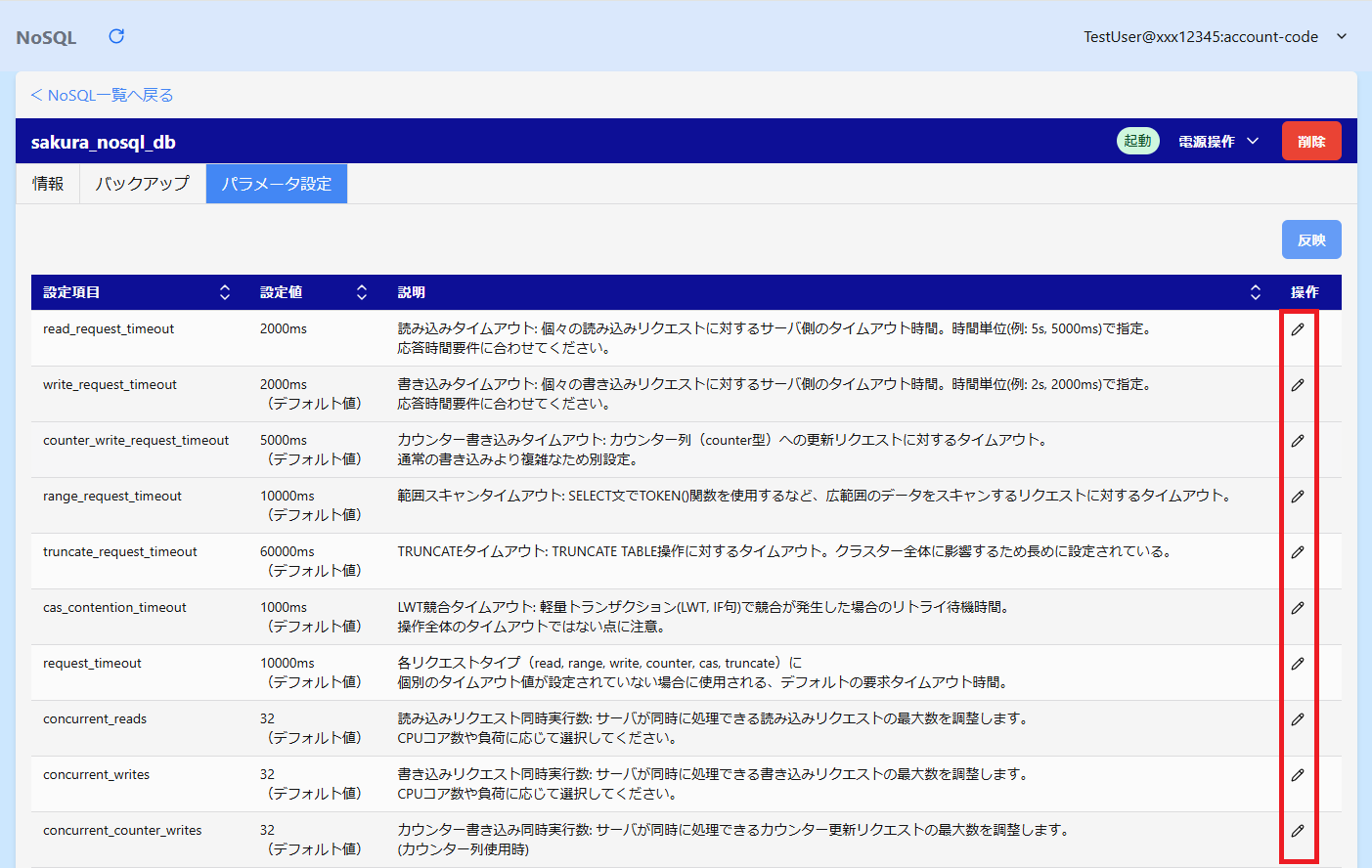
パラメータ編集ダイアログの設定値を選択し「OK」ボタンをクリックします。
パラメータの反映
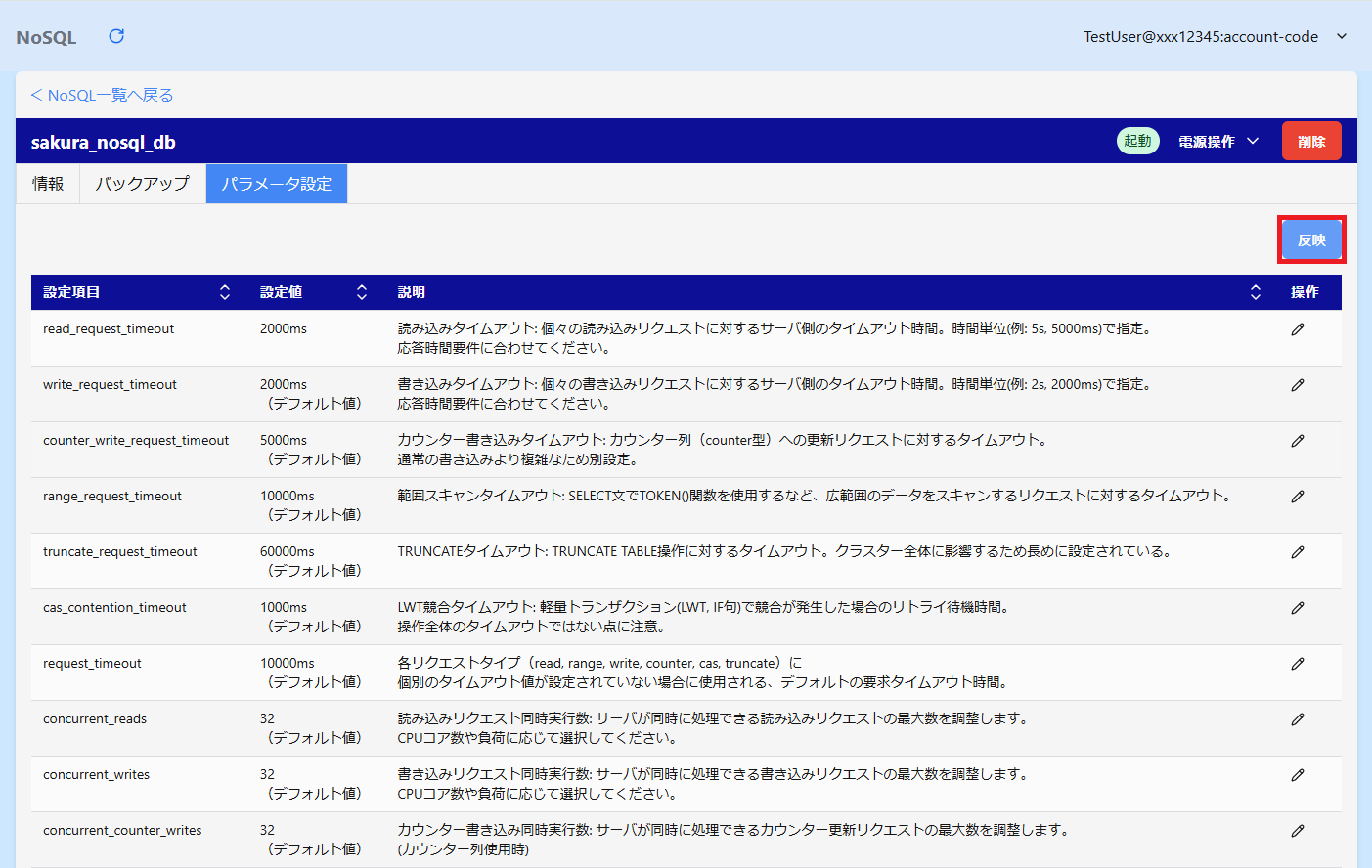
編集した設定をデータベースに反映させる必要があります。
パラメータ一覧画面の右上にある「反映」ボタンをクリックします。
各種パラメータの説明
No |
設定項目 |
項目名 |
説明 |
デフォルト値 |
選択肢 |
|---|---|---|---|---|---|
1 |
read_request_timeout |
読み込みリクエストタイムアウト |
秒数を長くすると低スペック環境/ディスク競合での遅延に対応しやすくなります。 |
5000ms |
5000ms / 10000ms / 15000ms / 20000ms |
2 |
write_request_timeout |
書き込みタイムアウト |
read_request_timeoutと同様の傾向が見られます。 |
2000ms |
2000ms / 3000ms / 6000ms / 8000ms |
3 |
counter_write_request_timeout |
カウンター書き込みタイムアウト |
秒数を長くすると、高負荷時やクラスタ通信遅延に対する耐性が向上し、処理の成功率が高まる可能性があります。 |
5000ms |
3000ms / 5000ms / 8000ms / 10000ms |
4 |
range_request_timeout |
範囲読み込みタイムアウト |
秒数を長くすると、低速なディスクや大規模データを扱う環境でもタイムアウトを回避しやすくなりますが、 |
10000ms |
5000ms / 10000ms / 20000ms / 30000ms |
5 |
truncate_request_timeout |
TRUNCATEリクエストタイムアウト |
値を長くすると、大規模なデータ削除処理が完了するまで待機する時間が長くなり、タイムアウトエラーの回避ができます。 |
60000ms |
30000ms / 60000ms / 90000ms / 120000ms |
6 |
cas_contention_timeout |
CAS競合タイムアウト |
秒数を長くすると、競合が発生した場合にタイムアウトまで待機する時間が長くなり、処理が成功する可能性が高くなります。 |
1000ms |
1000ms / 2000ms / 5000ms / 10000ms |
7 |
request_timeout |
リクエストタイムアウト |
秒数を長くすると、リクエストが完了するまで待機する時間が長くなり、低速なディスクや高負荷環境でもタイムアウトを回避しやすくなります。 |
10000ms |
10000ms / 15000ms / 20000ms / 30000ms |
8 |
concurrent_reads |
読み込みリクエスト同時実行数 |
値を大きくするとCPU/ディスクに余裕がある場合、スループット向上の可能性があります。 |
32 |
4 / 8 / 16 / 32 |
9 |
concurrent_writes |
書き込みリクエスト同時実行数 |
値を大きくするとCPU/ディスクに余裕がある場合、スループット向上の可能性があります。 |
32 |
4 / 8 / 16 / 32 |
10 |
concurrent_counter_writes |
カウンタ書き込みリクエスト同時実行数 |
concurrent_writesと同様の傾向があります。CPU(3コア)への負荷やディスクI/O競合リスクが高くなり、性能の低下やシステムの不安定になるリスクがあります。 |
32 |
4 / 8 / 16 / 32 |
11 |
compaction_throughput |
コンパクションI/O帯域 |
値を大きくするとコンパクション処理が迅速に進む傾向がありますが、CPU(3コア)への負荷が増加します。 |
32MiB/s |
16MiB/s / 32MiB/s / 64MiB/s |
12 |
memtable_heap_space |
Memtable最大サイズ |
値を大きくするとメモリ(8GB)が少ないため、JVMヒープが圧迫されやすくなり、GCの負荷が増す可能性があります。 |
512MiB |
512MiB / 1024MiB / 2048MiB |
13 |
commitlog_sync_period |
periodic用コミットログ同期頻度 |
値を短くすると耐久性が向上します。ただし、ディスクI/O競合が増加し、書き込みレイテンシが悪化する可能性があります。 |
10000ms |
15000ms / 10000ms / 5000ms |
ノード追加
詳細画面の「ノード」ボタンから、ノードの追加が行えます。
注釈
ノード数の上限は 9 としています。上限を超えるノードの追加はできません。
40GBプランでは、追加ノードの操作は行えません。
注意
新しいノードを追加する際には、通常運用時より多くのディスク容量を消費します。
空き容量が不足していると、データ移動や nodetool cleanup の実行中にエラーが発生するため、
ノード追加作業を行う前に、既存ノードで十分なディスク空き容量を確保しておく必要があります。
目安として、ディスク全体の 50% 以上の空き容量を確保しておくことを推奨します。
なお、各ノードのディスク使用状況は、モニタリングスイートのメトリクス基盤から確認できます。
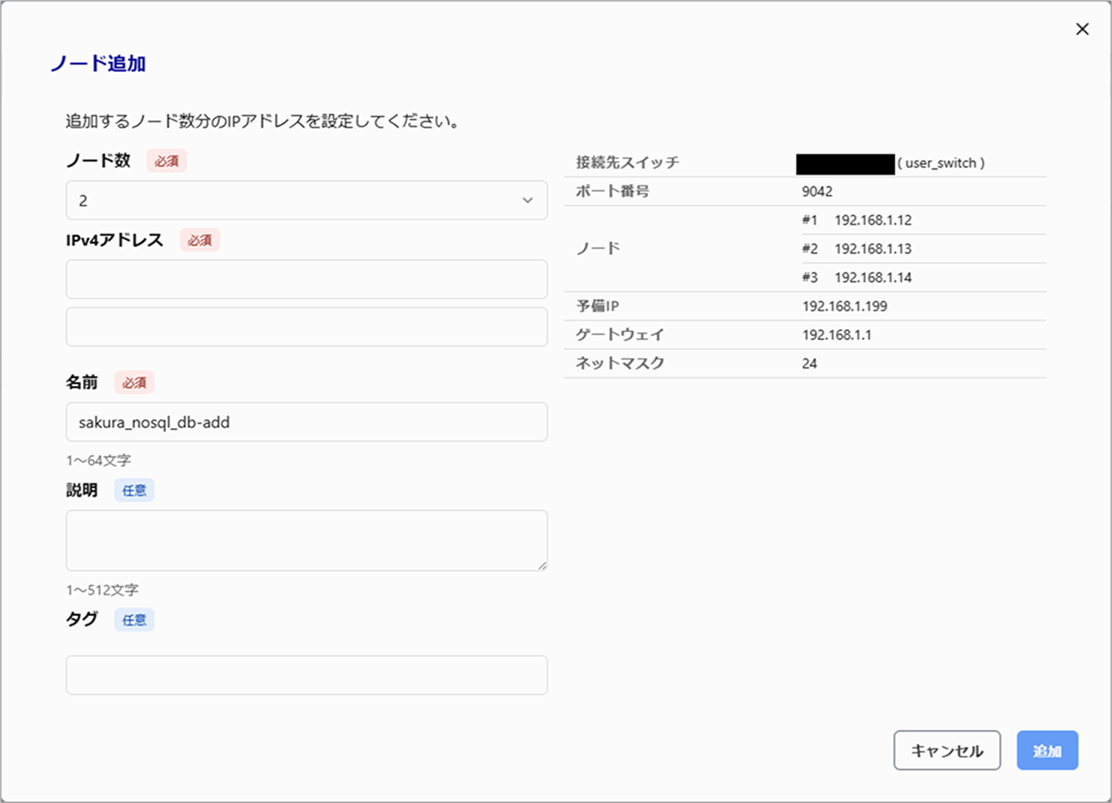
ノード追加ダイアログで必要な情報を入力し「追加」ボタンをクリックします。
確認メッセージが表示されるので、「追加」ボタンをクリックすると、ノード追加処理が開始されます。
追加後、詳細画面の「追加ノード」タブに追加したノードが表示されます。
注釈
データベース内に格納されているデータ量に応じて必要となる時間は変動します。
ノード追加中もCassandraの使用は可能です。
注意
現在、ノード追加を実施した場合、ノード追加前に取得したバックアップを復元することはできません。
ただし、ノード追加完了時に「バックアップ先」の設定がある場合はシステムが自動的にバックアップを取得します。復元が必要な場合は、このバックアップ以降に取得されたバックアップをご利用ください。
注意
現在、Cassandraクラスタにおける 追加ノードの削除には対応していません。
追加ノード単体の削除対応については、今後の開発にて対応予定です。
バージョンアップ
詳細画面「情報」タブの「バージョン確認」ボタンから、データベースのバージョンアップを行うことができます。
バージョン確認
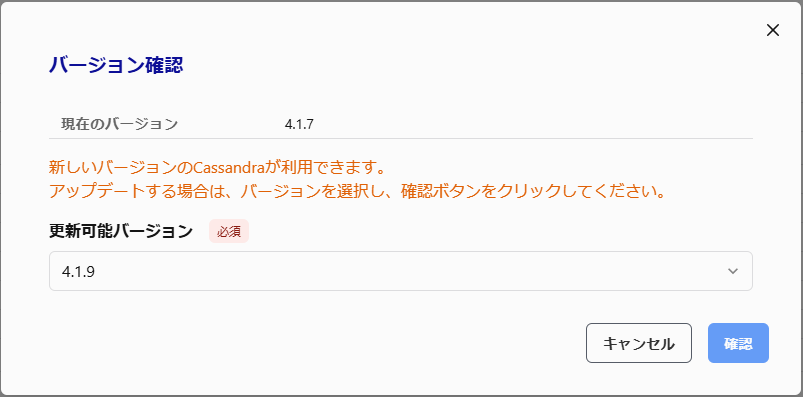
詳細画面「情報」タブの「バージョン確認」ボタンをクリックします。
※更新可能なバージョンがある場合のみ、表示されます。
バージョンアップ
バージョンを選択し「確認」ボタンをクリックします。
確認メッセージが表示されるので、内容を確認し「アップデート」ボタンをクリックします。
削除
詳細画面の「削除」ボタンより、データベースの削除を行うことができます。

APIの利用方法
NoSQL の設定は管理画面からのみでなく、API でも設定をすることが可能です。
認証
さくらのクラウド API は API キーとシークレットトークンを利用した Basic 認証または Digest 認証を使用します。 APIキーとシークレットトークンは、コントロールパネルの APIキー管理 で発行または確認できます。
OpenAPI仕様
詳しくは下記 OpenAPI 仕様ページをご覧ください。
NoSQL APIドキュメント – RESTful APIを利用した操作が可能
Cassandra
概要
Apache Cassandra(アパッチ・カサンドラ)は、スケーラビリティと高可用性を備えながらパフォーマンスを損なうことなく動作する、オープンソースの NoSQL 分散データベースです。
cqlsh コマンドを用いた Cassandra への接続
本サービスで作成したCassandraデータベースには、CQL(Cassandra Query Language)を使用して接続します。
ユーザは、データベース作成時に設定したIPアドレス、ポート、デフォルトユーザ名、パスワードを使用し、接続例に従って cqlsh コマンドを実行して接続してください。
接続例
cqlsh {ip} {port} --username={USERNAME} --password={PASSWORD}
例)cqlsh 192.168.1.100 9042 --username=example_user --password=example_pass
管理者ユーザの権限
権限名 |
権限についての説明 |
対象 |
|---|---|---|
CREATE |
データベース内で新しいオブジェクト(キー・スペース、テーブル、インデックス、ユーザ・ロールなど)を作成するための権限 |
ALL keyspaces |
ALTER |
既存のデータベースオブジェクト(テーブル、インデックス、キー・スペース、カラム・ファミリーなど)の構造や設定を変更するための権限 |
ALL keyspaces |
DROP |
既存のデータベースオブジェクト(テーブル、インデックス、キー・スペース、ユーザ・ロールなど)を削除するための権限 |
ALL keyspaces |
SELECT |
指定されたデータベースオブジェクト(テーブル、ビュー、カラムファミリーなど)からデータを読み取るための権限 |
ALL keyspaces |
MODIFY |
ユーザがデータの挿入(INSERT)、更新(UPDATE)、削除(DELETE)など、テーブルのデータに対する変更を行うための権限 |
ALL keyspaces |
AUTHORIZE |
ユーザまたはロールに対して、他のユーザやロールの権限を付与・取り消しするための権限 |
ALL keyspaces |
DESCRIBE |
データベース内のスキーマに関する情報を取得するための権限 |
ALL ROLES |
EXECUTE |
ユーザ定義関数(UDF: User Defined Function)やユーザ定義集計関数(UDA: User Defined Aggregation)の実行を許可する権限 |
ALL FUNCTIONS |
モニタリングスイート連携機能
NoSQLのメトリクス一覧やモニタリング機能を説明します。
詳しい内容や設定は モニタリングスイートのマニュアル をご覧ください。